
05-快收下这枚 Scrapy Requests 口味的爬虫“回魂丹”
前言
五分钟带您由放弃到深入。爬虫,又名蜘蛛,是一个模拟人类请求网站行为的程序,可以自动请求网页,并将数据抓取下来,然后使用一定的规则提取有价值的数据。学习爬虫的人虽多,但从入门到放弃的人也是不少哒。
他们大都经历以下“磨难”!
入门:爬虫好高大上,我要学会它,我要用它爬vip视频,收费音乐,要钱的软件,统统给我爬一遍。
迷茫:兴致高,想要深入学习,但是网上相关教程的价格较高,免费的视频又千篇一律,知识面较浅,不知如何选择。
放弃:与爬虫斗争了一段时间后,发现,只能拿 Quotes to Scrapy 等简单的网站(软柿子捏),对设有反爬的网站完全没办法,浪费时间和精力,放弃放弃!
本次 Chat 将带你来从 0 到 1 的学习网络爬虫。
一、Python 安装那些事
1.1 Python 安装
下载方法
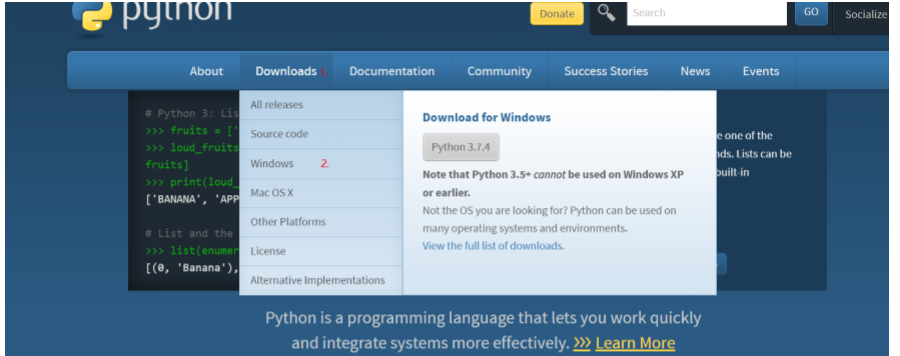
如图:
- 选择上方 Downloads 选项
- 在弹出的选项框中选择自己对应的系统(注:若直接点击右边的灰色按钮,将下载的是 32 位)
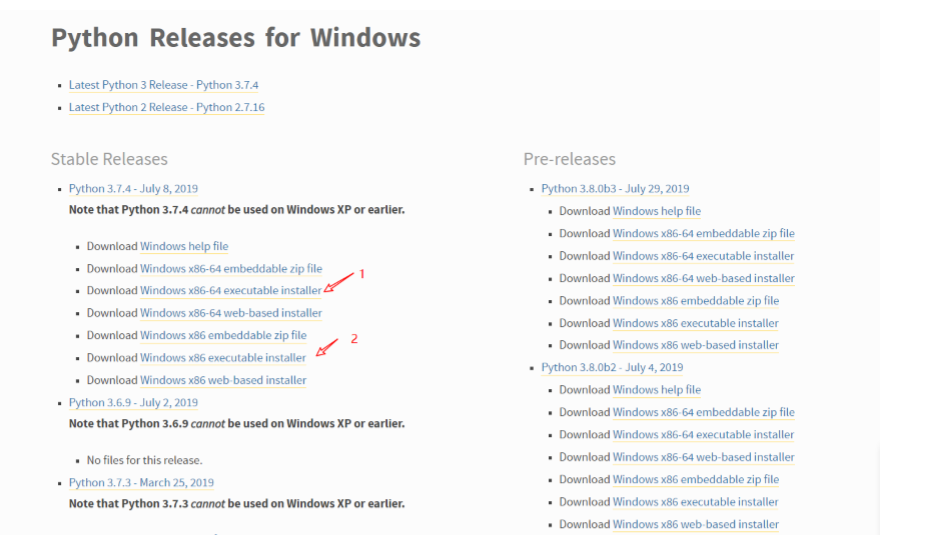
进入下载页面,如图:
- 为 64 位文件下载
- 为 32 位文件下载
选择您对应的文件下载。
安装注意事项
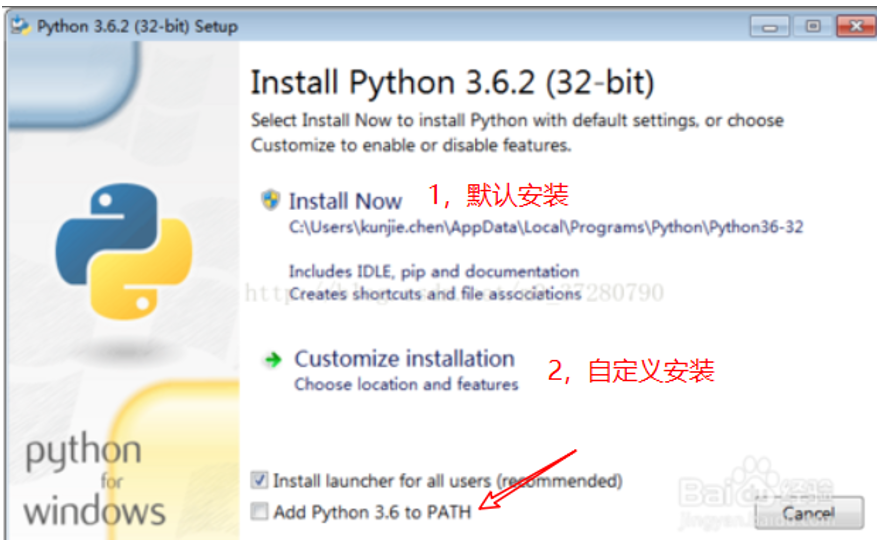
(图片来源于网络)
自定义选项,可以选择文件存放位置等,使得 Python 更符合我们的操作习惯。
默认安装:一路 Next 到底,安装更方便、更快速。
特别注意:图中箭头指向处一定要记得勾选上。否则得手动配置环境变量了哦。
Q:如何配置环境变量呢?
R:控制面板—系统与安全—系统—高级系统设置—环境变量—系统变量—双击 path—进入编辑环境变量窗口后在空白处填入 Python 所在路径—一路确定。
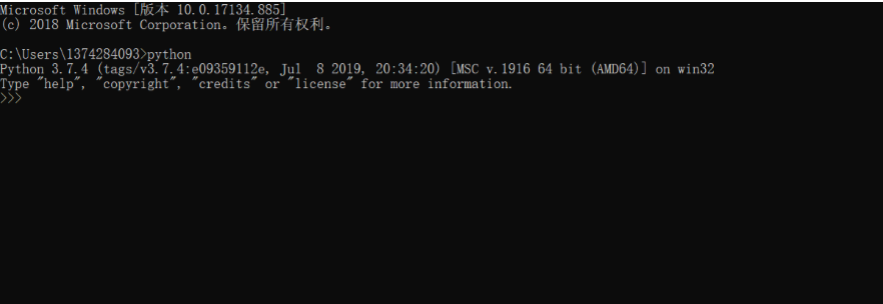
检查
安装完 Python 后,Win+R 打开运行窗口输入 cmd,进入命令行模式,输入 python。若如下图显示 Python 版本号及其他指令则表示 Python 安装成功。
1.2 Python 编译器 Sublime
选择该编辑器的原因:
- 不需要过多的编程基础,快速上手
- 启动运行速度快
- 最关键的原因——免费
常见问题
使用快捷键 Ctrl+B 无法运行结果,可以尝试 Ctrl+Shift+P,在弹出的窗口中选择 Bulid With: Python。
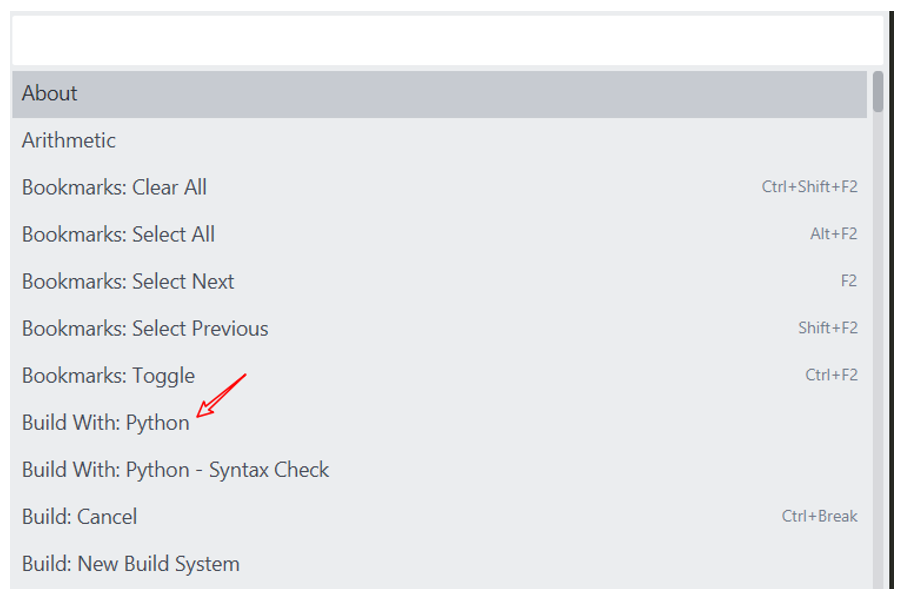
或选择上方的 Tool 选项中的 Build With 选项,在弹出的窗口中选择 Python。
1.3 爬虫常用库安装
Python 通过 pip install xxx,来使得 Python 自动安装库。
Requests
代码如下:
pip install requestsBeautifulSoup
代码如下:
pip install lxml
pip install BeautifulSoup4Scrapy
方法一
- Window 系统
代码如下:
pip install scrapy- Mac 系统
代码如下:
Xcode-select –install
pip3 install scrapy方法二
第一种方法常常会出现错误,所以我们得先安装依赖库。
1. 安装依赖库 lxml,代码如下:
pip install lxml2. 安装依赖库 pyOpenSSL
- 进入 https://pypi.org/project/pyOpenSSL/#downloads 下载 wheel 文件
- 在命令行窗口内 cd+ 下载位置进入下载目录下输入
代码如下:
pip install pyOpenSSL-18.0.0-py2.py3-none-any.whl3. 安装依赖库 Twisted 库
进入 http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted,下载对应的版本。
代码如下:
Pip install 刚刚下载的文件名4. 安装依赖库 pywin32
进入网址下载对应的版本:
https://sourceforge.net/projects/pywin32/files/pywin32/Build%20221/
下载完后,双击 EXE 文件安装即可。
5. 安装 Scrapy
代码如下:
pip install Scrapy二、Python 语言快速入门
前言:本节虽是零基础友好文,但也有对一些知识点的深度拓展,有编程基础的看官也可以选择性观看哦!
2.1 Python 交互式模式与命令行模式
命令行模式
1. 进入方式
Windows:
- 点击开始,运行,CMD 回车
- 按 WIN+R,CMD 回车
Mac:
- 打开应用菜单中的 Launchpad,找到并打开【其他】文件夹,点击【终端】
- 打开 Finder 窗口,在「应用程序」目录中直接搜索“终端”关键字
2. 提示符
在不同的操作系统环境下,命令提示符各不相同,以 Windows 为例:它的提示符为
C:\机器名\用户名>
交互式模式
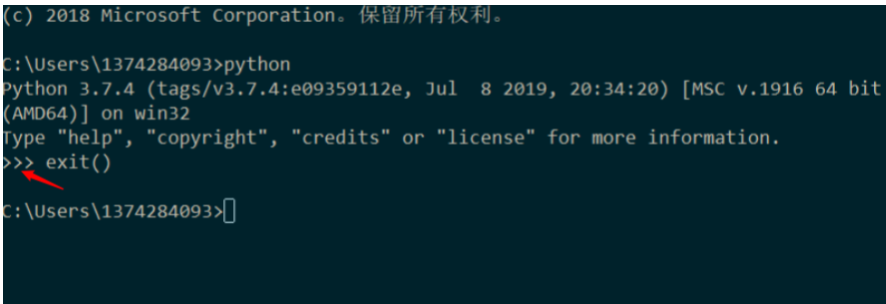
1. 进入方式
在命令模式下输入 Python 指令即可进入,输入 exit(),便会退出交互式模式。
2. 提示符:>>>
区别
- py 文件只能在命令行中运行;
- Python 交互模式的代码是输入一行、执行一行;而命令行模式下直接运行 .py 文件是一次性执行该文件内的所有代码。
由此看来,Python 交互模式主要是用来调试代码的。
2.2 数据类型和变量
Python 中主要的数据类型有:整数(int)、浮点数(float)、布尔值(bool)、字符串(str)、列表(list)、元组(tuple)、字典(dict)、集合(set)。
2 #整数 (int)
3.1314526 #浮点数 (float)
True #布尔值 (bool)
"1" #字符串 (str)
[1,2,"a"] #列表(list)
(1,2,"a") #元组(tuple)
{"name":"小明"} #字典(dict)在 Python 中,你可以使用 # 来注释相关信息,注释的信息 IDE 在编译的时候,会自动忽略。
整数
与数学中整数概念一致,共有 4 种进制表示:二进制、八进制、十进制和十六进制。默认情况,整数采用十进制。
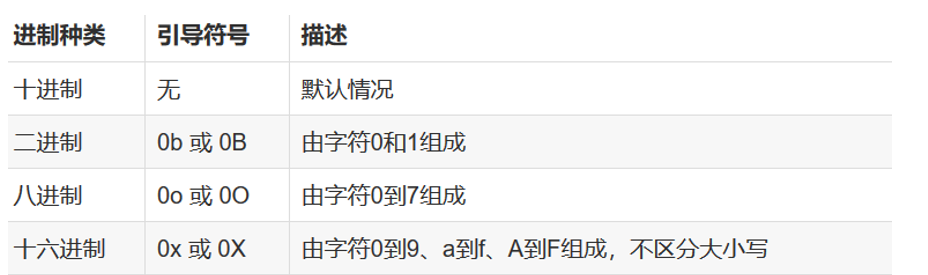
(图片来源于网络)
浮点数
表示有小数点的数值。浮点数有两种表示方法:小数表示和科学计数法表示。(注:计算器或电脑表达 10 的幂是一般是用 E 或 e,即 2.88714E13=28871400000000)
布尔值
布尔值在 Python 中有两个量:True 和 False,对应的值分别是 1 和 0(True、False 注意大小写)。
代码如下:
var1 = 12
var2 = 12
var3 = 13
print(var1==var2) #输出True
print(var1==var3) #输出Falsevar1==var2 中的 == 是比较符,比较 var1 是否等于 var2,若等于则为真(True),否则为假(False)。
另外,布尔值可以用 and(与)、or(或)和 not(非)进行运算。
代码如下:
与运算:铁面无私,要求所有都True,否则输出结果就为False。
True and True #True
True and False #False
False and False #False代码如下:
或运算:要求不高,只要有一个为True输出的结果就为True。
True or True #True
True or False #True
False or False #False代码如下:
非运算:老是唱反调,输入True,它给你输出False,反之亦然。(特别注意:它是一个单目运算符)
not True #False
not False #True字符串
字符串是以单引号 ' 或双引号 " 括起来的任意文本,如 ’aaa’,”abc”。'' 或 "" 本身只是一种表示方式,不是字符串的一部分,因此,字符串 'aaa' 只有 aaa 这 3 个字符。
若字符串里已经包含了 ' 或 " 了呢?我们可以用转义字符 \ 来标识,比如:
you’re 的字符串表示为:
"you\' re"若字符串内容包含 ' 的同时也包含了 \ 呢? 那我们可以用 \\ 来表示,代码如下:
"you\\'re"列表
在 Python 中,列表是比较重要的一个数据容器。
代码如下:
list1 = [1,2,3,4,5]
list2 = ["AI悦创","GitChat","Fly"]列表是具有索引的,因此想要访问一个列表中的数值,只需要列表名 + 索引值就能够得到了。
print(list1[2]) # 输出:3
print(list2[0]) #输出:AI悦创
# 示例二
lists = ['a','b','c']
lists.append('d')
print(lists)
print(len(lists))
lists.insert(0,'mm')
lists.pop()#删除最后一个元素
print(lists)
# 输出
['a', 'b', 'c', 'd']
4
['mm', 'a', 'b', 'c']元组
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
代码实例:
tup1=('aaa',1,'bbb',2)需注意:组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用。
>>> tup1=(1)
>>> type(tup1)
<class 'int'>
>>> tup2=(1,)
>>> type(tup2)
<class 'tuple'>列表与元组的区别
不知大家在学完列表与元组后,有没有发现两者有些类似,
主要的不同在于:
- 元组使用小括号,列表使用方括号。
- 列表是动态的,长度大小不固定,可以随意地增加、删减或者改变元素(可变)。
元组是静态的 ,长度大小固定,无法增加删减或者改变(不可变)。
偷偷告诉你哦:其实是列表与元组最重要的区别,而这样的差异,势必会影响两者存储方式。我们可以来看下面的例子:
l = [1, 2, 3]
l.__sizeof__()
64
tup = (1, 2, 3)
tup.__sizeof__()
48你可以看到,对列表和元组,我们放置了相同的元素,但是元组的存储空间,却比列表要少 16 字节。这是为什么呢?
事实上,由于列表是动态的,所以它需要存储指针,来指向对应的元素(上述例子中,对于 int 型,8 字节)。另外,由于列表可变,所以需要额外存储已经分配的长度大小(8 字节),这样才可以实时追踪列表空间的使用情况,当空间不足时,及时分配额外空间。
代码实例:
l = []
l.__sizeof__() // 空列表的存储空间为 40 字节
40
l.append(1)
l.__sizeof__()
72 // 加入了元素 1 之后,列表为其分配了可以存储 4 个元素的空间 (72 - 40)/8 = 4
l.append(2)
l.__sizeof__()
72 // 由于之前分配了空间,所以加入元素 2,列表空间不变
l.append(3)
l.__sizeof__()
72 // 同上
l.append(4)
l.__sizeof__()
72 // 同上
l.append(5)
l.__sizeof__()
104 // 加入元素 5 之后,列表的空间不足,所以又额外分配了可以存储 4 个元素的空间上面的例子,大概描述了列表空间分配的过程。我们可以看到,为了减小每次增加/删减操作时空间分配的开销,Python 每次分配空间时都会额外多分配一些,这样的机制(over-allocating)保证了其操作的高效性:增加/删除的时间复杂度均为 O(1)。
但是对于元组,情况就不同了。元组长度大小固定,元素不可变,所以存储空间固定。
看了前面的分析,你也许会觉得,这样的差异可以忽略不计。但是想象一下,如果列表和元组存储元素的个数是一亿,十亿甚至更大数量级时,你还能忽略这样的差异吗?
所以我们可以得出结论:元组要比列表更加轻量级一些,所以总体上来说,元组的性能速度要略优于列表。
字典
字典是一种特殊的列表,字典中的每一对元素分为键(key)和值(value)。对值的增删改查,都是通过键来完成的。注意:字典中的建 /KEY 需是不可变数据类型,如:整型 int、浮点型 float、字符串型 string 和元组 tuple。
代码如下
brands = {"Tencent":"腾讯","Baidu":"百度","Alibaba":"阿里巴巴"}
brands["Tencent"] #获取键值为"Tencent"的value
del brands["Tencent"] #删除腾讯
brands.values[] #得到所有的value值
brands.get("Tencent") # 获取键值为"Tencent"的value集合
集合是一个无序的不重复元素序列,我们可以通过 {} 或者 set() 来创建它。
代码如下:
set1={'a','aa','aaa','aaaa'} #{'aaa', 'aa', 'aaaa', 'a'}
set1=set(['a','aa','aaa','aaaa'])
print(set1) #{'aaaa', 'aa', 'a', 'aaa'}注意:创建一个空集合必须用 set() 而不是 {},因为 { } 是用来创建一个空字典。
>>> s={}
>>> type(s)
<class 'dict'>拓展
在数据类型中,我们多次提到可变对象,不可变对象,那什么是可变对象,什么是不可变对象呢?
先放个小提示:
- Python 不可变对象:int、float、tuple、string
- Python 可变对象:list、dict、set
从字面意思上理解,“可变对象”是指可以使其元素发生改变的对象,不可变对象就是不可以发生改变,由此我们可以猜测,两者的区别在于:能否对其元素进行修改。
而我们通常是通过什么方式来尝试修改对象呢?俗话说,“东西不在多,而在常用”,这里,我们一起介绍“增删改查”这几种常用的方法。
以可变对象列表为例,添加:append、insert。
代码如下:
>>> list=["a","b"]
>>> list.append("c") # append(元素),将元素添加到列表里
>>> print(list)
['a', 'b', 'c']
>>> list.insert(0,"d")#insert(索引,元素),将元素添加到指定位置
>>> print(list)
['d', 'a', 'b', 'c']删除:remove()、pop(索引)、pop()
运行如下代码:
>>> list.remove("d")#remove(元素),删去list中看不顺眼的元素
>>> list
['a', 'b', 'c']
>>> list.pop(1)
'b'#被删掉的元素
>>> print(list)
['a', 'c']#pop(索引),删去制定位置的元素
>>> list.pop()
'c'#被删掉的元素
>>> print(list)#pop(),默认删去最后一个元素
['a']修改:list [索引] = 元素
代码如下:
>>> list=['a','c']
>>> list[0]='b'#替换制定位置的元素
>>> print(list)
['b','c']查找:list [索引]
代码如下:
>>> list=['b','c']
>>> list[1]#查找指定位置的元素
'c'可变对象 list 全部修改成功。现在,我们再来尝试对不可变对象 tuple 进行简单的修改,看看会发生什么?
>>> tuple1=(1,2,3,4)
>>> tuple1[0]=5
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment#报错通过以上对 list、tuple 的修改,我们可以证实不可变对象与可变对象的最简单明了的区别:可变对象的元素是可以修改的,不可变对象的元素是不能进行修改的。
变量
当我们在 CMD 控制台输入 1+1 的时候,控制台会输出 2。但是,如果我们要在之后的计算中继续使用这个 2 该怎么办呢?我们就需要通过一个“变量”来存储我们需要的值。
代码如下:
a=1+1 #这里a就是一个变量,用来存储 1+1产生的2如上面的“栗子”所示:Python 中的变量赋值不需要类型声明。
偷偷告诉你哦:创建变量时会在内存中开辟一个空间。基于变量的数据类型(若没交代数据类型,则默认为整数),解释器会分配指定内存,并决定什么数据可以被存储在内存中。
拓展
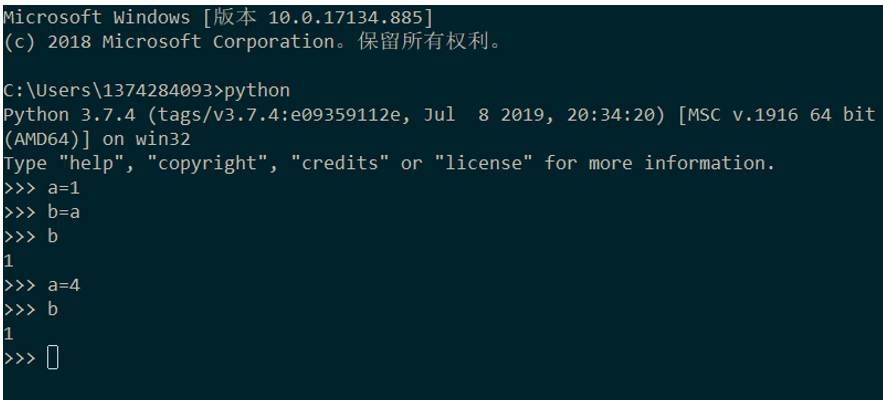
是不是觉得很奇妙?b=a 按理说 a 变了,b 也应该跟着变呀!
让我们一起做个假设:
假设开发商 = 内存,变量 = 房子,变量存储的值 = 住户,在 b=a 前,a=1 的大趋势使得开发商把 a 房子建造好了,当 b=a 复制时,开发商又马不停蹄的画了块内存建了 b 房子,且 b 房子和 a 房子里都住着数值 1,因此当 a=4,使得 a 房子换了新住户,但这不能影响到 b 房子住户——数值 1 的居住。
三、条件、循环和其他语句
Python 使用 if 和 else 来作为条件判断语句。
代码实例:
# 判断语句:if … else …
i = 1
if i == 1:
print("Yes,it is 1")
else:
print("No,it is not 1")
# if … else … 是经典的判断语句,需要注意的是在 if expression 后面有个冒号,同样在 else 后面也存在冒号。上面的语句用来判断变量 i 是否等于 1。请注意:Python 对缩进是极重视的。所以在写判断语句的时候,需要注意缩进是否在同一个区域。
Python 支持 for 循环和 while 循环。循环语句和 if、else 语句类似,比如都需要加冒号,语句体需要缩进。
for i in range(1,10):
print(i)上面的语句是输出 1 到 10 之间的数,请注意,range(1,10) 的范围是从 1 到 9,不包含 10。
i = 1
while (i<10):
i += 1
if i!= 8:
continue
else:
break上面的语句中,break 关键词的意思是:跳出循环;continue 的意思是:继续循环。
3.1 函数
我们平常使用的 print() 和 type(),这两个都是函数。对于重复性的代码段,我们不需要每次都写出,只需要通过函数的名称调用就可以了。
定义函数的关键字是 def,定义的方式和 for 循环差不多。
代码如下:
def function(param): # function为函数名,param为参数
i = 1
return i # f返回值为了讲解得更形象,我们来写一个 a+b 求和的函数。
def getsum(a,b): #定义函数名为getSum,参数为a,b
sum = a+b;
return sum; #返回a+b的和,sum
print(getsum(1, 2))定义完成后,我们就可以在程序的其他地方,通过调用 getSum(a,b) 来使用这个函数。
3.2 文件
Python 提供了丰富且易用的文件操作函数,我们将常见的操作快速学习一下。
open()
代码如下:
open("abc.txt","r")
#open()为Python 内置的文件函数,用来打开文件,“abc.txt”为目标文件名,"r"代表以只读方式打开文件,其他的还有“w"和"a"模式read()
打开的文件,必须通过 .read() 方法才能得到数据。
file = open("abc.txt","r")
words = file.read()关于详细的读取,可以有兴趣的可以参考这篇文章:Python 中的文件基本操作合集 with open~。
四、网页基础
4.1 什么是网页
当你在浏览器输入 www.baidu.com,并回车访问的时候,你看到的所有的展现在你屏幕上的东西,其实都是网页。网页是通过 URL 来进行识别和访问的。按照百度百科的说法,网页被定义成下面的说明。
网页(英语:Web Page)网页是构成网站的基本元素,是承载各种网站应用的平台。通俗地说,您的网站就是由网页组成的,如果您只有域名和虚拟主机而没有制作任何网页的话,您的客户仍旧无法访问您的网站。
网页是一个包含 HTML 标签的纯文本文件,它可以存放在世界某个角落的某一台计算机中,是万维网中的一“页”,是超文本标记语言格式(标准通用标记语言的一个应用,文件扩展名为 .html 或 .htm)。网页通常用图像档来提供图画。网页要通过网页浏览器来阅读。
简单来说,你在浏览器中见到的任何一个页面,都是网页。
4.2 为什么要学习网页知识
学习基础的网页知识最重要的一点,是因为这 Chat 后续要讲授的技术,都涉及到对网页内容的分析与爬取。哪怕仅仅是作为一名刚入门的爬虫小白,你都需要了解一下网页的相关知识。作为一名开发人员,不仅仅要知其然,更要知其所以然。一味地 Copy 代码,不懂得为什么要这样做,反而会大大降低学习的效果。为此我公众号有一篇学习方法分享给你:
4.3 浏览网页的过程
- 输入网址
- 浏览器向 DNS 服务商发送请求
- 找到对应服务器
- 服务器解析请求
- 服务器处理请求得到最终结果发回去
- 浏览器解析返回的数据
- 展示给用户
4.4 关于域名
我们写爬虫是离不开域名的,或者我们简单地理解为 URL ,编写的第一步也是先分析其中的规律。
我要了解其中的的一级域名、二级域名即可。如下图:

