
10-多个站点同时抓取!怎么做到的?
你好,我是悦创。
公众号:AI悦创,之后其余篇只会在微信公众号和博客发布!
公众号原文:https://mp.weixin.qq.com/s/UQwRJ28FCbVJ0VYpYjcvhw
好久没来更新公众号了,也感谢各位的陪伴。本篇也将开启我自己啃代理池的心得,将逐步放送,因为代理池搭建较为复杂,这里我就尽可能把代理池分成几篇来讲,同时也保证,在我其他篇放出来之前,每一篇都是你们的新知识。
学习就像看小说一样,一次一篇就会显得额外的轻松!
当你把学习当作某个娱乐的事情来做,你会发现不一样的世界!
我们无法延长生命长度,但是我们延长生命宽度,学习编程就是扩展生命最有力的武器!
1. 看完之后你会得到什么
- 返回 yield;
- eval 的使用;
- 多个代理网站同时抓取;
- 使用异步测试代理是否可用;
- Python 的元类编程简单介绍;
- 正则表达式、PyQuery 提取数据;
- 模块化编程;
废话不多说,马上步入正题!
2. 你需要的准备
在学习本篇文章时,希望你已经具备如下技能或者知识点:
- Python 环境(推荐 Python 3.7+);
- Python 爬虫常用库;
- Python 基本语法;
- 面向对象编程;
- yield、eval 的使用;
- 模块化编程;
3. 课前预习知识点
对于代理池的搭建呢,虽然我已经尽可能地照顾到绝大多数地小白,把代理地的搭建呢,进行了拆分,不过对于培训机构或者自学不是特别精进的小伙伴来说还是有些难度的,对于这些呢?我这里也给大家准备了知识点的扫盲。以下内容节选自我个人博客文章,这里为了扫盲就提供必要部分,想看完整的文章可以点击此链接:https://www.aiyc.top/archives/605.html
