
1. ⛳️ 实战场景
前段时间,悦创发过一篇博客《Python 千猫图,简单技术满足你的收集控》,结果发出来没多久,大家的热情就把人家的网站给弄的苦不堪言,然后加上了参数加密,也就是反爬了。
作为一个对自己博客可用性非常上新的作者,我必须让爬虫再次运行起来,所以本篇博客就为你带来这个站点的反反爬途径。
问题
很多朋友反馈的是第一步就无法获取列表数据了,我们先看一下这个地方。
原代码简化之后,如下所示:
原创2023/5/2...大约 4 分钟
前段时间,悦创发过一篇博客《Python 千猫图,简单技术满足你的收集控》,结果发出来没多久,大家的热情就把人家的网站给弄的苦不堪言,然后加上了参数加密,也就是反爬了。
作为一个对自己博客可用性非常上新的作者,我必须让爬虫再次运行起来,所以本篇博客就为你带来这个站点的反反爬途径。
问题
很多朋友反馈的是第一步就无法获取列表数据了,我们先看一下这个地方。
原代码简化之后,如下所示:
爬取目标
使用框架
重点学习内容
页面变化
详情页所在源码位置
你好,我悦创。
上一篇文章中有朋友说,为什么不用 BS4(一款爬虫解析框架)?答:会使用的,还没到时间。
爬虫 800 例系列教程,每篇博客都是一个实操案例,整个学习过程是循序渐进的,在初期阶段,我们将使用 requests 库与 re 模块进行爬虫编写。
而且,为了让课程更加有趣,我们将在爬美图的路上停留一段时间。
所以看到本文的朋友,可以点赞、收藏、关注啦。
你好,我悦创。
一切的起点,10 行代码集美女
正式编写爬虫学习前,以下内容先搞定:
你好,我是悦创。
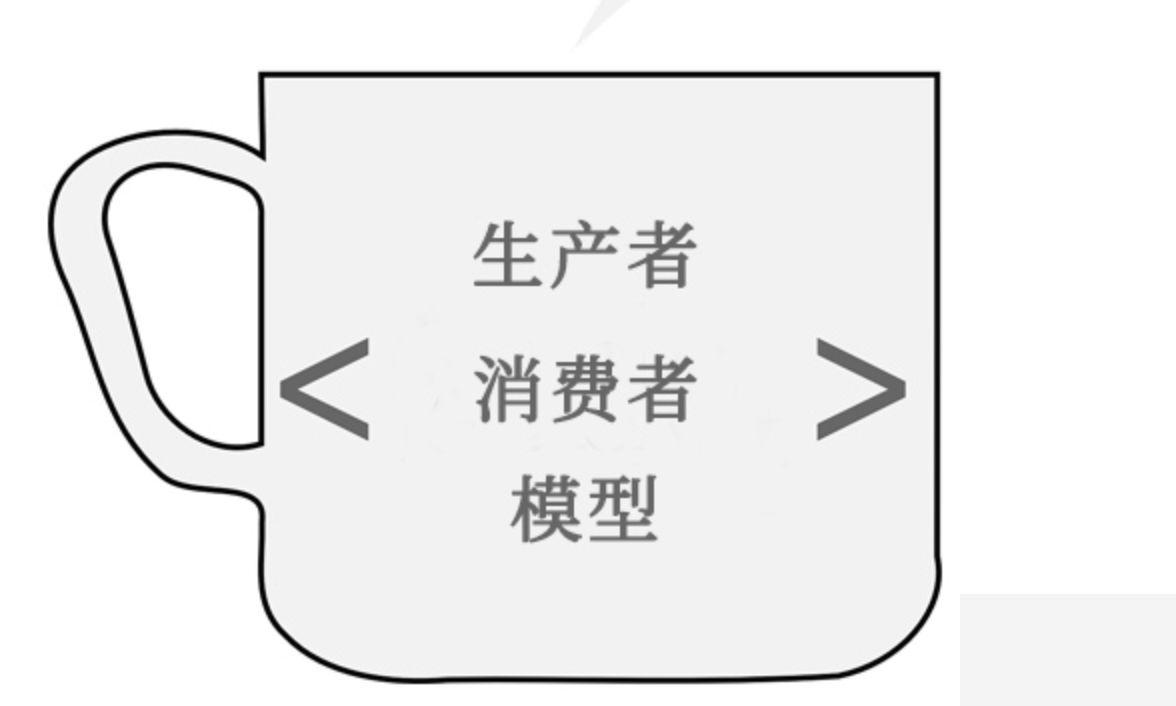
对于比较大型的爬虫来说,URL 管理的管理是个核心问题,管理不好,就可能重复下载,也可能遗漏下载。这里,我们设计一个 URL Pool 来管理 URL。
这个 URL Pool 就是一个生产者-消费者模式:
你好,我是悦创。
公众号:AI悦创,之后其余篇只会在微信公众号和博客发布!