(图片来源于网络)
那网址参数是上面网址的哪一部分呢?思考一下,再继续往下看。

(图片来源于网络)
4.5 前端入门
那么,问题来了!
什么是前端?什么是后端?
- 程序员 A:我是做后端的
- 程序员 B:我是做前端的
从这简单的两句话中我们可以了解到什么呢?
其实,你可以简单地理解,前端主要是做人机交互式界面,后端主要做的是敲代码。我这里就不讨论前后的难度还是其他,只想你能最直接地了解到这个前后端的一些简单内容。
那前端开发网页时,用的工具之一是什么?
我可以给你一个答案,前端使用的工具之一就是:Chrome 或者 Firefox。而作为一名爬虫工程师,不使用这其中之一的前端开发工具,那就太 low 啦,那为什么选择两个而不支持国产 360 浏览器、QQ 浏览器之类的或者 IE 浏览器?
我把这个问题分成两个答案:
- 360 浏览器和 QQ 浏览器之类的浏览器其实底层还是谷歌,只不过 360 浏览器与 QQ 浏览器有些你学需要的开发者工具,缺少某些你需要的东西。
- 而 IE 浏览器,微软已经表明将停止 IE 浏览器的更新,希望用户别使用。
前端三个重要方面

(图片来源于网络)
这个三个方面有兴趣可以自行了解。
4.6 HTML
HyperText Markup Language
网页最基本的要素,通过标记语言的方式来组织内容(文字、图片、视频)。
下图右边的对应的就是 HTML:
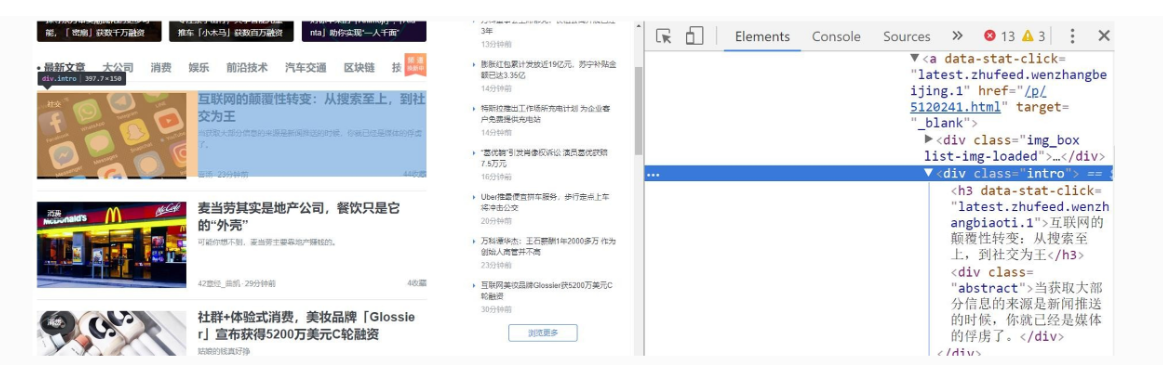
这部分前端,需要你自行敲打体验:
新建文件 >>> 存文件 >>> 文件命名 >>> 命名为 AIYC.html >>> 然后使用 Sublime Text3 敲入以下内容体验
代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="
X-UA-Compatible" content="
IE=edge,chrome=1">
<title>AI悦创</title>
<meta name="description" content="">
<meta name="keywords" content="">
</head>
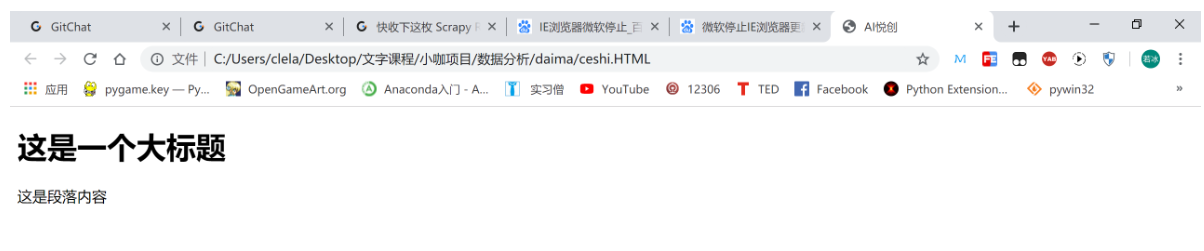
<body>
<h1>这是一个大标题</h1>
<p>这是段落内容</p>
</body>
</html>浏览器打开结果:
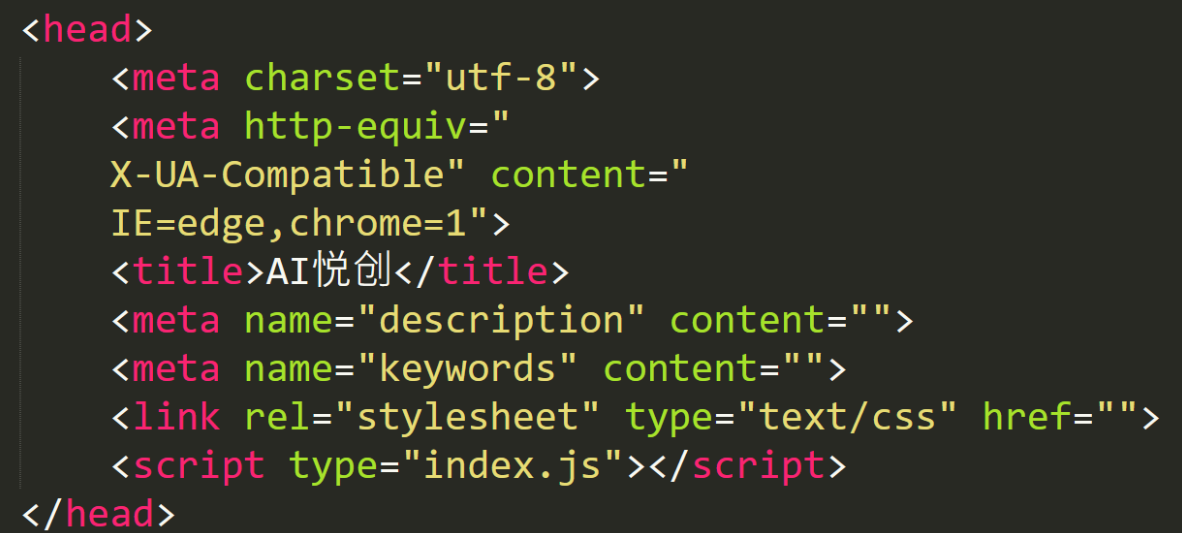
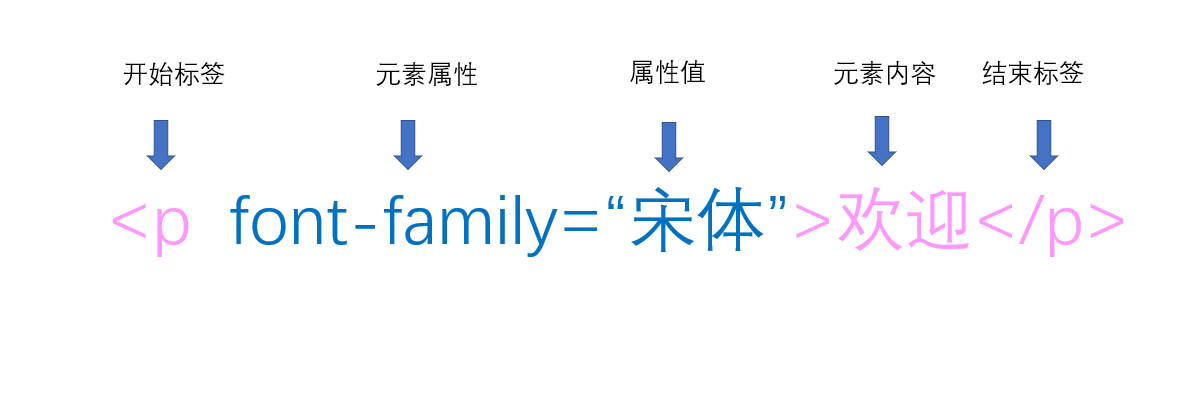
上述示例中的 <html></html>、<title></title> 等,只要是用 <> 包裹住的元素,都可以认为是 HTML 的“标记标签”。需要注意的是,“标题标记” 一般都有开始标记和结束标记,普通的标题标记,一般以 <标签>内容</标签> 这样进行使用。接下来我们详细的解释一下上述示例中的“标记标签:[1]
<!DOCTYPE html>是 HTML 的声明。该方法是为了方便浏览器准确的获取 HTML 的版本,以便于正确的对网页内容进行渲染(关于 HTML 版本的问题,你可以参考这篇文章:HTML 标准的版本历史)。<html></html>是 HTML 的根元素。一个 HTML 文档的所有内容,必须放入此标签内。<head></head>是 HTML 的元(meta)数据。<meta>能够提供 HTML 页面的元信息,比如定义网页的编码方式、针对搜索引擎的关键词管理。<title></title>是网页的标题,但我们打开一个网页,浏览器显示的标签名就是 title 中的文字。<body></body>是 HTML 文档所包含的所有内容(例如文字、视频、音频等)。<h1></h1>用来定义标题。在 HTML 中,h 被确切的定义为标题大小。一共有 6 级标题,分别是<h1>-<h6>,文字从大到小。<p></p>是 HTML 页面的段落标签。HTML 中如果对文字另起一行的话,必须使用该元素。
head 和 body

4.7 HTML 元素解析
常用 HTML 标签

CSS 简介
CSS 指层叠样式表(Cascading Style Sheets):它定义了一个网页该如何显示里面的元素,比 如这个段落该靠在浏览器的左边还是右边还是 中间,这段文字的字体、颜色、大小该是什么等都由 CSS 定义(是用来渲染 HTML 文档中元素标签的样式)。
常见的 CSS 使用方式有三种:
- 内联:在 HTML 元素中直接使用 “style” 属性。
- 内部样式表:在
<head></head>内标记<style>元素中使用 CSS。 - 外部引用:使用外部定义好的 CSS 文件。
内联
用内联的方式使用 CSS,只需要在相关的标签中使用样式属性即可,不需要其他的配置。
<p> 这是正常的段落文字</p>
<p style="color:red"> 这是使用内联CSS的段落文字</p>上述的两个段落,经过浏览器的渲染后,显示的结果如下:

内部样式表
内联方式虽然简单,但是如果标签很多,一个一个添加,无疑浪费了本来就很宝贵的时间。如果对某一个标题设定为统一样式,或者是希望能够方便管理相关样式的时候,就可以使用内部样式表
代码如下:
<head>
<style type="text/css">
p {color:red;}
</style>
</head>内部样式表应该在 <head> 部分通过 <style> 标签来定义。通过上述内部样式表的展示,现在所有段落(<p>)里面的文字,都变成了红色。
外部样式表
试想一下:你有 100 个网页要使用 CSS 样式,如果使用内联样式,你的工作量无疑是“亚历山大”的;如果使用内部样式表,你也要重复的修改 100 次。这个时候,你就需要外部样式表来“救火”啦。外部样式表可以仅通过一个文件来改变整个网页的外观。
代码如下:
<head>
<link rel="stylesheet" type="text/css" href="gitchat.css">
</head>上述的例子中,我们通过 <link> 导入了一个名叫 gitchat.css 的外部样式表。gitchat.css 里面是已经写好的各种 CSS 样子。当我们的文件中存在对应的标签时,浏览器会自动为我们配置好相应的样式。
CSS 解析

- id 在每个 HTML 中只有一个
- class 可以有多个
盒子模型

(图片来源于网络)
JavaScript
主要用于前端的一种编程语言,为网站提供动态、交互效果。
五、爬虫基础
5.1 爬虫基本原理讲解
首先,我们先了解一下什么是互联网:

什么是互联网?
互联网是由网络设备(网线、路由器、交换机、防火墙等)和一台台计算机连接而成,像一张网一样。
互联网建立的目的?
互联网的核心价值在于数据的共享/传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿 U 盘去别人的计算机上拷贝数据了。
什么是上网?爬虫要做的是什么?
我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。
只不过,用户获取网络数据的方式是:
浏览器提交请求 >>> 下载网页代码 >>> 解析/渲染成页面
而爬虫程序要做的就是:
模拟浏览器发送请求 >>> 下载网页代码 >>> 只提取有用的数据 >>> 存放于数据库或文件中
区别在于:我们的爬虫程序只提取网页代码中对我们有用的数据。
5.2 爬虫
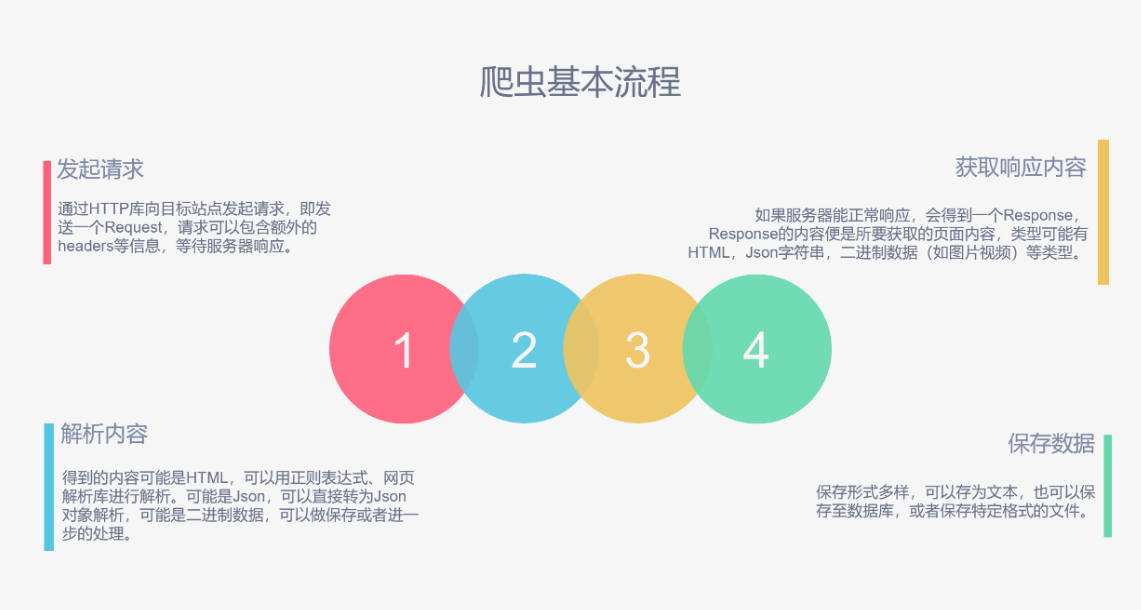
爬虫的基本流程
为了让你有更好的体验,我把字转换成一张图片给你演示看下图:
什么是 Request 和 Response?