3.1 Python 的元类编程
你好,我是悦创。
好久不见,最近在啃数学、Java、英语没有来更新公众号,那么今天就来更新一下啦!
又到了每日一啃,啃代码的小悦。今天我遇到了 Python 原类,然而我啥也不懂。只能靠百度和谷歌了,主要还是用谷歌来查啦,百度前几条永远是广告准确度也不行(个人观点),也顺便参考了几个博客:廖雪峰网站,添加了一点自己的观点和理解。
3.1.1 type()
动态语言和静态语言最大的不同,就是函数和类的定义,不是编译时定义的,而是运行时动态创建的。
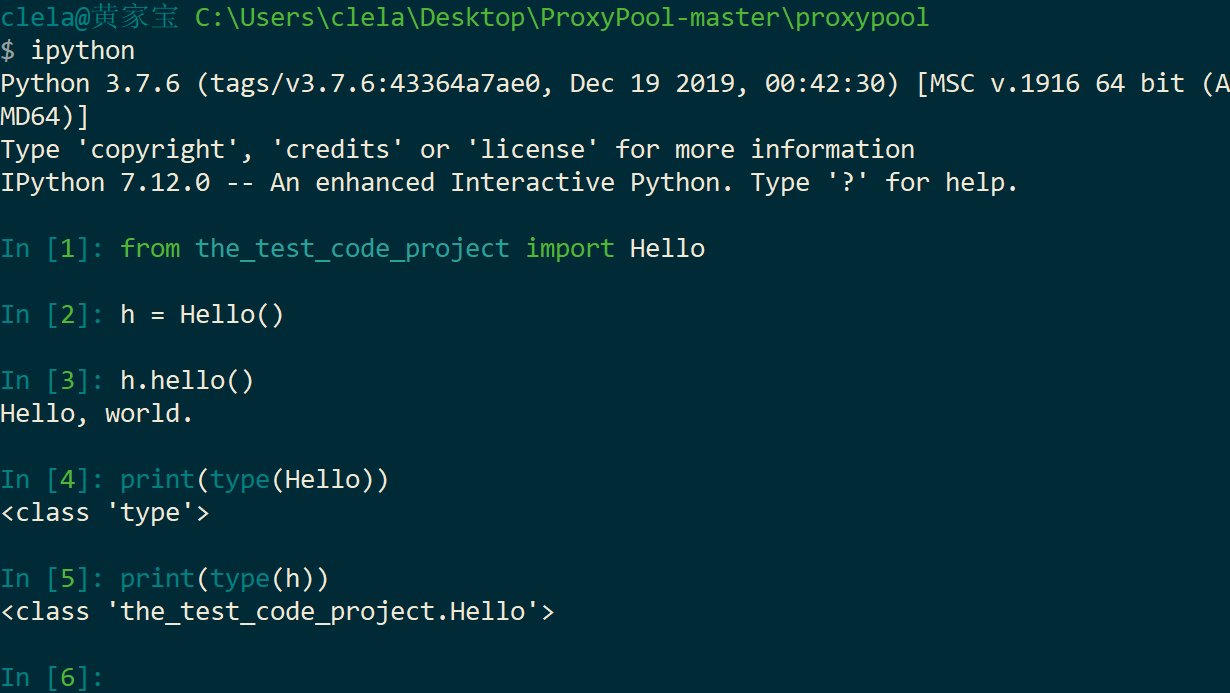
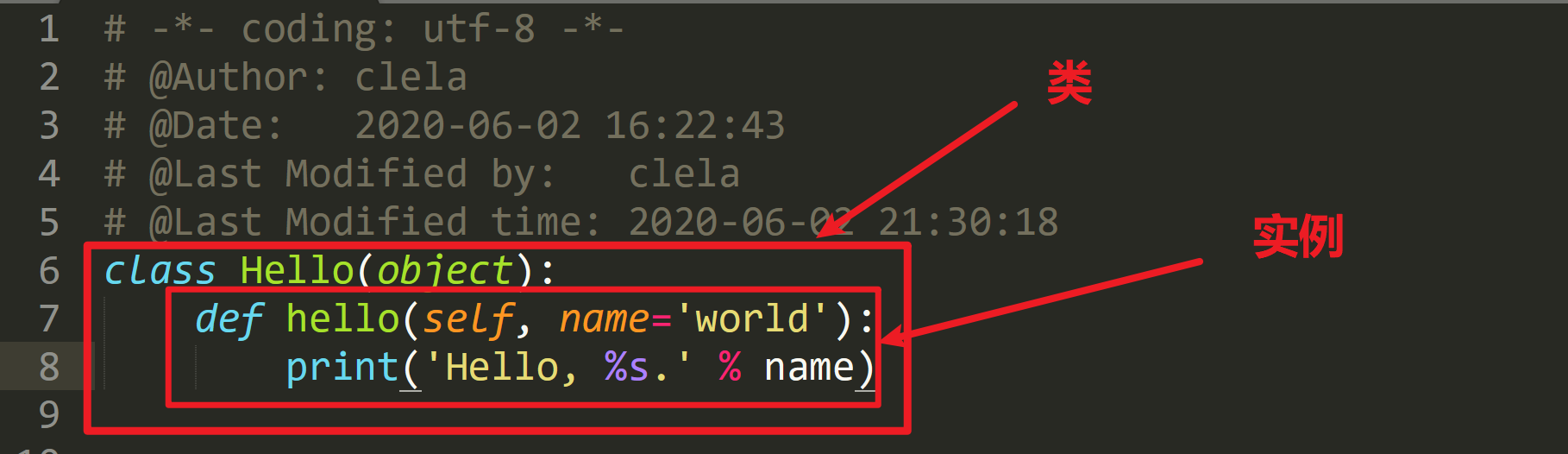
比方说我们要定义一个 Hello 的 class,就写一个 hello.py 模块(这里我实际创建的是:the_test_code_project.py 模块):
class Hello(object):
def hello(self, name='world'):
print('Hello, %s.' % name)当 Python 解释器载入 hello 模块时,就会依次执行该模块的所有语句,执行结果就是动态创建出一个 Hello 的 class 对象,测试如下:
if __name__ == '__main__':
h = Hello()
h.hello()
print(type(Hello))
print(type(h))运行结果如下:
Hello, world.