公众号原文:https://mp.weixin.qq.com/s/UQwRJ28FCbVJ0VYpYjcvhw
好久没来更新公众号了,也感谢各位的陪伴。本篇也将开启我自己啃代理池的心得,将逐步放送,因为代理池搭建较为复杂,这里我就尽可能把代理池分成几篇来讲,同时也保证,在我其他篇放出来之前,每一篇都是你们的新知识。
你好,我是悦创。
上一课时我们学习了 Ajax 的基本原理和分析方法,这一课时我们结合实际案例,学习 Ajax 分析和爬取页面的具体实现。
在开始学习之前,我们需要做好如下的准备工作:
安装好 Python 3(最低为 3.6 版本),并能成功运行 Python 3 程序。
了解 Python HTTP 请求库 requests 的基本用法。
了解 Ajax 的基础知识和分析 Ajax 的基本方法。
数据库是“按照数据结构来组织、存储和管理数据的仓库”,是一个长期存储在计算机内的、有组织的、有共享的、统一管理的数据集合。
数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合,可视为电子化的文件柜。
大型数据库:甲骨文Oracle。
你好,我是悦创。
待更新~

你好,我是悦创。
待更新~
你好,我是悦创。
待更新~
你好,我是悦创。
当我们在用 requests 抓取页面的时候,得到的结果可能会和在浏览器中看到的不一样:在浏览器中正常显示的页面数据,使用 requests 却没有得到结果。这是因为 requests 获取的都是原始 HTML 文档,而浏览器中的页面则是经过 JavaScript 数据处理后生成的结果。这些数据的来源有多种,可能是通过 Ajax 加载的,可能是包含在 HTML 文档中的,也可能是经过 JavaScript 和特定算法计算后生成的。
对于第 1 种情况,数据加载是一种异步加载方式,原始页面不会包含某些数据,只有在加载完后,才会向服务器请求某个接口获取数据,然后数据才被处理从而呈现到网页上,这个过程实际上就是向服务器接口发送了一个 Ajax 请求。
你好,我是悦创。
在上一课时我们介绍了异步爬虫的基本原理和 asyncio 的基本用法,另外在最后简单提及了 aiohttp 实现网页爬取的过程,这一课是我们来介绍一下 aiohttp 的常见用法,以及通过一个实战案例来介绍下使用 aiohttp 完成网页异步爬取的过程。
前面介绍的 asyncio 模块内部实现了对 TCP、UDP、SSL 协议的异步操作,但是对于 HTTP 请求的异步操作来说,我们就需要用到 aiohttp 来实现了。
aiohttp 是一个基于 asyncio 的异步 HTTP 网络模块,它既提供了服务端,又提供了客户端。其中我们用服务端可以搭建一个支持异步处理的服务器,用于处理请求并返回响应,类似于 Django、Flask、Tornado 等一些 Web 服务器。而客户端我们就可以用来发起请求,就类似于 requests 来发起一个 HTTP 请求然后获得响应,但 requests 发起的是同步的网络请求,而 aiohttp 则发起的是异步的。
你好,我是悦创。
上一节我们实现了一个简单的再也不能简单的新闻爬虫,这个爬虫有很多槽点,估计大家也会鄙视这个爬虫。上一节最后我们讨论了这些槽点,现在我们就来去除这些槽点来完善我们的新闻爬虫。
问题我们前面已经描述清楚,解决的方法也有了,那就废话不多讲,代码立刻上(Talk is cheap, show me the code!)。

你好,我是悦创。
这个实战例子是构建一个大规模的异步新闻爬虫,但要分几步走,从简单到复杂,循序渐进的来构建这个 Python 爬虫。
要抓取新闻,首先得有新闻源,也就是抓取的目标网站。
国内的新闻网站,从中央到地方,从综合到垂直行业,大大小小有几千家新闻网站。百度新闻(https://news.baidu.com/)收录的大约两千多家。那么我们先从百度新闻入手。
打开百度新闻的网站首页:https://news.baidu.com/
原名
Python 之站在高层框架下的 SQLAIchemy 操作 MySQL(关系型数据库)
下载方法
你好,我是悦创。
你以前是不是有这些问题?
我想以上的问题或多或少你在有些迷茫,或不是很理解。接下来就带你进入 BeautifulSoup 库的基础操作。
这里为了照顾绝大多数的零基础或者基础不扎实的童鞋,我主要讲解 BeautifulSoup 库基础操作,纳尼 (⊙o⊙)?不讲上面几点?别急,上面的几个问题我会简单地回答,之后的 专栏 会分享给大家的,欢迎持续关注!
你好,我是悦创。
吐槽
这篇博客的产生是因为本人被 MongoDB 的安装坑了几次,为避免各位朋友在同一个地方踩坑,下面我会详细的讲解说明我的安装步骤。本人的电脑是 Window10 系统,如果系统和我相同保证你安装成功。
说明
我用的是 brew 进行安装,且输入:
mongosh正常响应。如果你使用其他方法,且成功了,记得留言,这样可以为后来者铺路。有问题也可以留言讨论!