Request 中包含什么?

请求方式
- 常用的请求方式:GET、POST
- 其他请求方式:HEAD、PUT、DELETE、OPTHONS
GET 与 POST 请求方法有如下区别:
- GET 请求中的参数包含在 URL 里面,数据可以在 URL 中看到,而 POST 请求的 URL 不会包含这些数据,数据都是通过表单形式传输的,会包含在请求体中。
- GET 请求提交的数据最多只有 1024 字节,而 POST 方式没有限制。
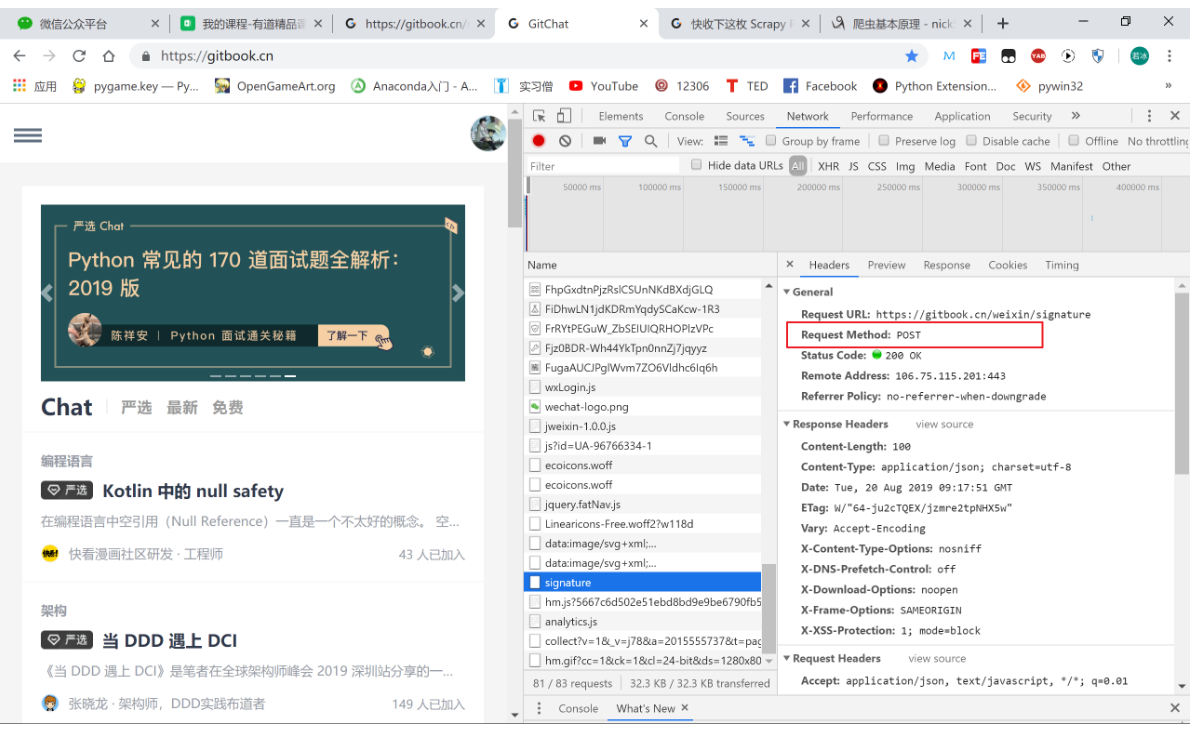
- POST 与 GET 请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz,POST 请求的参数放在请求体内,可用浏览器查看,存放于 form data 内;GET 请求的参数直接放在 URL 后。
POST:
GET:
这里以 GitChat 网站(https://gitbook.cn/)来演示操作流程:
进入网页 >>> 鼠标右键(或者 F12 )进入开发者模式 >>> 清空开发者列表 >>> (微信)扫码登陆 >>> Network >> All >>> 找到 POST 请求
接下来,我们来看一下动图演示:
Response 中包含什么?

1. 请求 URL
URL 全称统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用 URL 唯一来确定。
代码如下:
# url编码
# https://www.baidu.com/s?wd=图片
# 图片会被编码代码如下:
# 网页的加载过程是:
# 加载一个网页,通常都是先加载document文档,
# 在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求2. 请求头
- User-agent:请求头中如果没有 user-agent 客户端配置,服务端可能将你当做一个非法用户 host
- cookies:cookie 用来保存登录信息
一般做爬虫都会加上请求头 headers。
3. 请求体
- 如果是 GET 方式,请求体没有内容
- 如果是 POST 方式,请求体是 format data
- 登录窗口,文件上传等,信息都会被附加到请求体内
- 登录输入错误的用户名密码,然后提交,就可以看到 POST,正确登录后页面通常会跳转,无法捕捉到 POST
5.3 总结爬虫
爬虫的比喻:
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据。
爬虫的定义:
向网站发起请求,获取资源后分析并提取有用数据的程序。
爬虫的价值:
互联网中最有价值的便是数据,比如天猫商城的商品信息、链家网的租房信息、雪球网的证券投资信息等,这些数据都代表了各个行业的真金白银。可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰。
如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能,你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
六、Requests 与 BeautifulSoup 库的基础操作
你以前是不是有这些问题?
- 能抓怎样的数据?
- 怎样来解析?
- 为什么我抓到的和浏览器看到的不一样?
- 怎样解决 JavaScript 渲染的问题?
- 可以怎样保存数据?
我想以上的问题或多或少你在有些迷茫,或不是很理解。接下来就带你进入 Requests 与 BeautifulSoup 库的基础操作。
这里为了照顾绝大多数的零基础或者基础不扎实的童鞋,我主要讲解Requests 与 BeautifulSoup 库基础操作,纳尼 (⊙o⊙)?不讲上面几点?别急,上面的几个问题我会简单地回答,之后的 Chat会分享给大家的,欢迎持续关注!
能抓怎样的数据?
- 网页文本:如 HTML 文档、JSON 格式文本等。
- 图片:获取到的是二进制文件,保存为图片格式。
- 视频:同为二进制文件,保存为视频格式即可。
- 其他:只要是能请求到的,都能获取。
怎样来解析?
- 直接处理
- JSON 解析
- 正则表达式
- BeautifulSoup
- PyQuery
- XPath
为什么我抓到的和浏览器看到的不一样?
动态加载和 JS 等技术渲染,所以不一样。
怎样解决 JavaScript 渲染的问题?
- 分析 Ajax 请求
- Selenium/WebDriver
- Splash
- PyV8、Ghost.py
可以怎样保存数据?
- 文本:纯文本、JSON、XML 等
- 关系型数据库:如 MySQL、Oracle、SQL Server 等具有结构化表结构形式存储
- 非关系型数据库:如 MongoDB、Redis 等 Key-Value 形式存储
- 二进制文件:如图片、视频、音频等直接保存成特定格式即可
好,解决上面的问题。我们来讲一下 Python 网络模块基础 Requets BeautifulSoup。
6.1 Requests
Requests 介绍
官方文档:
爬虫利器,回顾一下安装安装方式,在命令行中输入:
# Windows用户
pip install requests
# Mac用户输入
pip3 install requests一个简单的例子

- status_code:状态码
- encoding:编码方式
- cookies:Cookies
输出结果:
状态码
Cookies
什么是 Cookies,Cookies 的用途
什么是 Cookie?简单地说,就是记录你用户名和密码,让你可以直接进入自己账户空间的一组数据。多说无益,我们来亲自实践一下。也就是下面几点:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
模拟登陆合集教程,之后的 Chat 手把手带你哦!
Requests 库提供 HTTP 的所有基本请求方式:

主要讲基础 GET 请求。
GET 请求
可利用 params 参数:

输出结果:

POST 请求
利用 data 参数 为 POST 添加参数:

上传文件:
获取/发送 cookies
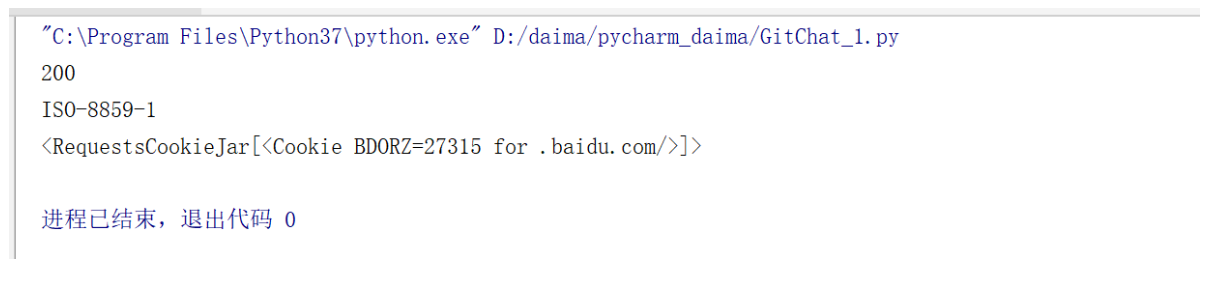
获取 www.baidu.com 的 cookies:
import requests
url = 'https://www.baidu.com'
req = requests.get(url)
coo = req.cookies
print(coo)
for key in coo.keys():
print(key)
print(coo[key])
# 输出
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
BDORZ
27315发送 cookies:
url = 'http://httpbin.org/cookies'
cookies = dict(my_cookie= 'test')
req=requests.get(url,cookies=cookies)
print(req.text){
"cookies":{
"my_cookie":"test"
}
}超时配置:利用 timeout 变量来配置最大请求时间。
import requests
requests.get('http://www.baidu.com', timeout=0.001)6.2 使用网页爬虫利器 Requests
为啥使用 Requests?
Requests 允许你发送纯天然,植物饲养的 HTTP/1.1 请求,无需手工劳动。你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive 和 HTTP 连接池的功能是 100% 自动化的,一切动力都来自于根植在 Requests 内部的 urllib3。
为什么要学习 Requests 呢?
对于初学者来说,主要原因是:
我们学习中,常常回去网络上找相关的资源,而对于老司机的我可以打包票讲,Requests 在使用人群是足够多的,对于入门,你所遇到的这些 Bug 你的前辈们都是遇到过的,所以问题的解决方法会比较多。
Requests 在互联网上拥有丰富的学习资源。在百度上搜索“Requests 爬虫”关键字,一共有千万多条搜索结果。这意味着 Requests 的相关技术已经比较成熟。特别对于初学者而言,一个具有丰富学习材料的内容,能够减少学习中的“挖坑”次数和“掉坑”次数;

Requests 官方提供中文文档。这对于新人,尤其是英语能力还不是很好的新人来说,是最好的资源。官网文档提供了详细而且非常准确的函数定义与说明。如果开发过程中出现了问题,百度、Google、Stack Overflow……所有的搜索方法都试过,但是都不能解决问题的时候,翻阅官方文档是最稳妥,而且是最快捷的解决方案。
Requests 初体验
安装前面已经讲过了,这里再复述一遍。
代码如下:
pip install requests尝试一下这一段代码:
# 以下的代码很好理解。
import requests
# 第一行代码导入了 Requests 这个库,导入库我们基本上都用这个方法,当然还有 from...import...
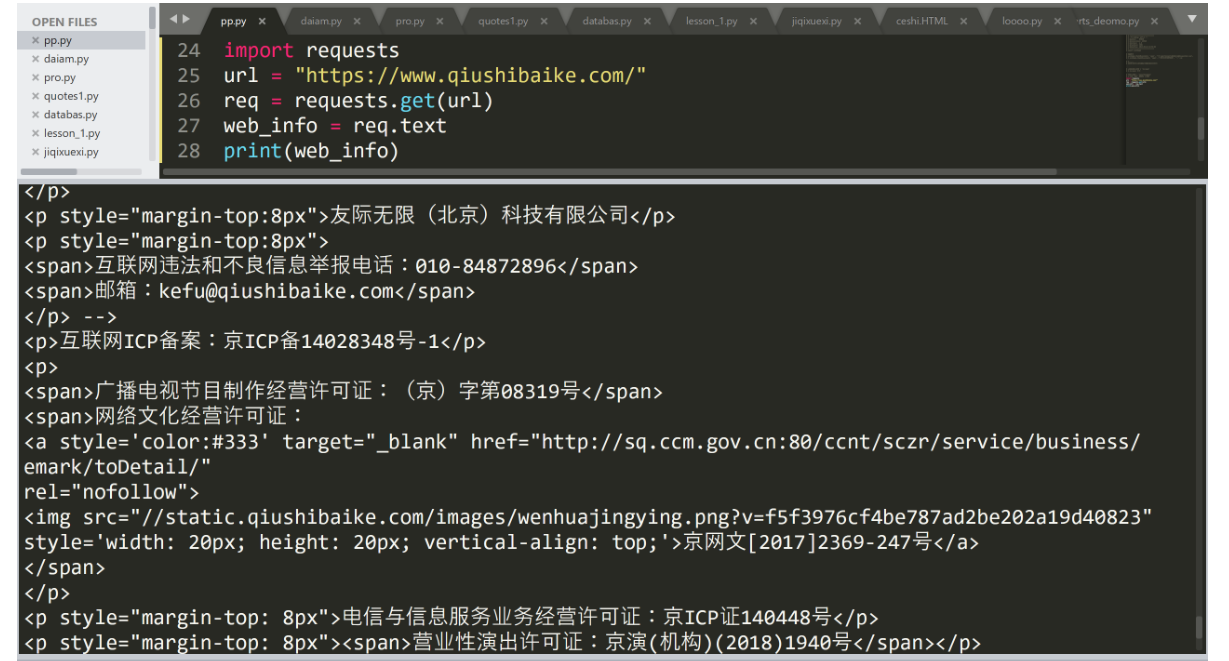
url = "https://www.qiushibaike.com/"
# 第二行代码定义了我们要爬取的 URL
req = requests.get(url)
# 第三行,我们直接调用 Requests 中的 get() 方法,即通过 GET 访问一个网页:
web_info = req.text
# 当我们发出 GET 请求后,Requests 会基于 HTTP 头部对相应的编码做出有根据的推测,所以当我们访问 req.text 之前,Requests 会使用它推测的文本编码进行解析。
print(web_info)
# 打印出来。运行:
定制请求头
什么是请求头呢?HTTP 请求头,HTTP 客户程序(例如浏览器)向服务器发送请求的时候必须指明请求类型(一般是 GET 或者 POST)。如有必要,客户程序还可以选择发送其他的请求头。上面我们有提到过,我们一般写爬虫都会写这个,可以理解成你得给你的爬虫穿一件衣服,总不能直接“裸奔”到人家网站吧。
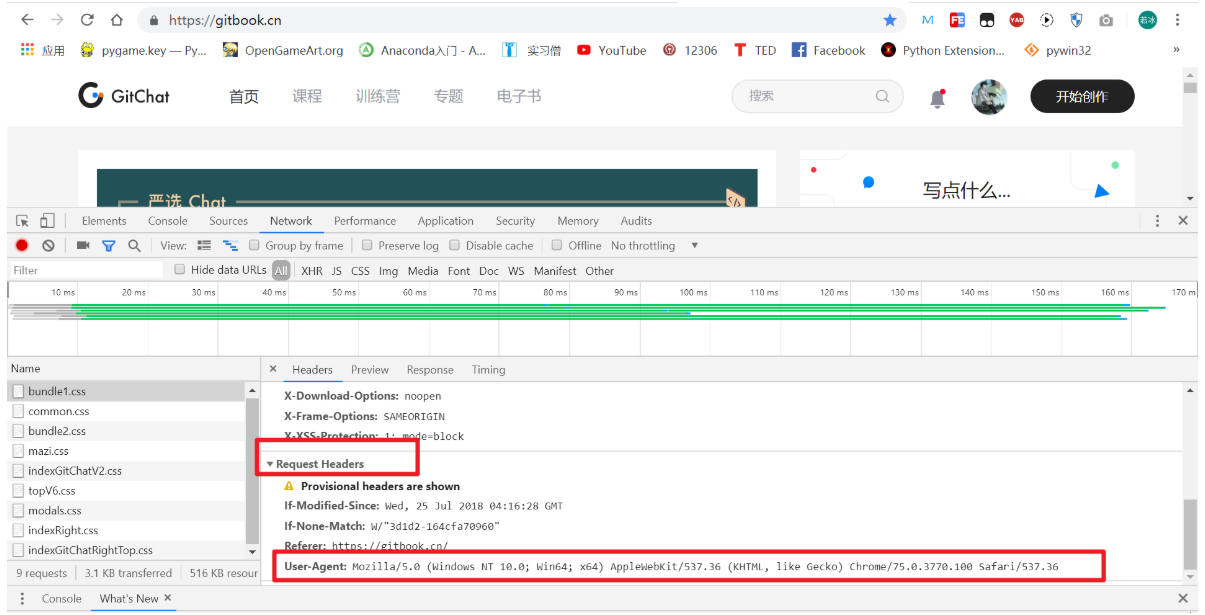
上图就是一个典型的请求头。在 Request 中,我们可以很方便地构造自己需要的请求头。代码如下:
# 我们一般直接复制浏览器中的请求头
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
# 使用也是很简单的
import requests
url = "https://www.qiushibaike.com/"
# 就这样使用就可以
req = requests.get(url, headers = header)
web_info = req.text
print(web_info)6.3 Beautiful Soup
Beautiful Soup 介绍
爬虫利器,出色的解析工具。
安装前面也讲过,我们回顾一下代码:
# 安装方式,在命令行中输入
pip install lxml
pip install beautifulsoup4
# Mac用户输入
pip3 install lxml
pip3 install beautifulsoup4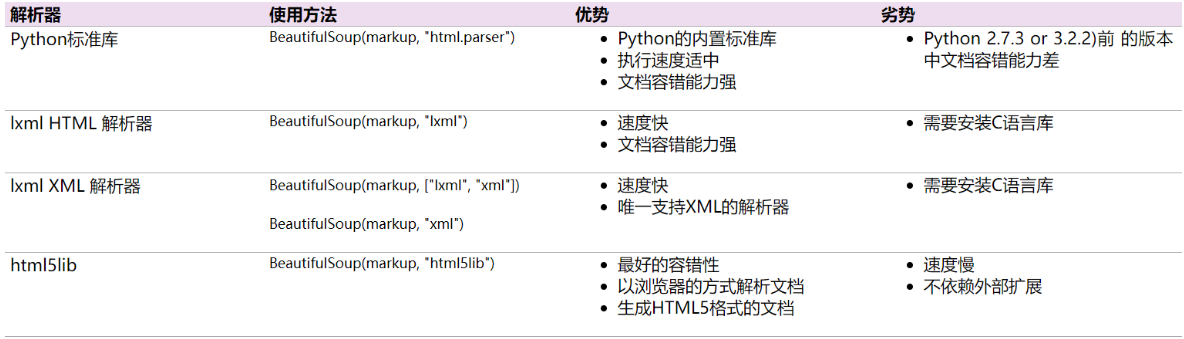
(图片来源网络)
注意如何导入时的模块名称:

我们需要的是 bs4 里的 BeautifulSoup 模块。
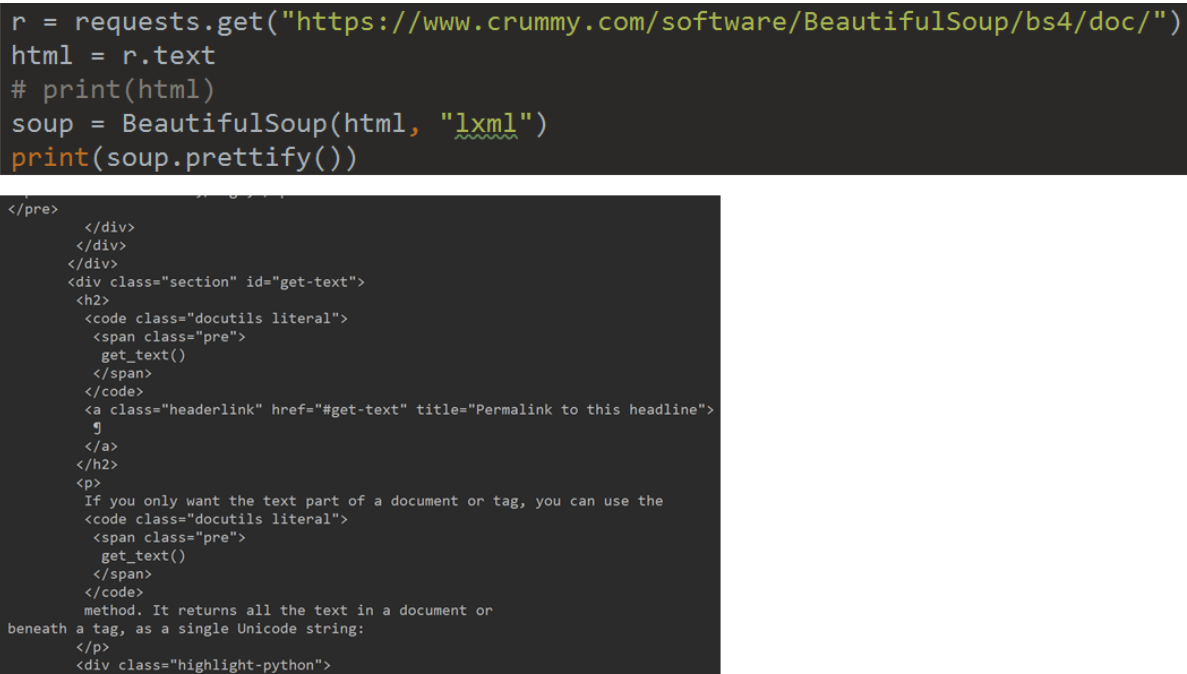
一个例子:prettify() 格式化输出
BeautifulSoup 快速开始
废话不多说,我们还是通过一个例子来进行详细的讲解。代码如下:
from bs4 import BeautifulSoup
import requests
url = "https://www.qiushibaike.com/"
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
req = requests.get(url, headers = header)
soup = BeautifulSoup(req.text, 'lxml')
title = soup.title
print(title)soup = BeautifulSoup(req.text,'lxml')使用 BeautifulSoup 解析我们使用 Requests 爬取到的网页内容 req.text,并且使用 lxml 解析器对其进行解析。
这是我们使用 BeautifulSoup 框架时最常用的一行代码。如果你实在是不了解其内在机制的话(没事,刚刚入门)。
通过这行代码,我们能够得到一个 BeautifulSoup 的对象 。接下来我们所有的网页获取都是操作这个对象来进行处理。BeautifulSoup 将复杂的 HTML 代码解析为了一个树形结构。每个节点都是可操作的 Python 对象,常见的有四种。
四大对象种类:
- Tag
- NavigableString
- BeautifulSoup
- Comment
接下来我们对其进行一一介绍。
1. Tag
Tag 就是 HTML 中的一个个标签。
注意:返回的是第一个符合要求的标签(即使 HTML 中有多个符合要求的标签)。
这个标签也是我前面写道的网页基础!
例如:
title = soup.title上述代码是获取网站的标题。运行后得到的结果是:

Bingo!我们可以直接通过 soup.tag 获取对应的 HTML 中的标签信息!
让我们看一下 HTML 网页中的一个比较特别的 Tag。
<meta name="keywords" content="笑话,搞笑,笑话大全 爆笑,笑话大全,糗事百科,幽默笑话,爆笑笑话" />
<meta name="description" content="糗事百科是一个原创的糗事笑话分享社区,糗百网友分享的搞笑段子、搞笑图片大全,都是糗友最珍贵的开心经历,爆笑糗事笑话只在糗事百科!"/>
一般来说,description 和 keywords 是一个网页的关键信息之一。具体的,如果你只是想获取这个网页的大概内容,那么我们可以直接获取这两个标签中的信息就可以了。我们可以运行如下代码:
from bs4 import BeautifulSoup
import requests
url = "https://www.qiushibaike.com/"
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
req = requests.get(url, headers = header)
soup = BeautifulSoup(req.text, 'lxml')
title = soup.title
description = soup.find(attrs={"name": "description"})
keywords = soup.find(attrs={"name": "keywords"})
print(title)
print(description)
print(keywords)运行结果:
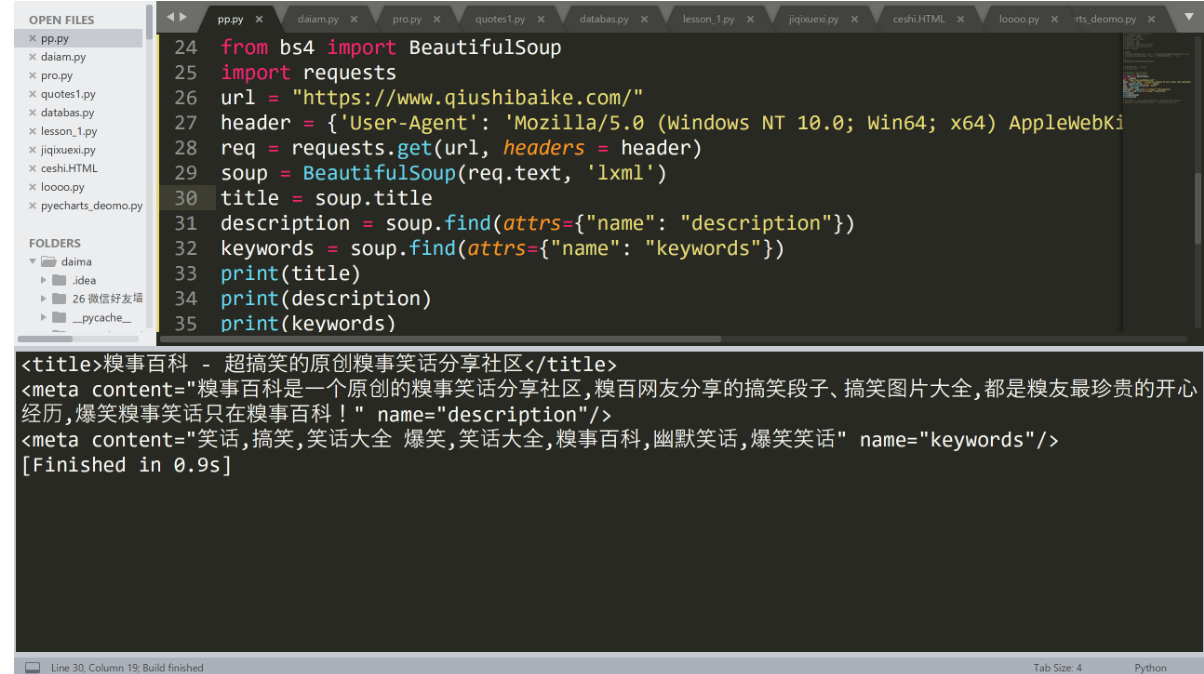
你会发现上面获取到的内容是都带有标签的。
2. NavigableString
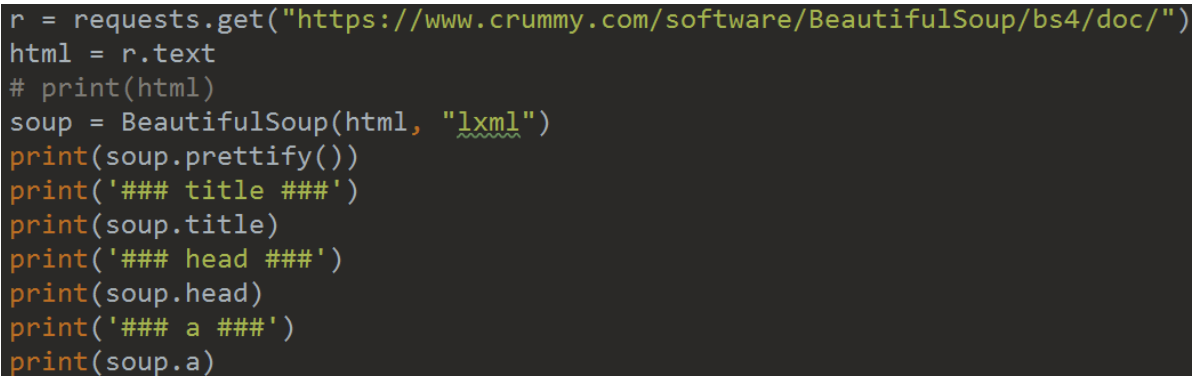
希望你可以自行敲这些代码感受感受:
- attrs:获取标签的元素属性
- get() 方法:获取标签的某个属性值
可以通过修改字典的方式对这些属性和内容等进行修改、删除等操作。
print(soup.a.attrs)
print(soup.a['title'])
print(soup.a.get('title'))
soup.a['title'] = "a new title"NavigableString 获取某个标签里面的内容:

由上面的代码你可以看到,既然能够获取到标签,那么如何获取标签的内容呢?很简单,细心的小伙伴肯定能发现我上面加了 string 就可以啦!
3. Comment
Comment 对象是一个特殊类型的 NavigableString 对象,但是当它出现在 HTML 文档中时,如果不对 Comment 对象进行处理,那么我们在后续的处理中可能会出现问题。HTML 中可以用来添加一段暂不通过网页渲染出来的内容。

接下来我们来观察这个 HTML:
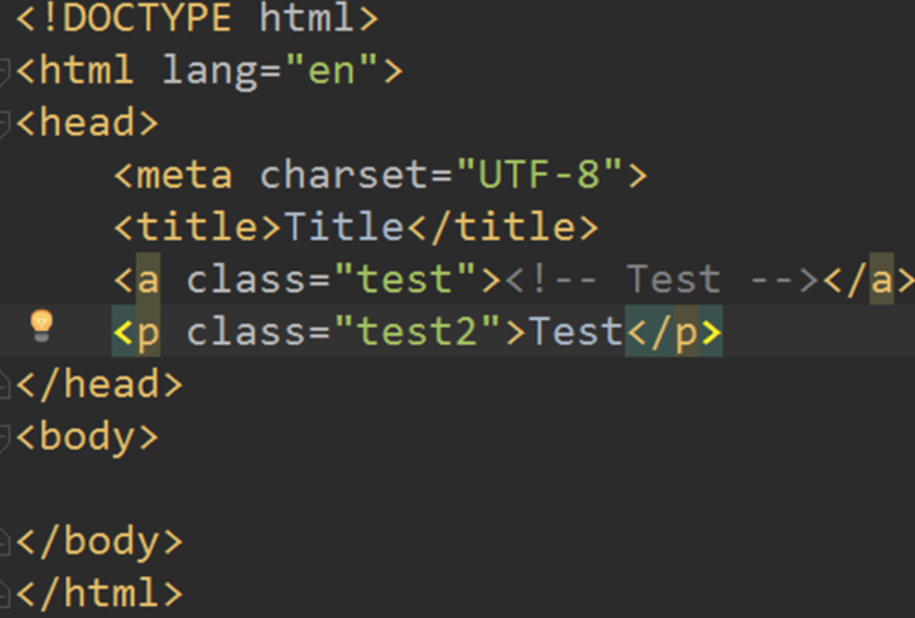
做出如下操作:
我们来看看输出结果是:
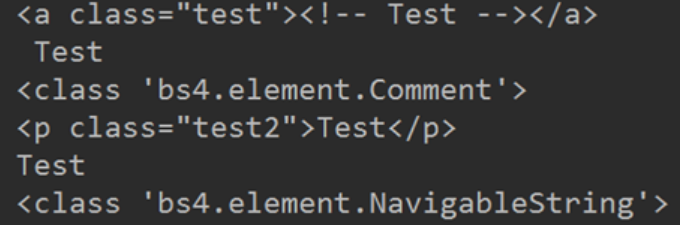
我们会发现其中,有个 comment。
4. BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容。大部分时候,可以把它当作 Tag 对象,它支持遍历文档树和搜索文档树中描述的大部分的方法。代码如下:
print(type(soup))
print(soup.name)
print(soup.attrs)文档树——直接子节点
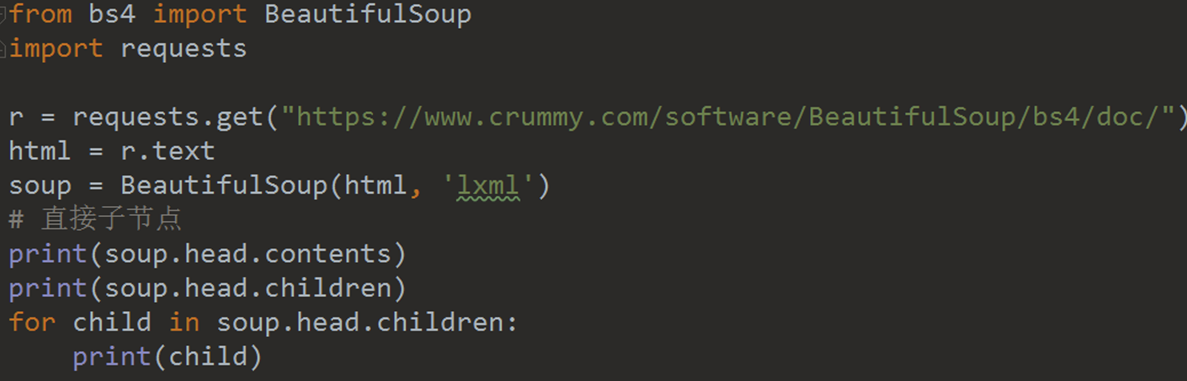
注意观察 .contents 和 .children 的区别。
希望大家认真观看上面的脑图。
文档树——所有子孙节点
.descendants 把某个标签内的所有子孙节点都列出来,可以通过 for 循环来进行处理:

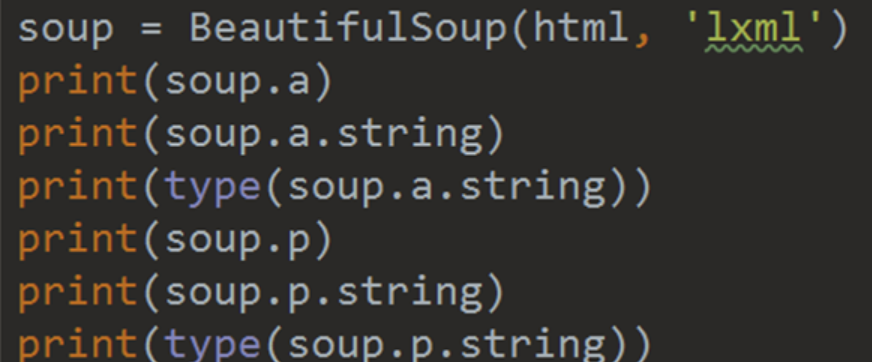
文档树——节点内容
soup.a.string 与 soup.p.string 的输出是一样的。
注意:如果 tag 包含有多个(能够调用 .string 的)节点,.string 方法会返回什么?None。
注意!空格和换行都算一个节点!
如果想要获得一个 tag 下面的多个内容,我们该如何操作?
.strings 或者 .stripped_strings:
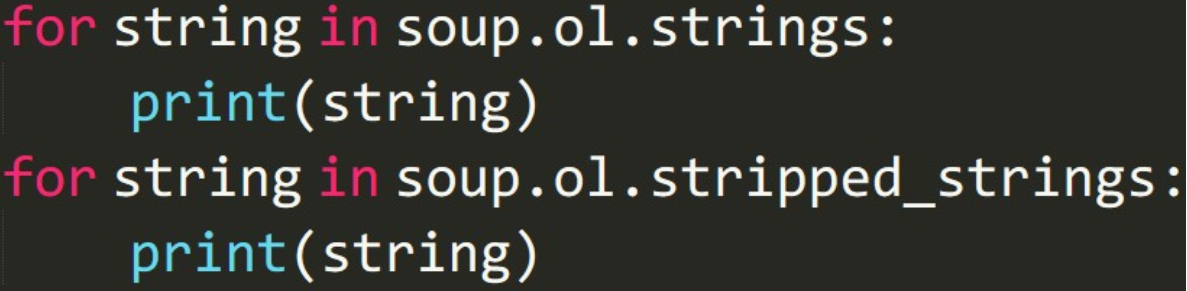
.strings 与 .stripped\_strings 区别:.stripped\_strings 可以去除多余空白内容。
搜索文档树——find_all
代码如下:
print(soup.find_all('a'))find_all() 里可以直接填的参数:
- 标签名称,比如 a, p, h1 等
- 列表,比如 [‘a’, ‘p’]
- True,找出所有子节点
- 正则表达式
keyward 参数:
find_all (标签内属性名 = 属性值)