<class 'type'>
<class '__main__.Hello'>其中,上面的输出结果:__main__.Hello 等价于 <class 'the_test_code_project.Hello'> 运行的方式不同显示的方式也不同,但含义是一样的。
type() 函数可以查看一个类型或变量的类型,为了让小白更轻松,我也写了个例子:
number = 12
string = 'Hello AIYC!'
float_number = 12.1
list_data = [1, '2', 3.5, 'AIYC'] # 可变
tuples = (1, '2', 3.5, 'AIYC') # 不可变
if __name__ == '__main__':
print(type(number))
print(type(string))
print(type(float_number))
print(type(list_data))
print(type(tuples))运行结果:
<class 'int'>
<class 'str'>
<class 'float'>
<class 'list'>
<class 'tuple'>Hello 是一个 class,它的类型就是 type ,而 h 是一个实例,它的类型就是class Hello。
我们说 class 的定义是运行时动态创建的,而创建 class 的方法就是使用 type() 函数。
type() 函数既可以返回一个对象的类型,又可以创建出新的类型,比如,我们可以通过 type() 函数创建出Hello 类,而无需通过 class Hello(object)... 的定义:
def fn(self, name='world'): # 先定义函数
print('Hello, %s.' % name)
Hello = type('Hello', (object,), dict(hello=fn)) # 创建 Hello class
# Hello = type('Class_Name', (object,), dict(hello=fn)) # 创建 Hello class
# type(类名, 父类的元组(针对继承的情况,可以为空),包含属性的字典(名称和值))我们接下来来调用一下代码,看输出的结果如何:
if __name__ == '__main__':
h = Hello()
h.hello()
print(type(Hello))
print(type(h))这里推荐写成:if __name__ == '__main__': 使代码更加的规范。
运行结果:
Hello, world.
<class 'type'>
<class '__main__.Hello'>要创建一个 class 对象,type() 函数依次传入 3 个参数:
- class 的名称;
- 继承的父类集合,注意 Python 支持多重继承,如果只有一个父类,别忘了 tuple 的单元素写法;(这个个 tuple 单元素写法起初本人不太理解,然后一查并认真观察了一下上面的代码就想起来 tuple 单元素写法需要加逗号(,),就是你必须这么写:
tuple_1 = (1,)而不能这么写:tuple_2 = (1),tuple_2 = (1)的写法,Python 会自动认为是一个整数而不是一个元组) - class 的方法名称与函数绑定,这里我们把函数
fn绑定到方法名hello上。
通过 type() 函数创建的类和直接写 class 是完全一样的,因为 Python 解释器遇到 class 定义时,仅仅是扫描一下 class 定义的语法,然后调用 type() 函数创建出 class。(直接 Class 创建也是)
正常情况下,我们都用 class Xxx... 来定义类,但是,type() 函数也允许我们动态创建出类来,也就是说,动态语言本身支持运行期动态创建类,这和静态语言有非常大的不同,要在静态语言运行期创建类,必须构造源代码字符串再调用编译器,或者借助一些工具生成字节码实现,本质上都是动态编译,会非常复杂。
3.1.2 metaclass
除了使用 type() 动态创建类以外,要控制类的 创建行为 ,还可以使用 metaclass。
metaclass,直译为元类,简单的解释就是:
当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
但是如果我们想创建出类呢?
那就必须根据 metaclass 创建出类,所以:先定义 metaclass ,然后创建类。连接起来就是:先定义 metaclass ,就可以创建类,最后创建实例。
所以,metaclass 允许你创建类或者修改类 。换句话说,你可以把类看成是 metaclass 创建出来的“实例”。
metaclass 是 Python 面向对象里最难理解,也是最难使用的魔术代码。正常情况下,你不会碰到需要使用metaclass的情况,所以,以下内容看不懂也没关系,因为基本上你不会用到。(然而还是被我遇见了,而且还是看不懂,但经过大佬的指点就只是知道如何使用,但并不了解其中的原理,所以才有了此篇。)
我们先看一个简单的例子,这个 metaclass 可以给我们自定义的 MyList 增加一个 add 方法:
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['add'] = lambda self, value: self.append(value) # 加上新的方法
return type.__new__(cls, name, bases, attrs) # 返回修改后的定义定义
ListMetaclass,按照默认习惯,metaclass 的类名总是以 Metaclass 结尾,以便清楚地表示这是一个metaclass 。
有了 ListMetaclass ,我们在定义类的时候还要指示使用 ListMetaclass 来定制类,传入关键字参数 metaclass :
class MyList(list, metaclass=ListMetaclass):
pass当我们传入关键字参数 metaclass 时,魔术就生效了,它指示 Python 解释器在创建 MyList 时,要通过ListMetaclass.__new__() 来创建,在此,我们可以修改类的定义,比如,加上新的方法,然后,返回修改后的定义。
__new__() 方法接收到的参数依次是:
- 当前准备创建的类的对象;
- 类的名字;
- 类继承的父类集合;
- 类的方法集合。
测试一下 MyList 是否可以调用 add() 方法:
L = MyList()
L.add(1)
print(L)
# 输出
[1]而普通的 list 没有 add() 方法:
>>> L2 = list()
>>> L2.add(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'add'这时候,我想你应该和我会有同样的问题,动态修改有什么意义?
直接在 MyList 定义中写上 add() 方法不是更简单吗?
正常情况下,确实应该直接写,我觉得通过 metaclass 修改纯属变态。
3.2 Python eval() 函数
对于 Python 的 eval 呢,大部分人是这么定义的:eval() 函数用来执行一个字符串表达式,并返回表达式的值。
这句话,有可能对于新手来说并不是非常好理解,我们还是用例子来顿悟一下吧。
以下是 eval() 方法的语法:
eval(expression[, globals[, locals]])参数
- expression -- 表达式。
- globals -- 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
返回值
返回表达式计算结果。
实际操作
In [3]: x = 7
In [4]: eval( '3 * x' )
Out[4]: 21
In [5]: eval('pow(2,2)')
Out[5]: 4
In [6]: eval('2 + 2')
Out[6]: 4
In [7]: n=81
In [8]: eval("n + 4")
Out[8]: 85再来个函数的操作:
In [1]: str1 = "print('Hello World')"
In [2]: eval(str1)
Hello Worldok,到此零基础小白关怀文章就完成了,我就不继续赘述啦!
看到这里,你们的身体还行吗?

我正在的干货要开始了!
进入我们的 show time 环节,起飞了、起飞了,做好准备了!
4. 抓取免费代理
这里呢,我就不再带带大家手摸手的教学如何抓取代理了,因为当你能看这篇文章时,相信你已经对爬虫是有所入门了,如果还没入门的小伙伴可以关注本公众号,往期文章也有零基础教学和基础的课程资源,可以公众号后台回复:Python爬虫。即可获取资源,如果失效也别担心加小悦好友即可!(资源多多噢!)
小白不建议报名培训机构,毕竟现在培训结构收智商税比较多,还是需要多多鉴别噢!
4.1 目标的代理网站
- 快代理:https://www.kuaidaili.com/
- 西刺代理:https://www.xicidaili.com
- 66代理:http://www.66ip.cn/
- 无忧代理:http://www.data5u.com
- 开心代理-高匿:http://www.kxdaili.com/dailiip/
- 云代理:http://www.ip3366.net/free/
对于每个网站的代码呢,具体实现也是比较简单的,这里我就不做过多的赘述啦!