如果要找 class 请注意写成 class_ 因为 class 是 Python 自带的关键词。
6.4 CSS 选择器
代码如下:
soup.select('title')
soup.find_all('title')
soup.select('a')
soup.find_all('a')
soup.select('.fooyer')
soup.find_all(True, class_ = 'footer')
soup.select('p #link')
soup.find_all('p', id = 'link')
soup.select('head > title')
soup.head.find_all('title')
soup.select('a[href = "www.baidu.com"]')
soup.find_all('a', href = 'www.baidu.com')
soup.select() 筛选元素, 返回的是 list语法规则:
- 标签名不加任何修饰
- class 名前加点
. - id 名前加
#
6.5 BeautifulSoup 实战
上面涉及到了太多的理论知识,实在是“太过枯燥”。我个人比较喜欢实战,不过理论也是很重要滴,现在让我们在实战中学习 BeautifulSoup 吧!
我们今天爬取的网站是糗事百科:https://www.qiushibaike.com。
我们要爬取这个网站的文字笑话。
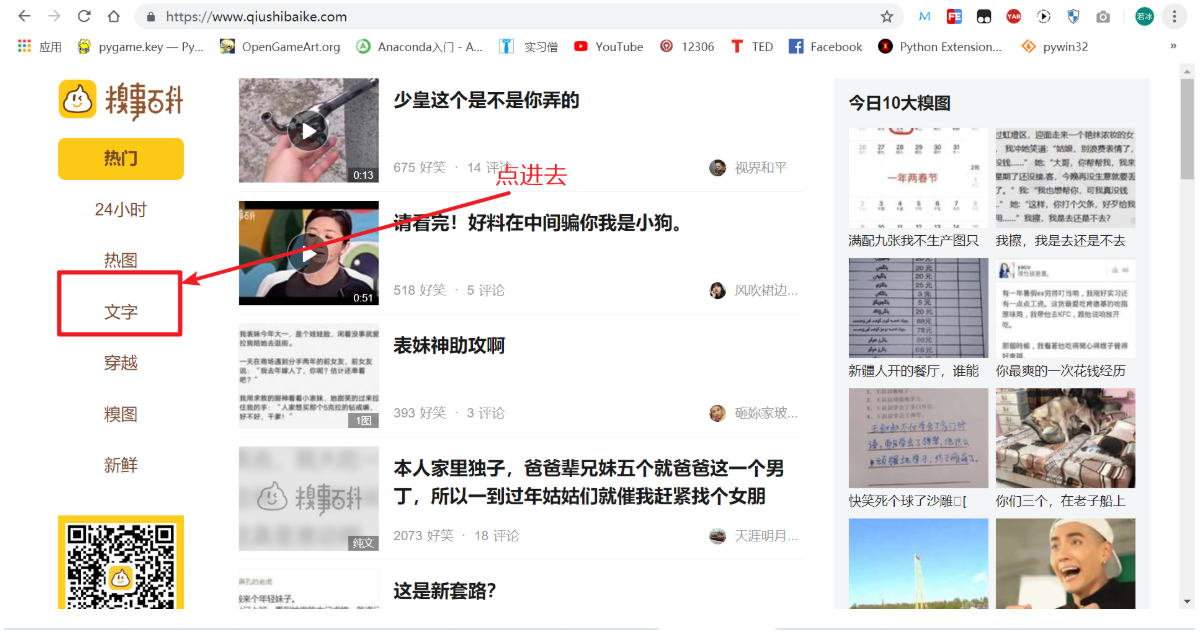
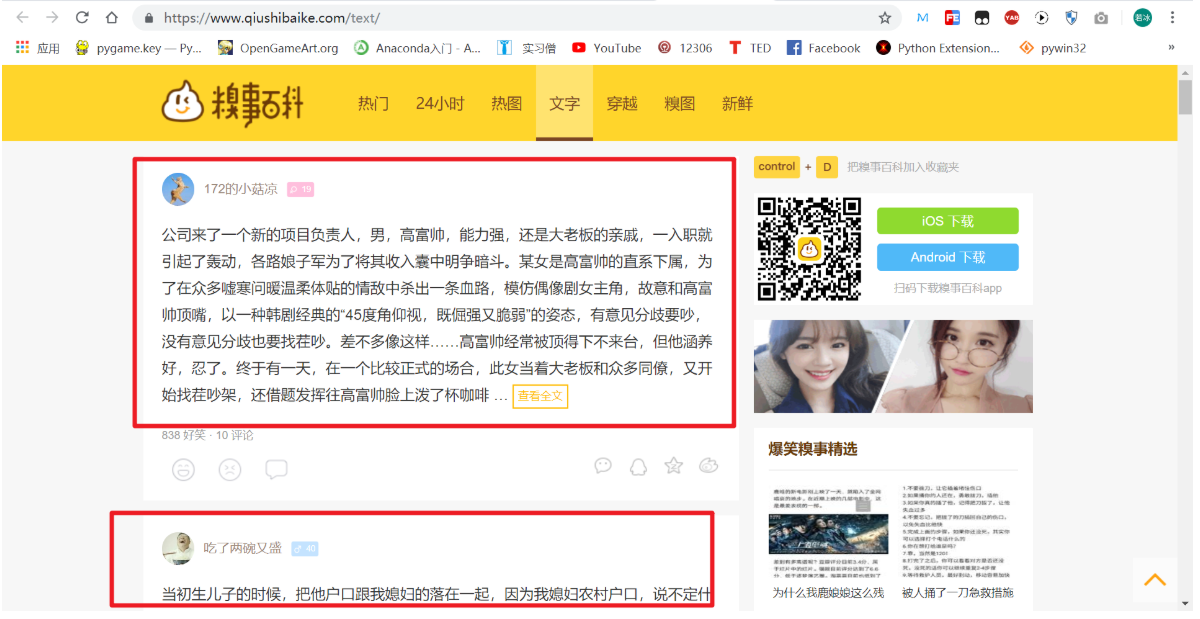
这里的一条条笑话,就是我们要爬取的内容。
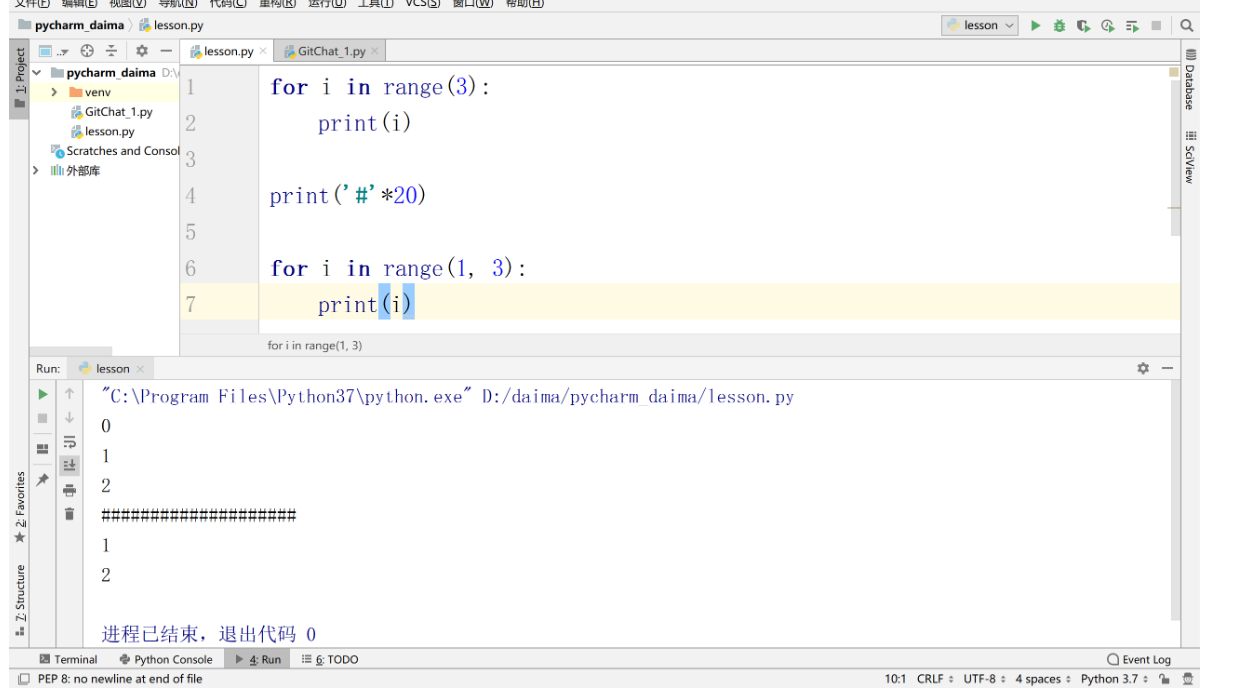
1. 分析爬取网页 URL 规律
因为,我们要抓取好几页,所以先分析一下这个网页中文字的 URL 规律:
- 第一页:https://www.qiushibaike.com/text/
- 第二页:https://www.qiushibaike.com/text/page/2/
- 第三页:https://www.qiushibaike.com/text/page/3/
很直观,文本中的网页变化就是 page 之后的数字所以我们可以用 for 循环来操作。
一个小知识点:
基础操作运行如下代码:
import requests
from bs4 import BeautifulSoup
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
url = 'https://www.qiushibaike.com'
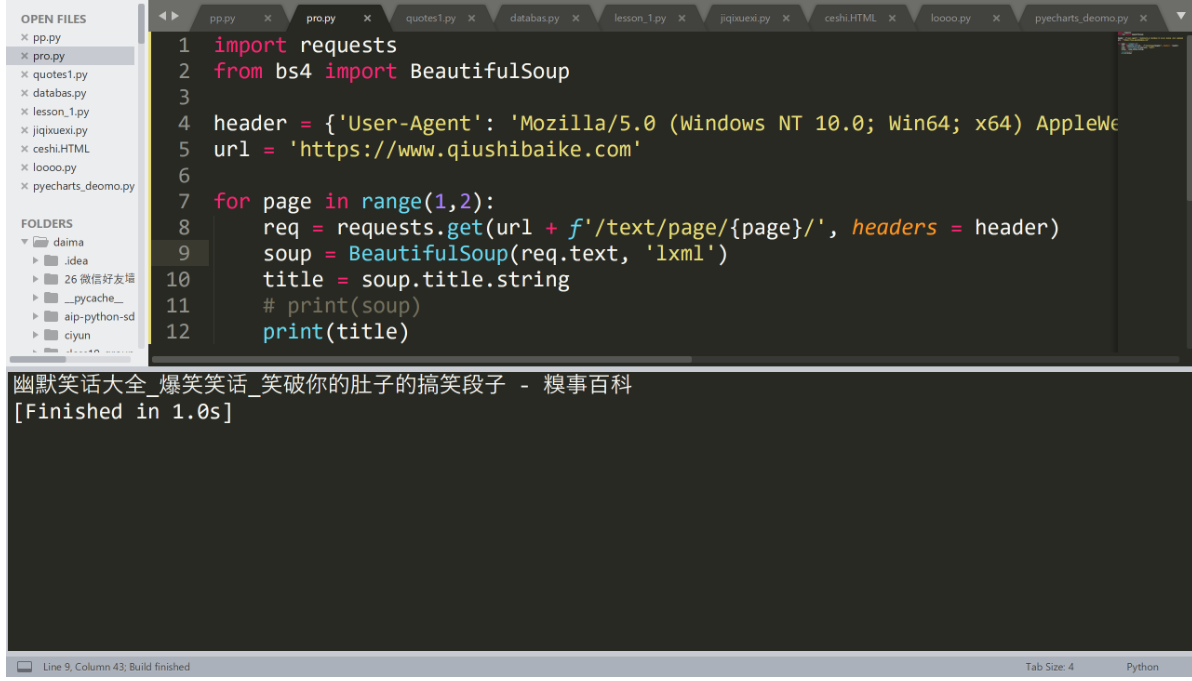
for page in range(1,2):
req = requests.get(url + f'/text/page/{page}/', headers = header)
soup = BeautifulSoup(req.text, 'lxml')
title = soup.title.string
# print(soup)
print(title)Sublime Text3 运行代码的快捷键是 Control + B:
2. 用 select() 函数定位指定的信息
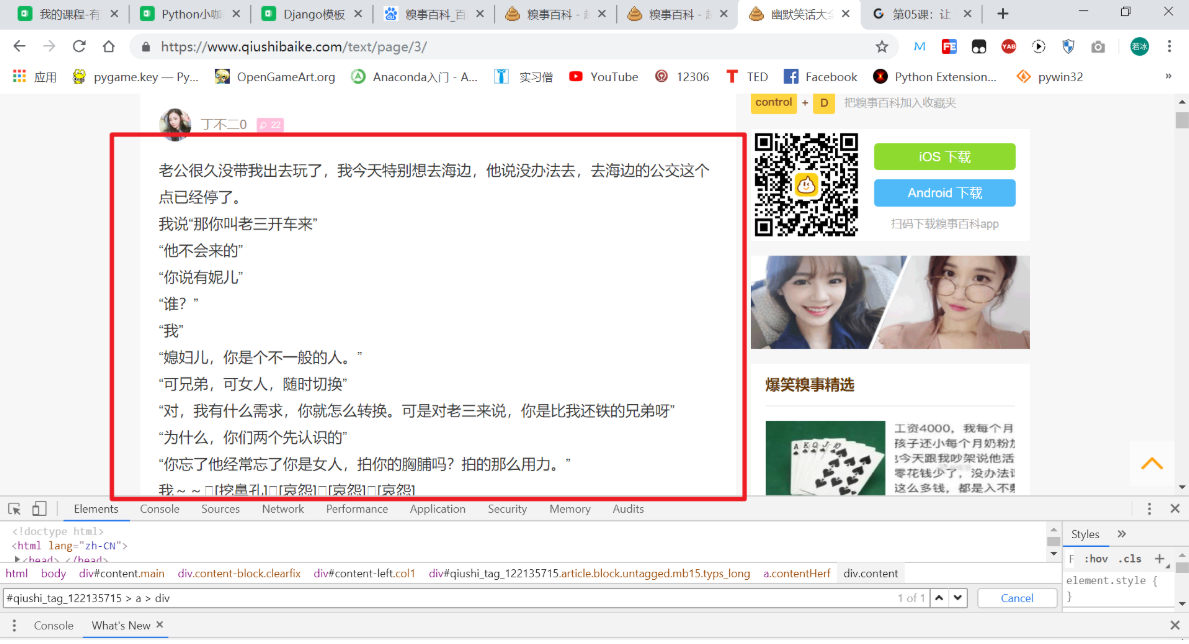
如上图所示,我们想要爬取右上角的“这个笑话内容”,该怎么操作呢?
代码如下:
laugh_text = soup.select('#qiushi_tag_122135715 > a > div')在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数,即可使用 CSS 选择器的语法找到 Tag。
使用 .select() 方法可以帮我们定位到指定的 Tag。那么,我们该如何确定这个指定的位置呢?让我们看一下 GIF 图片吧!