接下来我都直接上代码,不过在上代理的爬虫代码前,我们需要来写个元类,代码如下:
class ProxyMetaclass(type):
"""
定义 ProxyMetaclass ,按照默认习惯,metaclass 的类名总是以 Metaclass 结尾,以便清楚地表示这是一个metaclass :
元类,在 FreeProxyGetter 类中加入
CrawlFunc_list 和 CrawlFuncCount
两个参数,分别表示爬虫函数,和爬虫函数的数量。
"""
def __new__(cls, name, bases, attrs):
count = 0
attrs['CrawlFunc_List'] = [] # 添加:CrawlFunc_List 列表方法
for k, v in attrs.items():
if 'crawl_' in k:
# 判断这个函数里面是否携带 crawl_ 也就是利用 value in xxx
attrs['CrawlFunc_List'].append(k)
count += 1
attrs['CrawlFuncCount'] = count # 检测添加的函数的总数量
return type.__new__(cls, name, bases, attrs) # 返回所修改的详细的代码含义,已经写在上面了,具体的这里 就不赘述了,如果泥有任何不理解的可以去点击阅读原文在我的博客网站下留言,和后台回复数字“3”,加小编好友,拉你入交流群。
4.2 代码编写
4.2.1 请求函数编写
单独保存成一个文件:utils.py
"""
project = 'Code', file_name = 'utils.py', author = 'AI悦创'
time = '2020/6/1 12:34', product_name = PyCharm, 公众号:AI悦创
code is far away from bugs with the god animal protecting
I love animals. They taste delicious.
"""
import requests
import asyncio
import aiohttp
from requests.exceptions import ConnectionError
from fake_useragent import UserAgent,FakeUserAgentError
import random
def get_page(url, options={}):
"""
构造随机请求头,如果不理解的可以阅读此文章:
两行代码设置 Scrapy UserAgent:https://www.aiyc.top/archives/533.html
"""
try:
ua = UserAgent()
except FakeUserAgentError:
pass
# 生成随机的请求头,加 try...except... 使代码更加健壮
base_headers = {
'User-Agent': ua.random,
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8'
}
# 如果使用者有传入请求头,则将此请求头和随机生成的合成在一起
headers = dict(base_headers, **options)
# 当前请求的 url
print('Getting', url)
try:
r = requests.get(url, headers=headers)
print('Getting result', url, r.status_code)
if r.status_code == 200:
return r.text
return None
except ConnectionError:
print('Crawling Failed', url)
return None
class Downloader(object):
"""
一个异步下载器,可以对代理源异步抓取,但是容易被 BAN。
self._htmls: 把请求的 html 放入列表当中
升级版的请求类
"""
def __init__(self, urls):
self.urls = urls
self._htmls = []
async def download_single_page(self, url):
"""
下载单页
"""
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
self._htmls.append(await response.text())
def download(self):
loop = asyncio.get_event_loop()
tasks = [self.download_single_page(url) for url in self.urls]
loop.run_until_complete(asyncio.wait(tasks))
@property
def htmls(self):
self.download()
return self._htmls上面请求函数编写完成之后,我们就需要在抓取代理的代码文件中,进行导包,代码如下:
# files:Spider.py
from utils import get_page5. 代理抓取代码
导入所需要的库:
import requests
from utils import get_page
from pyquery import PyQuery as pq
import re接下来我们需要创建一个类 FreeProxyGetter 并使用元类创建。
class FreeProxyGetter(object, metaclass=ProxyMetaclass):
pass1. 快代理
def crawl_kuaidaili(self):
"""
快代理
:return:
"""
for page in range(1, 4):
# 国内高匿代理
start_url = 'https://www.kuaidaili.com/free/inha/{}/'.format(page)
html = get_page(start_url)
# print(html)
pattern = re.compile(
'<td data-title="IP">(.*)</td>\s*<td data-title="PORT">(\w+)</td>'
)
# \s * 匹配空格,起到换行作用
# ip_addres = re.findall(pattern, html) # 写法一
ip_addres = pattern.findall(str(html))
for adress, port in ip_addres:
# print(adress, port)
result = f"{adress}:{port}".strip()
yield result2. 西刺代理
def crawl_xicidaili(self):
"""
西刺代理
:return:
"""
for page in range(1, 4):
start_url = 'https://www.xicidaili.com/wt/{}'.format(page)
html = get_page(start_url)
# print(html)
ip_adress = re.compile(
'<td class="country"><img src="//fs.xicidaili.com/images/flag/cn.png" alt="Cn" /></td>\s*<td>(.*?)</td>\s*<td>(.*?)</td>'
)
# \s* 匹配空格,起到换行作用
re_ip_adress = ip_adress.findall(str(html))
for adress, port in re_ip_adress:
result = f"{adress}:{port}".strip()
yield result3. 66代理
def crawl_daili66(self, page_count=4):
"""
66代理
:param page_count:
:return:
"""
start_url = 'http://www.66ip.cn/{}.html'
urls = [start_url.format(page) for page in range(1, page_count + 1)]
for url in urls:
print('Crawling', url)
html = get_page(url)
if html:
doc = pq(html)
trs = doc('.containerbox table tr:gt(0)').items()
for tr in trs:
ip = tr.find('td:nth-child(1)').text()
port = tr.find('td:nth-child(2)').text()
yield ':'.join([ip, port])4. 无忧代理
def crawl_data5u(self):
"""
无忧代理
:return:
"""
start_url = 'http://www.data5u.com'
html = get_page(start_url)
# print(html)
ip_adress = re.compile(
'<ul class="l2">\s*<span><li>(.*?)</li></span>\s*<span style="width: 100px;"><li class=".*">(.*?)</li></span>'
)
# \s * 匹配空格,起到换行作用
re_ip_adress = ip_adress.findall(str(html))
for adress, port in re_ip_adress:
result = f"{adress}:{port}"
yield result.strip()5. 开心代理-高匿
def crawl_kxdaili(self):
"""
开心代理-高匿
:return:
"""
for i in range(1, 4):
start_url = 'http://www.kxdaili.com/dailiip/1/{}.html'.format(i)
try:
html = requests.get(start_url)
if html.status_code == 200:
html.encoding = 'utf-8'
# print(html.text)
ip_adress = re.compile('<tr.*?>\s*<td>(.*?)</td>\s*<td>(.*?)</td>')
# \s* 匹配空格,起到换行作用
re_ip_adress = ip_adress.findall(str(html.text))
for adress, port in re_ip_adress:
result = f"{adress}:{port}"
yield result.strip()
return None
except:
pass6. 云代理
def IP3366Crawler(self):
"""
云代理
parse html file to get proxies
:return:
"""
start_url = 'http://www.ip3366.net/free/?stype=1&page={page}'
urls = [start_url.format(page=i) for i in range(1, 8)]
# \s * 匹配空格,起到换行作用
ip_address = re.compile('<tr>\s*<td>(.*?)</td>\s*<td>(.*?)</td>')
for url in urls:
html = get_page(url)
re_ip_address = ip_address.findall(str(html))
for adress, port in re_ip_address:
result = f"{adress}:{port}"
yield result.strip()至此,代理网站的代码已经全部编写完成,接下来我们需要了解的是然后调用此类,直接调用吗?
显然不是,我们还需要编写一个运行调用的函数,代码如下:
def run(self):
# print(self.__CrawlFunc__)
proxies = []
callback = self.CrawlFunc_List
for i in callback:
print('Callback', i)
for proxy in eval("self.{}()".format(i)):
print('Getting', proxy, 'from', i)
proxies.append(proxy)
return proxies以上代理的代码中,我并没有抓取每个网站全部页数,如果有需要可以自行调节。
这里我们可以直接写一个调用代码,来测试代码是否正常,写在:Spider.py 也就是代理的代码中,代码如下:
if __name__ == '__main__':
Tester = FreeProxyGetter()
Tester.run()运行结果如下:
结果较多,省略大部分结果。
Getting 14.115.70.177:4216 from crawl_xicidaili
Getting 116.22.48.220:4216 from crawl_xicidaili
Getting 223.241.3.120:4216 from crawl_xicidaili
......