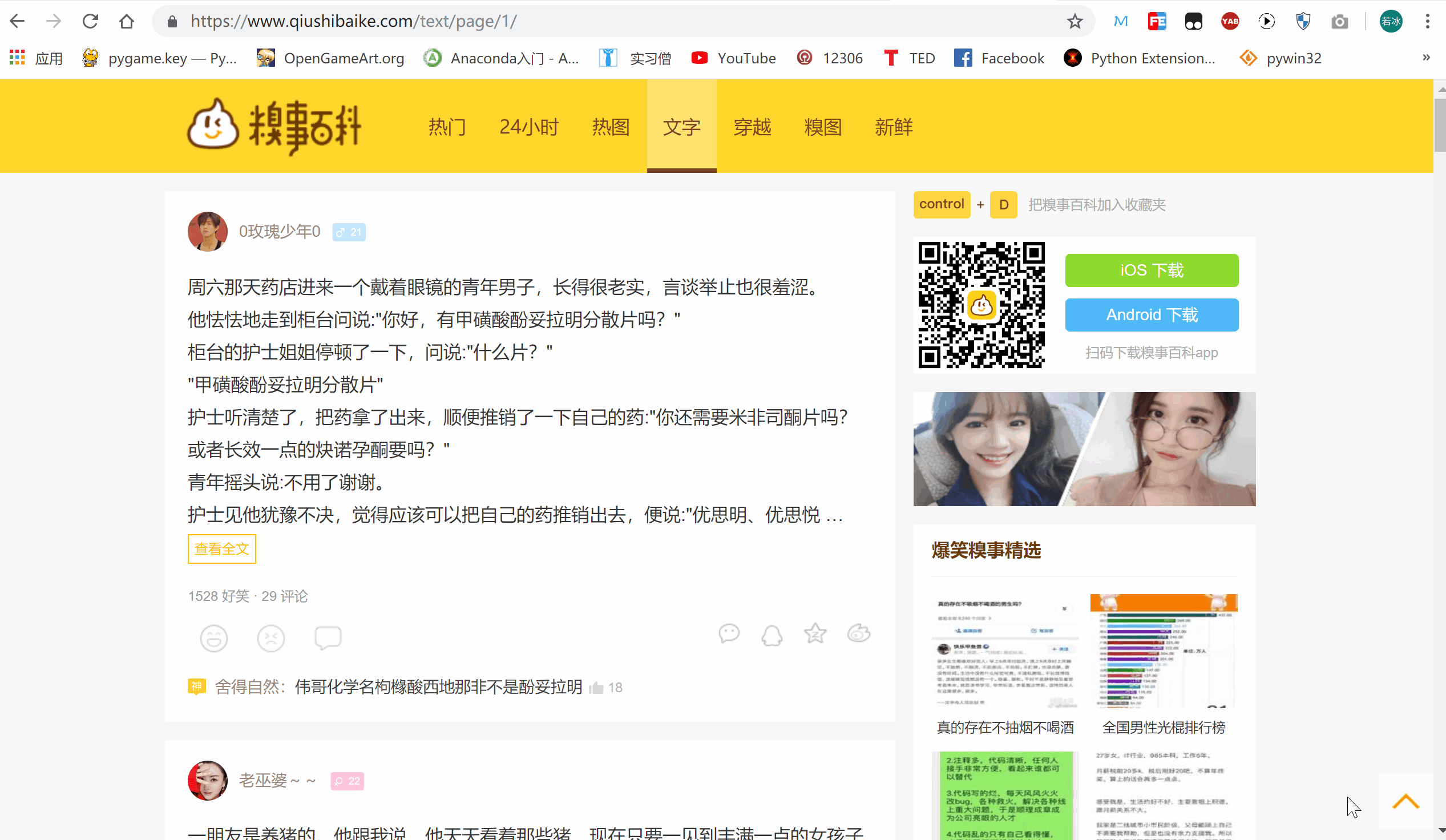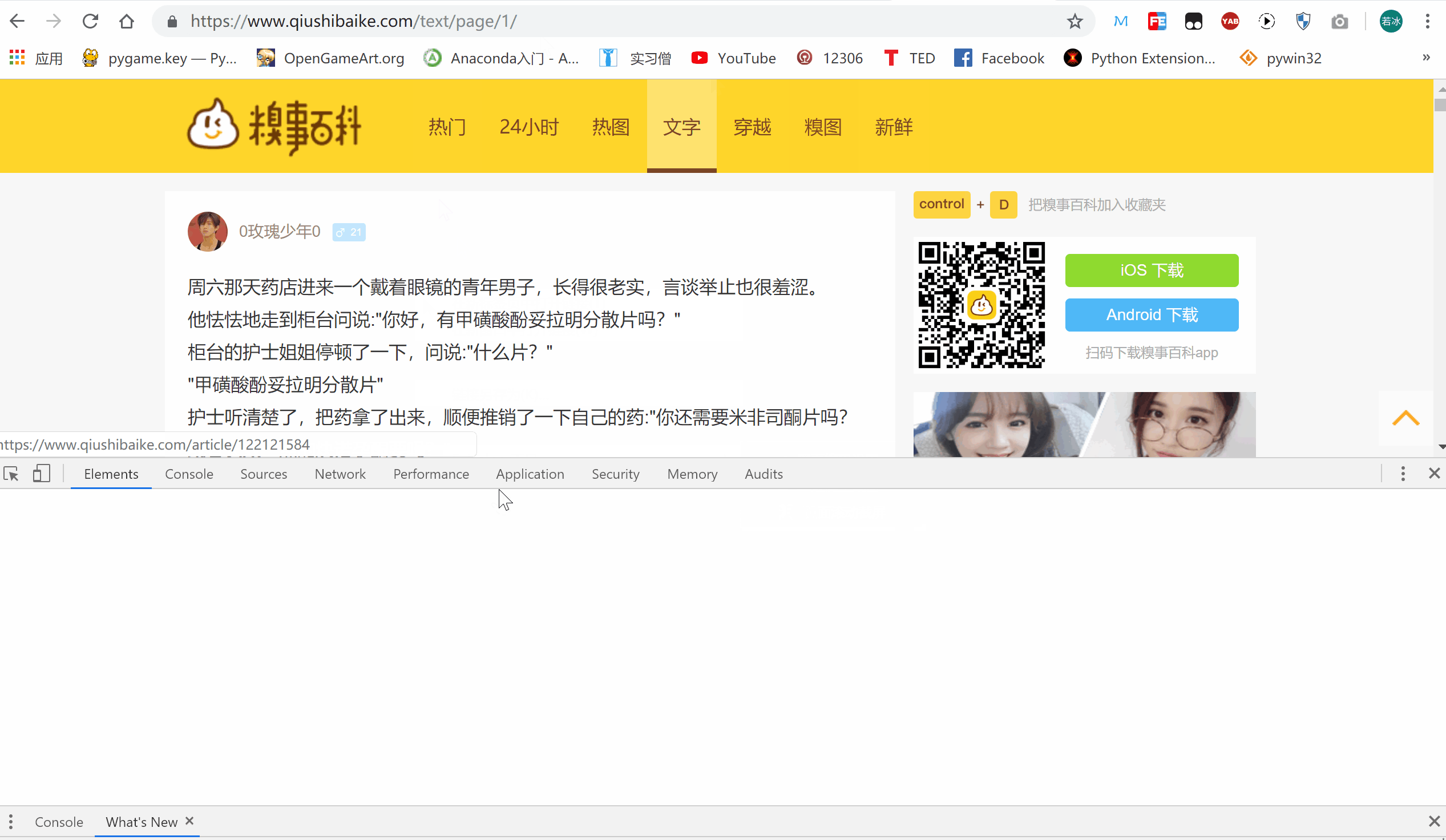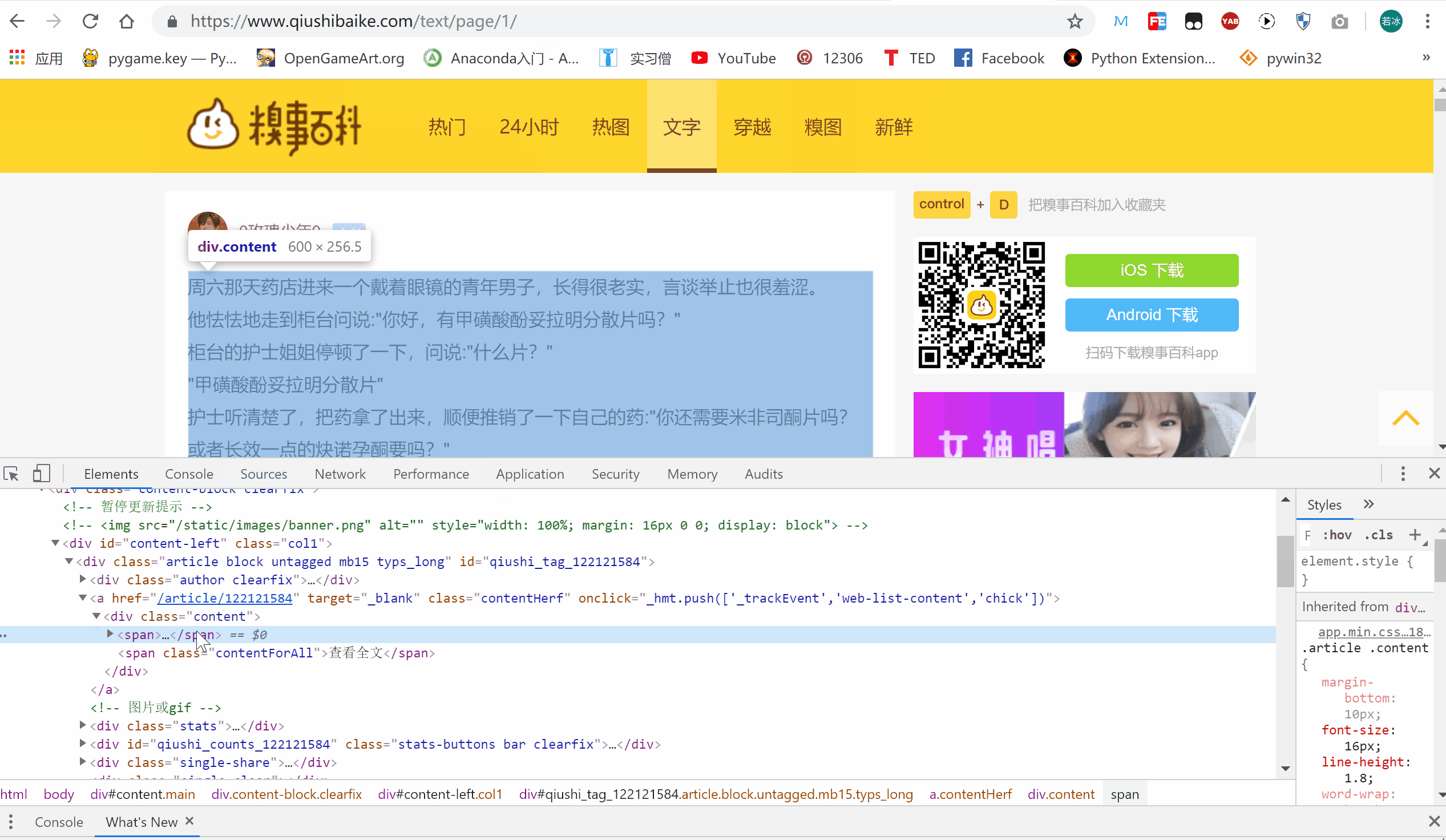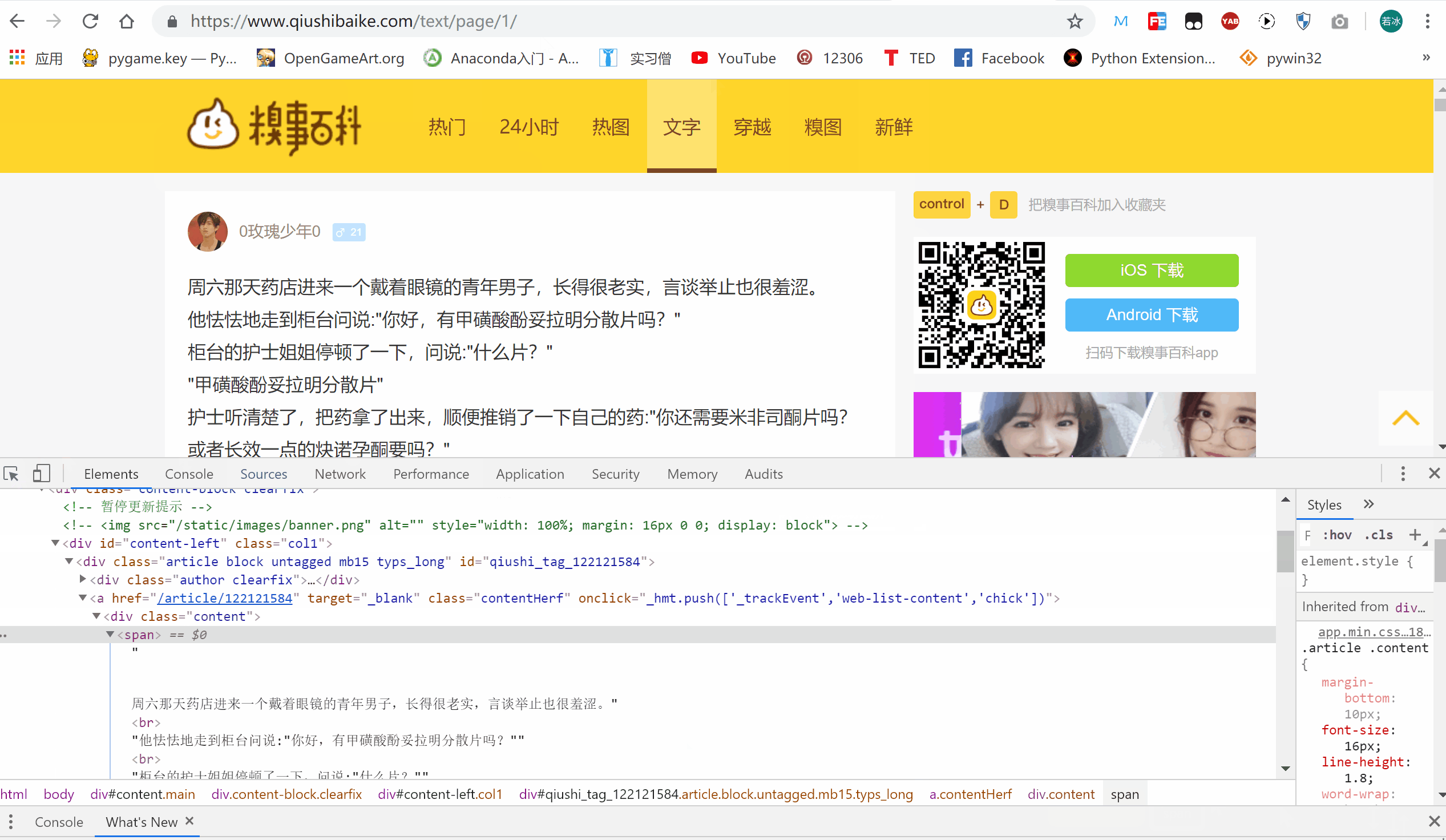
具体地,我们首先将鼠标放在所要定位的文字上,接下来,进行如下操作:
- 右击鼠标,选择 “检查”
- 在弹出的检测台中,选定对应的文字
- 使用定位器,看 GIF 我定位我想要的数据的操作
- 接下来我们分析一下,并写 CSS 选择器
我们发现,它在一个 div 里面的 class = content 下面中的 span 标签里面。所以,我们这么写 CSS 写入代码试一试:
.content span运行如下代码:
import requests
from bs4 import BeautifulSoup
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
url = 'https://www.qiushibaike.com'
for page in range(1,2):
req = requests.get(url + f'/text/page/{page}/', headers = header)
soup = BeautifulSoup(req.text, 'lxml')
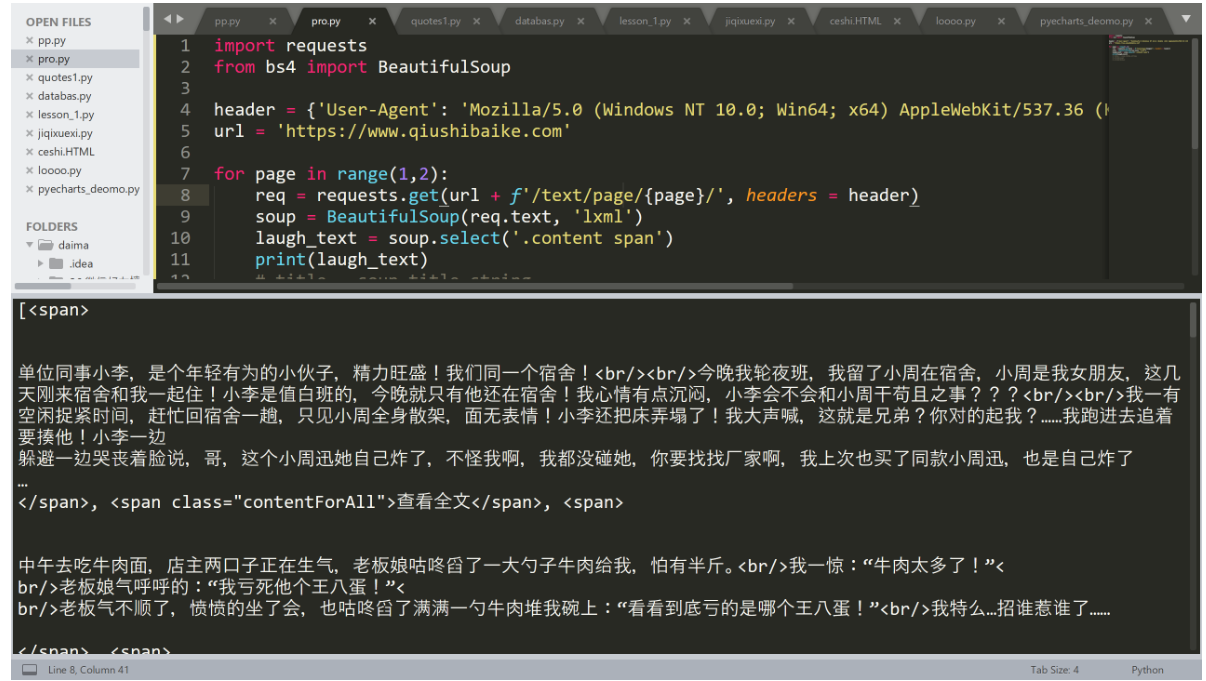
laugh_text = soup.select('.content span')
print(laugh_text)
# title = soup.title.string
# print(soup)
# print(title)我们来运行试一试:
如果只想得到 Tag 中包含的文本内容,那么可以用 get_text() 方法,这个方法获取到 Tag 中包含的所有文版内容包括子孙 Tag 中的内容。
我们加入 get_text() 试一试,代码如下:
import requests
from bs4 import BeautifulSoup
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
url = 'https://www.qiushibaike.com'
for page in range(1,5):
req = requests.get(url + f'/text/page/{page}/', headers = header)
soup = BeautifulSoup(req.text, 'lxml')
laugh_text = soup.select('.content span')
# 因为得到的是一个列表,所以需要用 for 循环遍历
for laugh in laugh_text:
print(laugh.get_text())
# print(laugh_text)
# title = soup.title.string
# print(soup)
# print(title)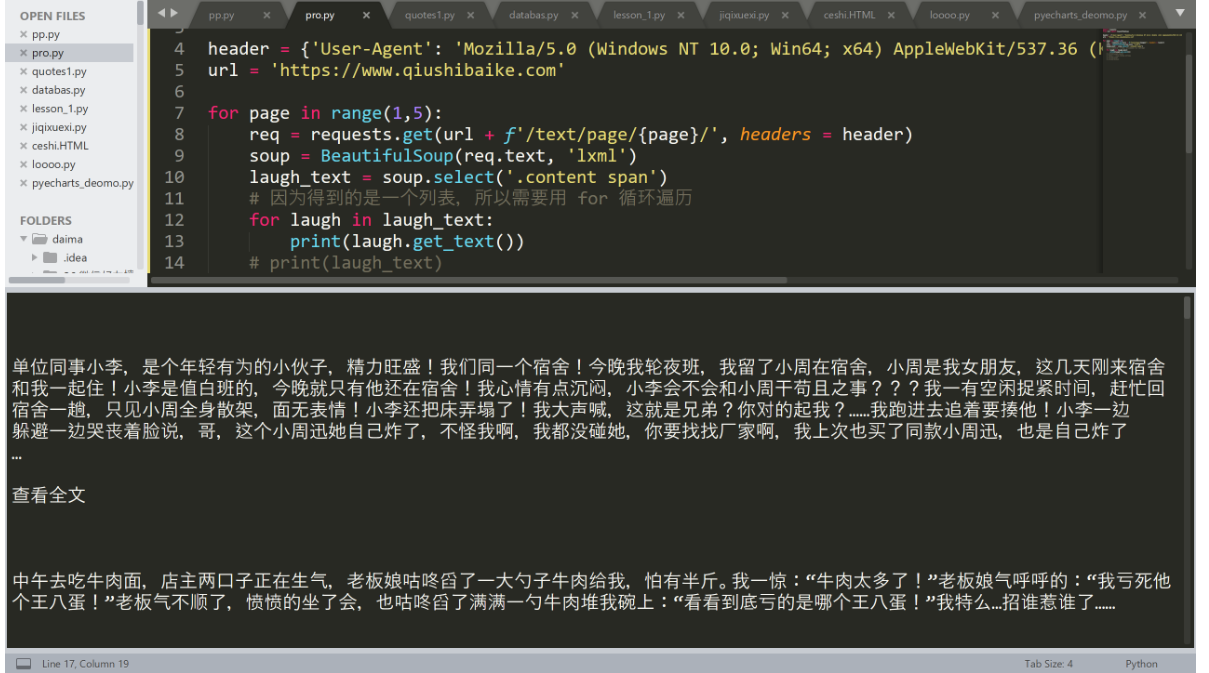
当然我们还可以直接用 text、strings、stripped_string,都是可以的。
3. 使用 .get() 获取指定属性
假设 HTML 中有如下的代码:
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>我们如何获取到里面的文字呢?没错,直接使用 .get_text() 函数就可以了。
那么,如果我们只想获取它的 URL 地址呢?或者它所对应的 class 名字呢?这就需要我们使用 .get() 函数。
先用 select 选择到,然后使用 get:
# .get("class")
# .get("href")实战总结
- 如何获取网页信息在 HTML 中对应的位置,如何使用 Chrome 浏览器获取到对应的 selector
- .get_text() 函数的使用
- 当然,我们还可以使用 text、strings、stripped_string
- .get() 函数的使用
- 一定要浏览 BeautifulSoup 的官方文档
七、爬虫专用库 Scrapy 基础