Getting 60.188.1.27:8232 from crawl_data5u
Callback crawl_kxdaili
Getting 117.71.165.208:3000 from crawl_kxdaili
Getting 223.99.197.253:63000 from crawl_kxdaili
Getting 60.255.186.169:8888 from crawl_kxdaili
Getting 180.168.13.26:8000 from crawl_kxdaili
Getting 125.124.51.226:808 from crawl_kxdaili
Getting 47.99.145.67:808 from crawl_kxdaili
Getting 222.186.55.41:8080 from crawl_kxdaili
Getting 36.6.224.30:3000 from crawl_kxdaili
Getting 110.43.42.200:8081 from crawl_kxdaili
Getting 39.137.69.8:80 from crawl_kxdailiok,至此代理成功抓取,接下来就是我们的异步检测了。
6. 异步检测
这里,我们需要编写一个 **error.py ** 来自定义包:
class ResourceDepletionError(Exception):
def __init__(self):
Exception.__init__(self)
def __str__(self):
return repr('The proxy source is exhausted')
class PoolEmptyError(Exception):
def __init__(self):
Exception.__init__(self)
def __str__(self):
return repr('The proxy pool is empty')异步检测代码,这里我就不做任何数据存储,有需求的可以自行添加,下一篇将添加一个存入 redis 数据库的,敬请关注!
# files:schedule.py
import asyncio
import time
from multiprocessing.context import Process
import aiohttp
from db import RedisClient
from Spider import FreeProxyGetter
from error import ResourceDepletionError
from aiohttp import ServerDisconnectedError, ClientResponseError, ClientConnectorError
from socks import ProxyConnectionError
get_proxy_timeout = 9
class ValidityTester(object):
"""
代理的有效性测试
"""
def __init__(self):
self.raw_proxies = None
self.usable_proxies = [] # 可用代理
self.test_api = 'http://www.baidu.com'
def set_raw_proxies(self, proxies):
self.raw_proxies = proxies # 临时存储一些代理
async def test_single_proxy(self, proxy):
"""
python3.5 之后出现的新特性
text one proxy, if valid, put them to usable_proxies.
"""
try:
async with aiohttp.ClientSession() as session:
try:
if isinstance(proxy, bytes):
proxy = proxy.decode('utf-8')
real_proxy = 'http://' + proxy
print('Testing', proxy)
async with session.get(self.test_api, proxy=real_proxy, timeout=get_proxy_timeout) as response:
if response.status == 200:
print('Valid proxy', proxy)
except (ProxyConnectionError, TimeoutError, ValueError):
print('Invalid proxy', proxy)
except (ServerDisconnectedError, ClientResponseError, ClientConnectorError) as s:
print(s)
pass
def test(self):
"""
aio test all proxies.
"""
print('ValidityTester is working')
try:
loop = asyncio.get_event_loop()
tasks = [self.test_single_proxy(proxy) for proxy in self.raw_proxies]
loop.run_until_complete(asyncio.wait(tasks))
except ValueError:
print('Async Error')
class Schedule(object):
@staticmethod
def valid_proxy():
"""
Get half of proxies which in Spider
"""
tester = ValidityTester()
free_proxy_getter = FreeProxyGetter()
# 获取 Spider 数据库数据
# 调用测试类
tester.set_raw_proxies(free_proxy_getter.run())
# 开始测试
tester.test()
def run(self):
print('Ip processing running')
valid_process = Process(target=Schedule.valid_proxy) # 获取代理并筛选
valid_process.start()
if __name__ == '__main__':
schedule = Schedule().run()对于上面的部分代理代码,我为了输出结果更加直观,把 print() 输出的,包括 utils.py 的 print() 全部注释了, 运行结果(省略部分输出)
Testing 182.46.252.84:9999
Testing 183.63.188.250:8808
Testing 39.137.69.10:8080
Testing 119.190.149.226:8060
Testing 219.159.38.201:56210
Testing 58.246.143.32:8118
Testing 114.99.117.13:3000
Testing 114.229.229.248:8118
Testing 119.57.108.53:53281
Testing 223.247.94.164:4216
Testing 219.159.38.208:56210
Testing 59.44.78.30:42335
Testing 112.74.87.172:3128
Testing 182.92.235.109:3128
Testing 58.62.115.3:4216
Testing 183.162.171.37:4216
Testing 223.241.5.46:4216
Testing 223.243.4.231:4216
Testing 223.241.5.228:4216
Testing 183.162.171.56:4216
Testing 223.241.4.146:4216
Testing 223.241.4.200:4216
Testing 223.241.4.182:4216
Testing 118.187.50.114:8080
Testing 223.214.176.170:3000
Testing 125.126.123.208:60004
Testing 163.125.248.39:8088
Testing 119.57.108.89:53281
Testing 222.249.238.138:8080
Testing 125.126.97.77:60004
Testing 222.182.54.210:8118
Valid proxy 58.220.95.90:9401
Valid proxy 60.191.45.92:8080
Valid proxy 222.186.55.41:8080
Valid proxy 60.205.132.71:80
Valid proxy 124.90.49.146:8888
Valid proxy 218.75.109.86:3128
Valid proxy 27.188.64.70:8060
Valid proxy 27.188.62.3:8060
Valid proxy 221.180.170.104:8080
Valid proxy 39.137.69.9:8080
Valid proxy 39.137.69.6:80
Valid proxy 39.137.69.10:8080
Valid proxy 114.229.6.215:8118
Valid proxy 221.180.170.104:8080
Valid proxy 218.89.14.142:8060
Valid proxy 116.196.85.150:3128
Valid proxy 122.224.65.197:3128
Valid proxy 112.253.11.103:8000
Valid proxy 112.253.11.103:8000
Valid proxy 112.253.11.113:8000
Valid proxy 124.90.52.200:8888
Cannot connect to host 113.103.226.99:4216 ssl:default [Connect call failed ('113.103.226.99', 4216)]
Cannot connect to host 36.249.109.59:8221 ssl:default [Connect call failed ('36.249.109.59', 8221)]
Cannot connect to host 125.126.121.66:60004 ssl:default [Connect call failed ('125.126.121.66', 60004)]
Cannot connect to host 27.42.168.46:48919 ssl:default [Connect call failed ('27.42.168.46', 48919)]
Cannot connect to host 163.125.113.220:8118 ssl:default [Connect call failed ('163.125.113.220', 8118)]
Cannot connect to host 114.55.63.34:808 ssl:default [Connect call failed ('114.55.63.34', 808)]
Cannot connect to host 119.133.207.10:4216 ssl:default [Connect call failed ('119.133.207.10', 4216)]
Cannot connect to host 58.62.115.3:4216 ssl:default [Connect call failed ('58.62.115.3', 4216)]
Cannot connect to host 117.71.164.232:3000 ssl:default [Connect call failed ('117.71.164.232', 3000)]到此,多站抓取异步检测,就已经完全实现,也是实现了模块化编程。我也 顺便把项目结构分享一下:
C:.
│ error.py
│ info.txt
│ schedule.py
│ Spider.py
│ the_test_code_crawler.py
│ utils.py
│
└─__pycache__
db.cpython-37.pyc
error.cpython-37.pyc
Spider.cpython-37.pyc
utils.cpython-37.pyc本篇我想你主要学习到的目标也就是开头所说的,这里就不赘述了,下一篇我将带大家把抓取到可用的代理进行存储到 redis 数据库中,尽请关注!
源代码文件获取:公众号后台回放:ProxyPool-1
也欢迎加入我的交流群,一起交流!


欢迎关注我公众号:AI悦创,有更多更好玩的等你发现!
公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Web全栈、Linux」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh

更新日志
1c35a-于aed17-于972e2-于f7f78-于