(图片来源于网络)
7.1 Scrapy 原理介绍及安装
Scrapy 原理介绍
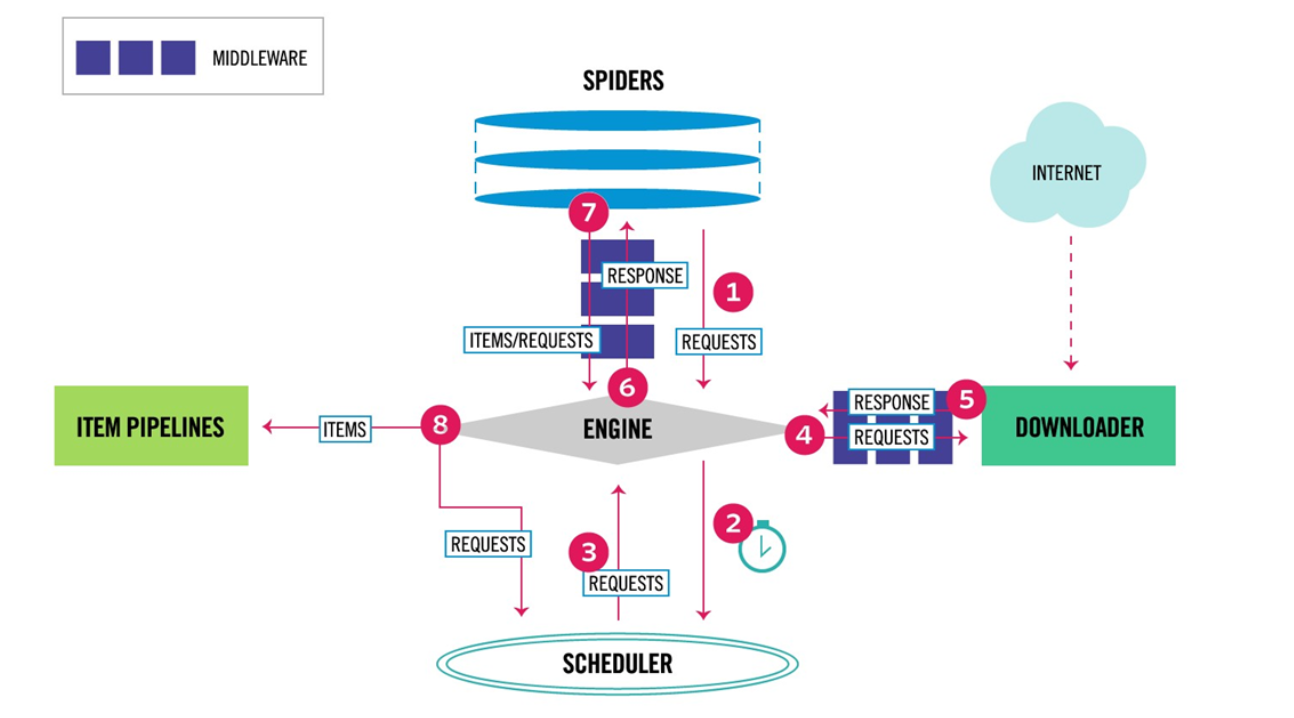
(图片来于网络)
- 引擎(Scrapy Engine): Scrapy 的核心
- 调度器(Scheduler):先简单理解,一个领导分配任务,充分发挥每个员工的职能
- 下载器(Downloader):就下载器咯
- 蜘蛛(Spiders): 就是之前类似写实习僧一样的爬虫部分
- 项目管道(Item Pipeline):项目管道,清洗区域
具体功能:[2]
- Engine:引擎,处理整个系统的数据流、触发事物,是整个框架的核心。
- item:项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该 item 对象。
- Scheduler:调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求的时候,将请求提供给引擎。(可以理解为,调度器分配好任务 >>> 每个人做什么事情对应好,谁先谁后,然后反馈结果给引擎。
- Downloader:下载器,下载网页内容,并将网页内容返回给蜘蛛。(可以理解为,下载器下载后返回下载完的数据给蜘蛛,对比看我下载的数据对不对,是不是我要下载的内容有没有缺少之类的)。
- Spiders:蜘蛛抓取,里面定义了爬取的逻辑和网页解析的规则,它主要负责解析响应并生成提取结果和新的请求;(另一种说法:Spider 就是你要请求哪个网站,你需要爬取这个网站的哪个部分,就像前面抓取实习僧一样,是要职位名称、薪资、地点等。)
- Item Pipeline:项目管道,负责处理蜘蛛从网页中抽取的项目,它主要的任务是清洗、验证和存储数据。
- Downloader Middlewares:下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求和响应。
- Spider Middlewares:蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理向蜘蛛输入的响应和输出结果及其新的请求。(钩子你可以理解为:把引擎和蜘蛛连接捆绑起来)
总体流程:
Spriders >>> Engine >>> Scheduler >>> Engine >>> Downloader >>> Sprider >>> (如果返回的是新 URL )Downloader >>> 否则 Item Pipline
爬取流程:
针对每个 URL
Scheduler >>> Downloader >>> Spider >>> 调度器 >>> 下载器 >>> 蜘蛛 >>>
- 如果返回的是新的 URL,就会返回 Scheduler
- 如果是需要保存的数据,则会被放到 item pipeline 里面
扩展:数据流 [3]
Scrapy 中的数据流由引擎(Engine)控制,数据流过程如下:
- 首先,打开一个网站,找到处理该网站的 Spider,并向该 Spider 请求第一个要爬取的 URL;
- Engine 从 Spider 中获取到第一个要爬取的 URL,并通过 Scheduler 以 Request 的形式调度;
- Scheduler 返回下一个要爬取的 URL 个 Engine,Engine 将 URL 通过 Downloader Middlewares 转发给 Donwloader;
- 一旦页面下载完毕, Downloader 生成该页面的 Response,并将其通过 Downloader Middlewares 发送给 Engine;
- Engine 从下载器中接收到 Response,并将其通过 Spider Middlewares 发送给 Spider 处理;
- Spider 处理 Response , 并返回提取到的 Item 及新的 Request 给 Engine;
- Engine 将 Spider 返回的 Item 给 Item Pipeline,将新的 Request 给 Scheduler;
- 重复第 2 步到第 8 步, 知道 Scheduler 中没有更多的 Request,Engine 关闭该网站,爬取结束。
通过多个组件的相互协作、不同组件完成工作的不同、组件对异步处理的支持, Scrapy 最大限度的利用了网络带宽,大大提高了数据爬取和处理效率。
Scrapy 安装
方法一
Windows 系统:
pip install scrapyMac 系统:
xcode-select --install
pip3 install scrapy方法二——单步安装,先安装依赖
1. 安装 lxml
pip install lxml安装 pyOpenSSL (Wheel):
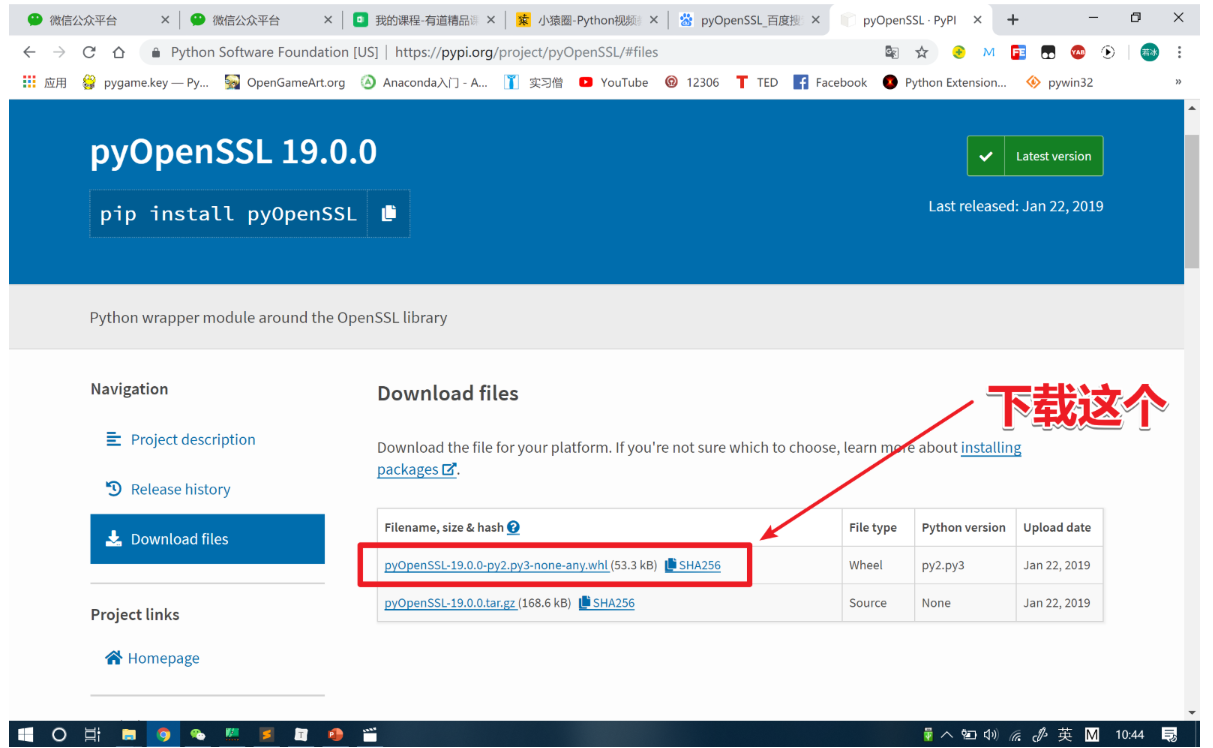
pip intall 刚刚下载的文件名称2. 安装 Twisted
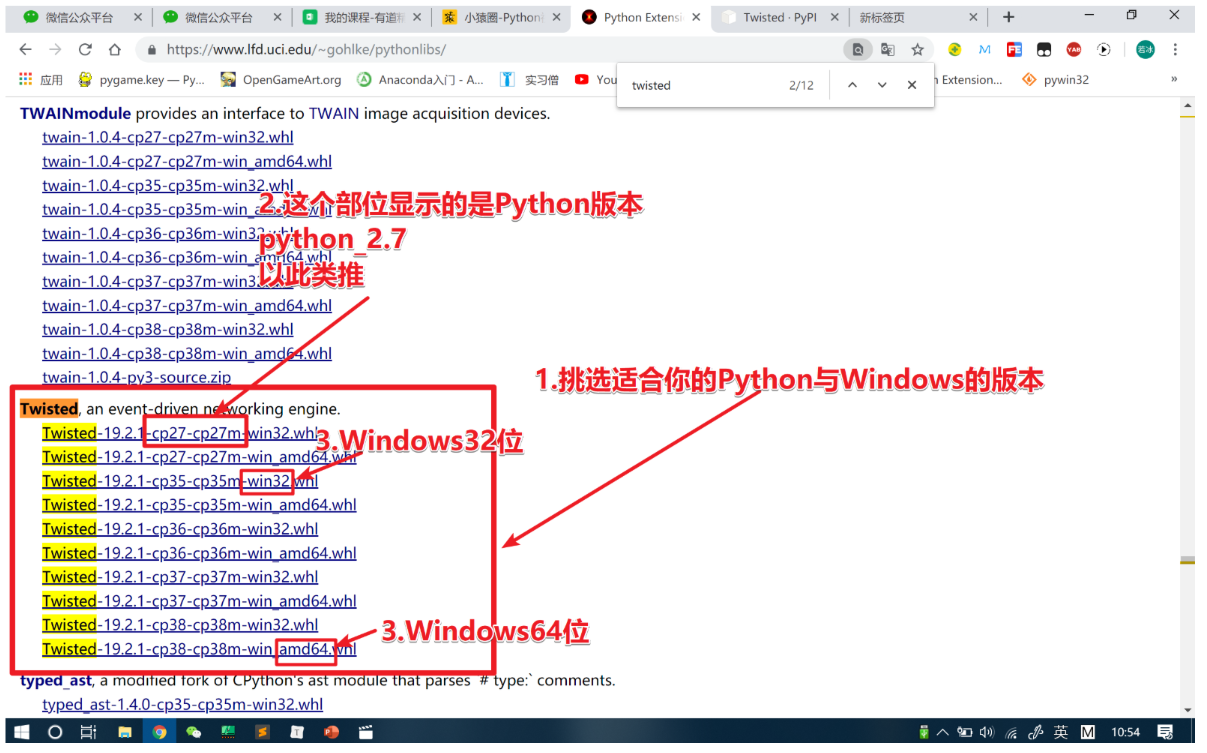
该页面的版本会有更新,注意选择适合版本即可!
pip intall 刚刚下载的文件名称3. 安装 PyWin32
pip install pywin32安装好依赖之后,可以安装 Scrapy 了。
pip install scrapy7.2 Scrapy 入门
创建项目
进入要存储代码的目录(命令行下),然后输入如下代码:
scrapy startproject tutorial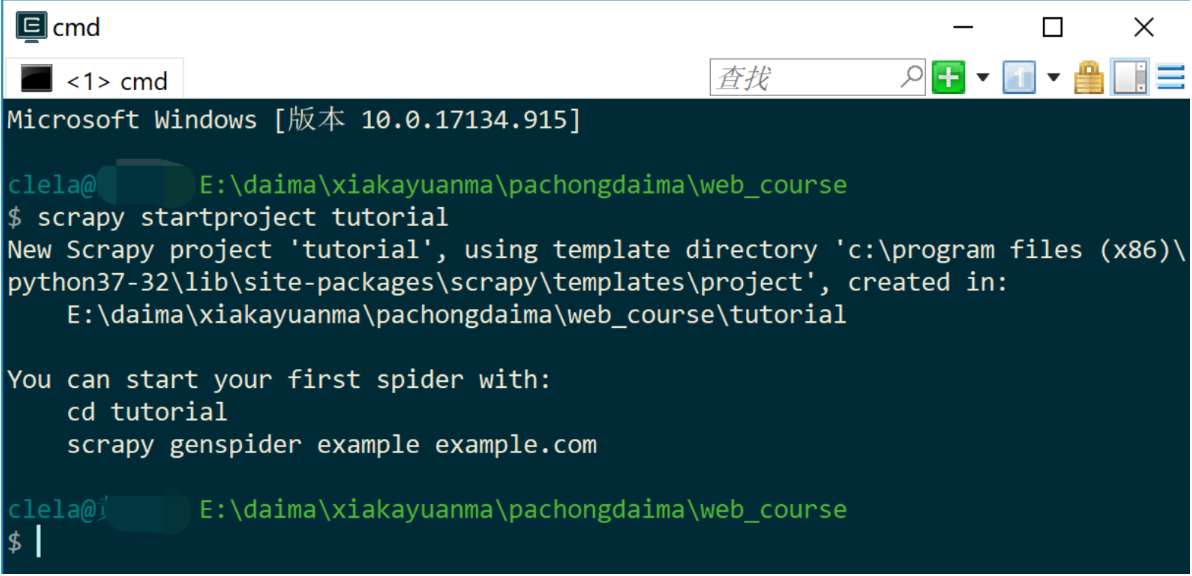
目录结构

准备工作做完了,咱们该做咱们的正题啦。
第一个 Scrapy 爬虫
咱们要爬取的 URL:http://quotes.toscrape.com/
进入网址查看一下:
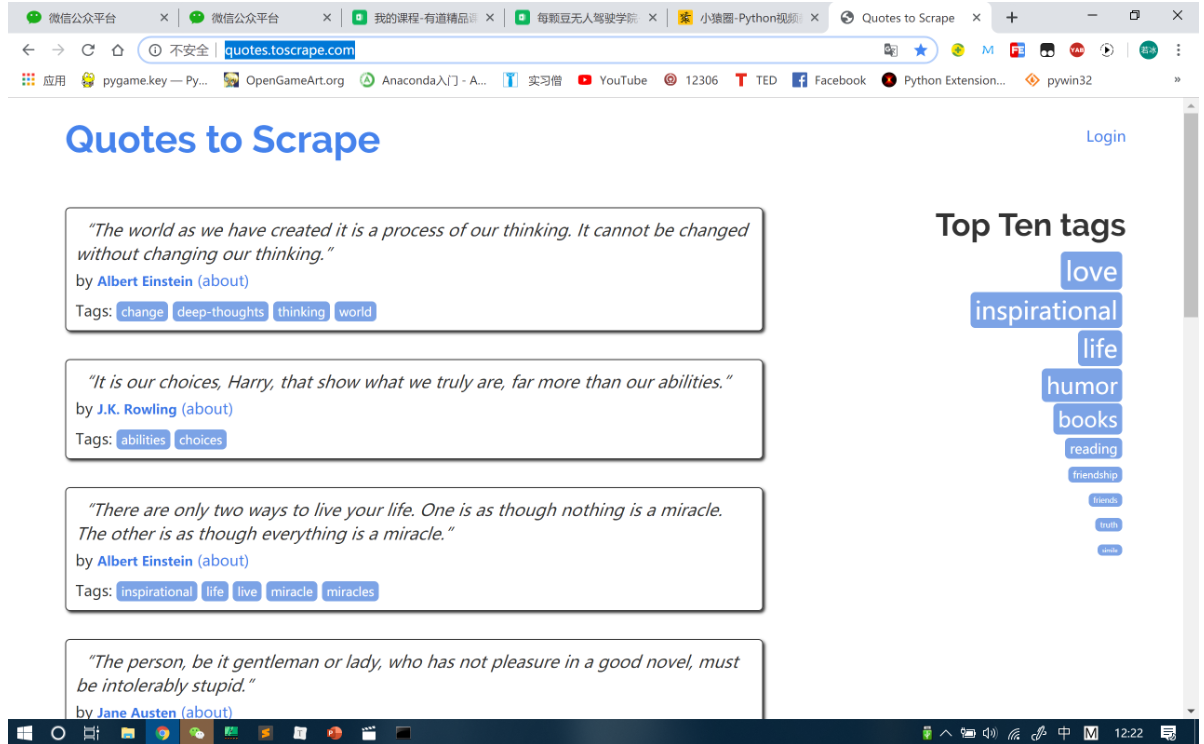
首先,咱们当然可以用前面爬取实习僧的方法爬取啦,直接上代码:
# -*8 coding: utf-8 -*-
# @Author: 黄家宝
# @Corporation: AI悦创
# @Version: 1.0
# @Function: 功能
# @DateTime: 2019-07-26 12:24:51
# ============================
import requests
from bs4 import BeautifulSoup
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
url = 'http://quotes.toscrape.com/'
# 爬取前5页吧:
for index, page in enumerate(range(1,6)):
req = requests.get(url + f'page/{page}/', headers = header)
soup = BeautifulSoup(req.text, 'lxml')
# print(soup)
title = soup.title.string
print(f'这是第{index + 1}篇,标题是:{title}') # 虽然标题一样,但写出来便于之后知道第几页
# 文章内容:
texts = soup.select('.text')
for index, text in enumerate(texts):
print(f'这是第{index + 1}条,\n{text.string}')
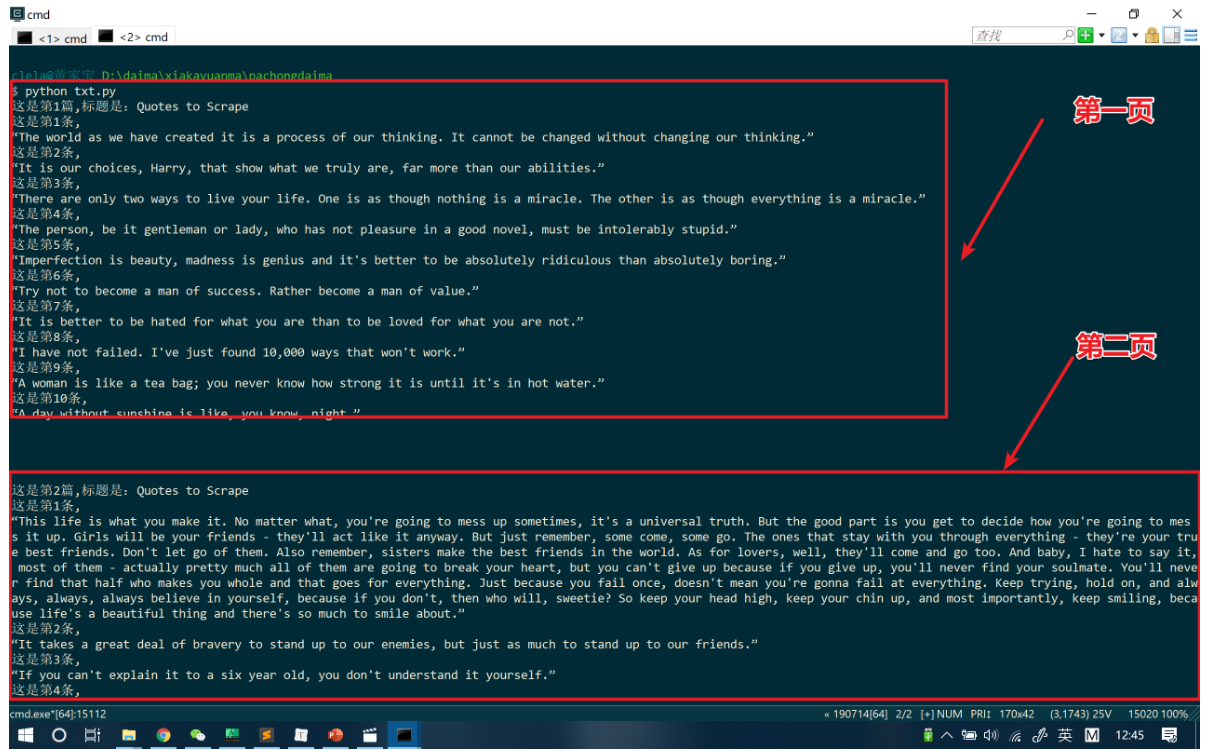
print('\n\n\n') # 为每个页面加空行区分,也可以用别的方法输出结果:(部分输出结果)
这个部分留给个小扩展,试一试接到百度翻译 API 把获取的的数据直接翻译!
接下来我们用 Scrapy 来试一试。
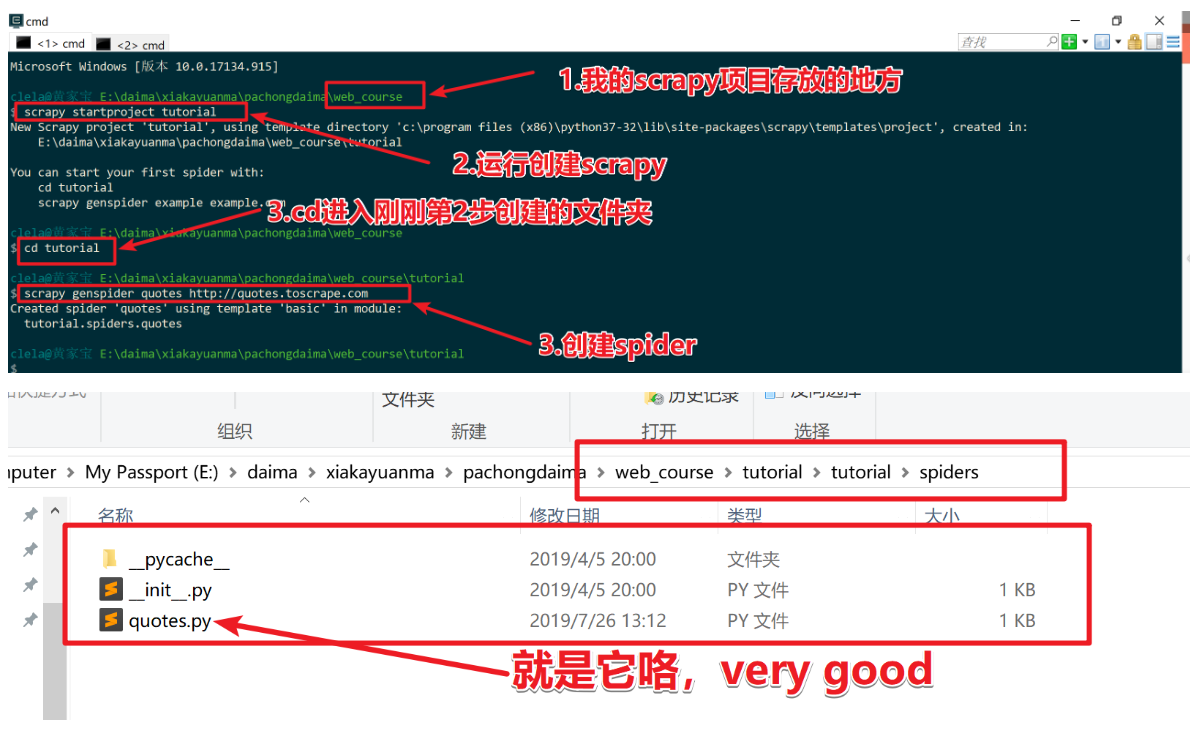
1. 创建 Spider
Spider 是自己定义的类,Scrapy 用它来从网页里爬取(抓取)内容,并解析抓取结果。不过这个类必须继承 Scrapy 提供的 Spider 类 scrapy.Spider,还要定义 Spider 的名称和起始请求, 以及怎样处理爬取后的结果的方法。
也可以使用命令行创建一个 Spider。比如要生成 Quote 这个 Spider,可以执行如下命令:
cd tutorial
scrapy genspider quotes quotes.toscrape.com
# Spider的名称 # 网站域名解析一下每一步:
cd tutorial是进入刚才创建的 tutorial 文件夹,然后执行scrapy genspider命令。- 第一个参数是 Spider 的名称,第二个参数是网站域名。
- 执行完毕之后,Spider 文件夹中多了一个 quotes.py,它就是刚刚创建的 Spider,内容如下:
点进去看看:
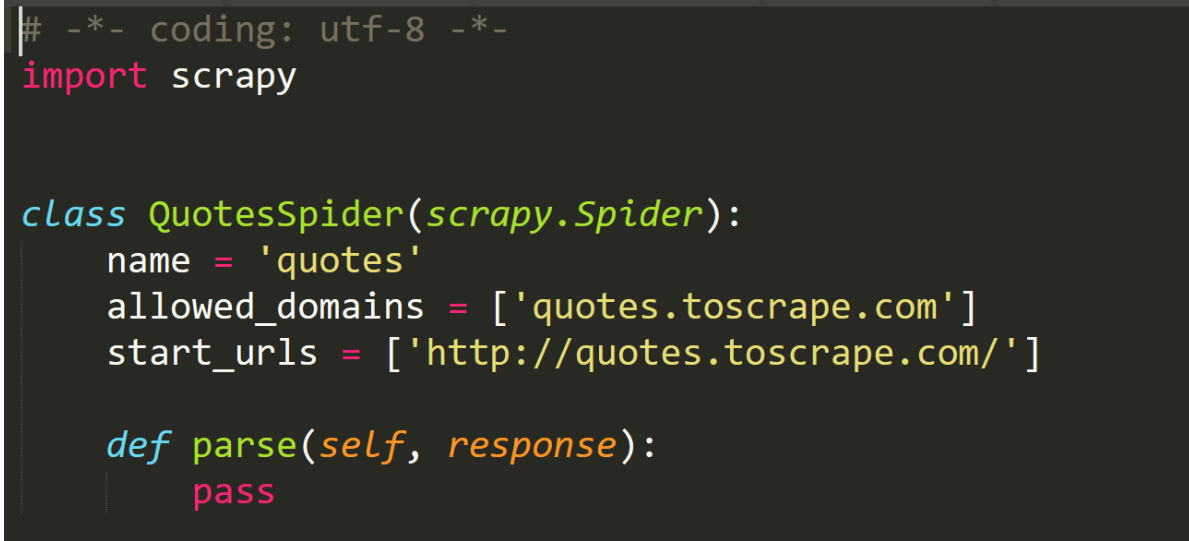
咱们来解析一下生成的每一部分内容:
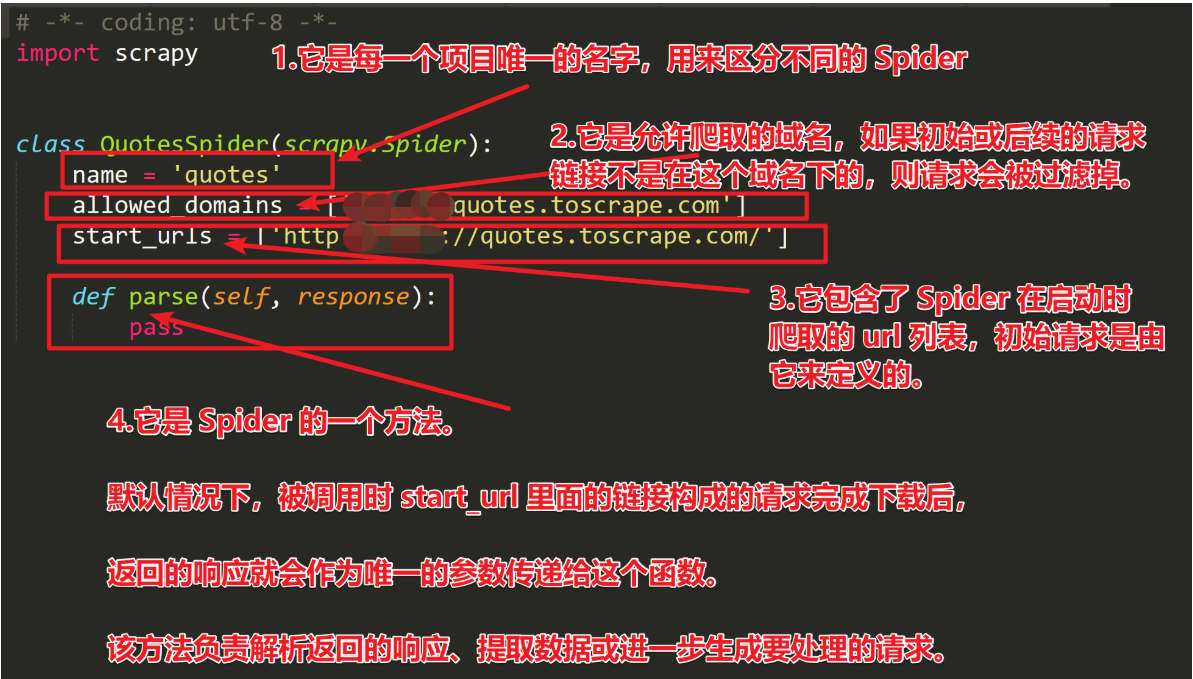
start_requests 的快捷方式:
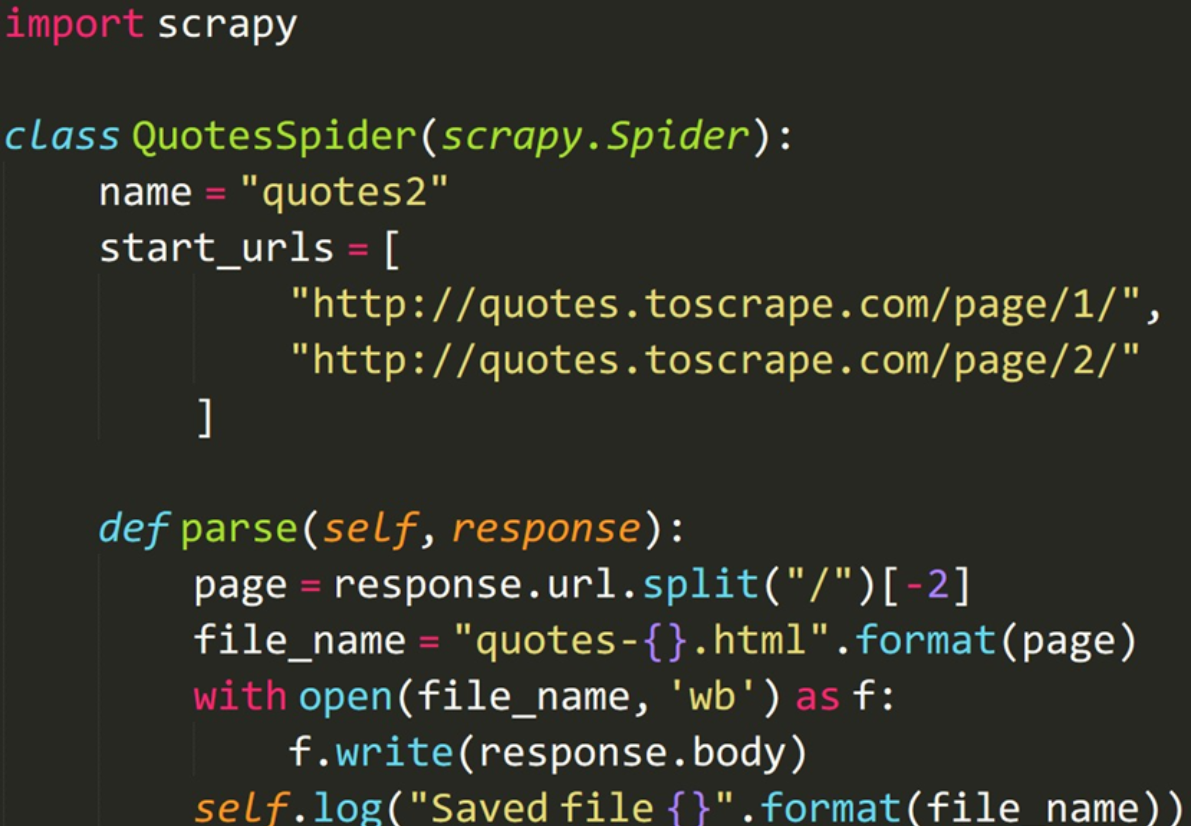
page:获取页码
数据抓取之后自然会有数据的存储,这里就顺带讲一下数据的存储方式。
Python 中的文件储存
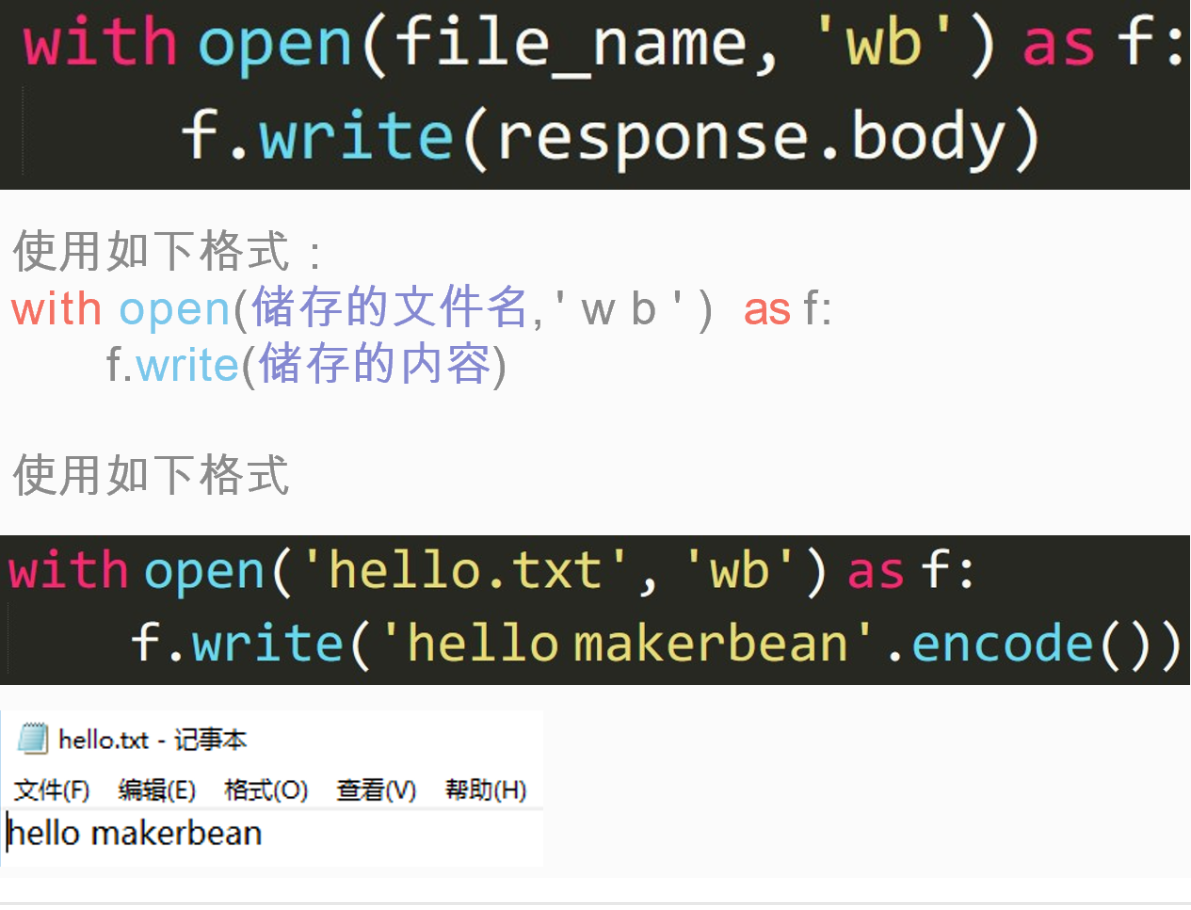
Python 文件使用“wb”方式打开,写入字符串会报错,因为这种打开方式为:以二进制格式打开一个文件只用于写入,如果该文件已存在则将其覆盖,如果该文件不存在,创建新文件。
所以写入的字符类型需为二进制格式,如:
f.write("hello".encode('ascii'))写入的编码范围不为 128 以内,就不能使用 ASCII 了,如:
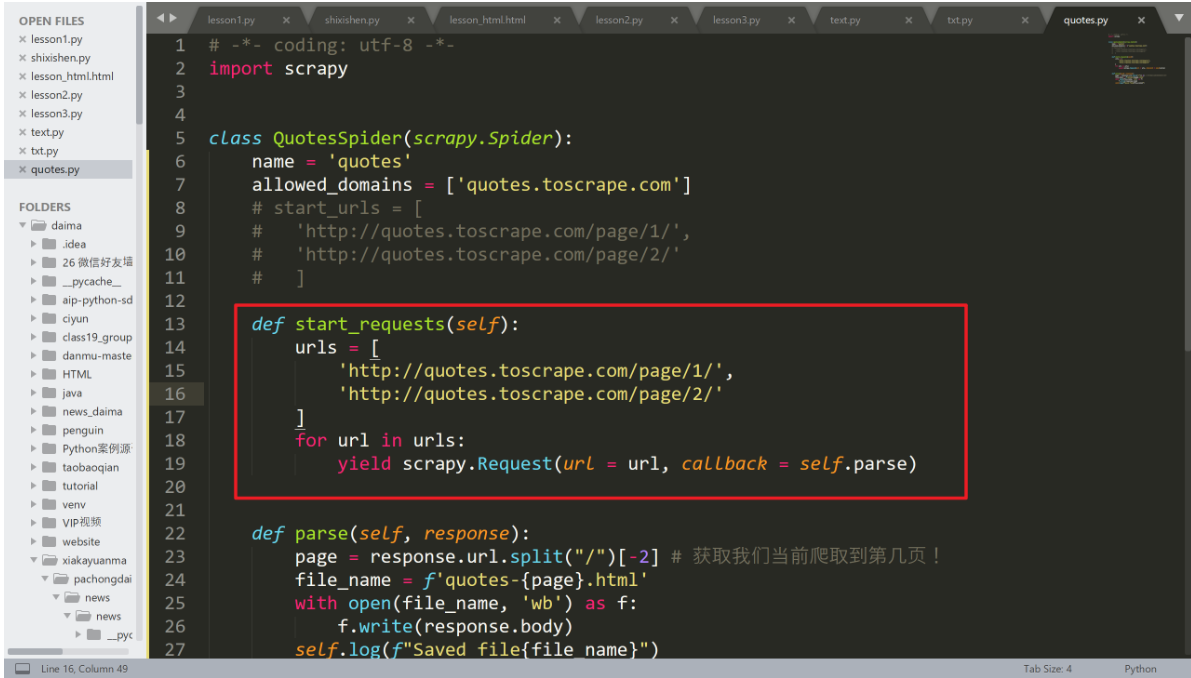
fh.write("汉字".encode('UTF-8'))接下来我们来定义一个函数 start_requests 如下:
- 图中的 yield:首先,如果你还没有对 yield 有个初步分认识,那么你先把 yield 看做“return”,这个是直观的,它首先是个 return。普通的 return 是什么意思,就是在程序中返回某个值,返回之后程序就不再往下运行了。看做 return 之后再把它看做一个是生成器(generator)的一部分(带 yield 的函数才是真正的迭代器)。好了,如果你对这些不明白的话,那先把 yield 看做 return。
- callback :回调。
注意:不同 Spider 的 name 不能相同。这些函数名称不能自己随意命名!
运行一下代码,体验体验。
注意:一定要进入根目录!在我们的例子里也就是 tutorials/,否则会报错。
代码如下:
scrapy crawl quotes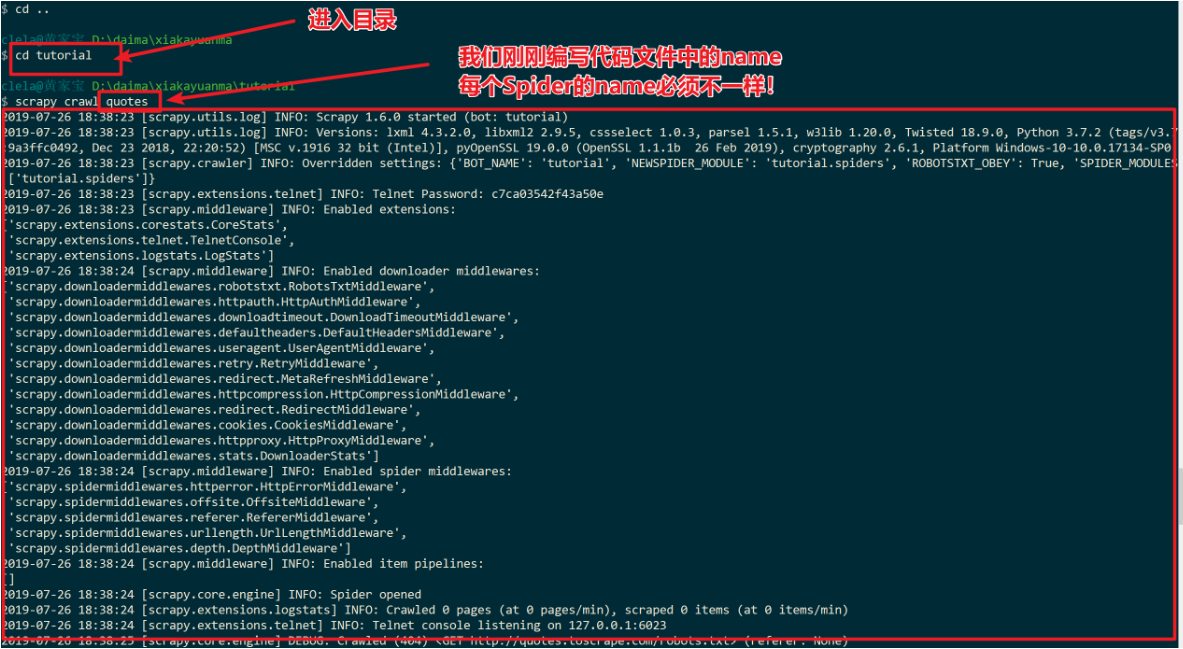
输出的下半部分:
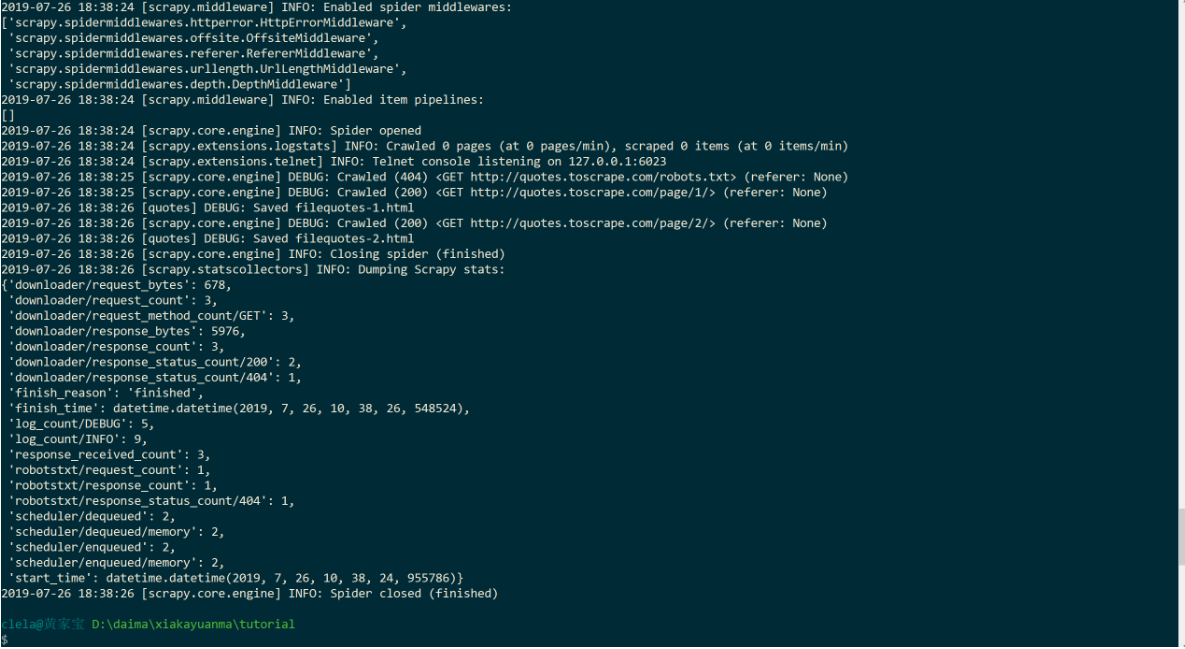
爬虫结果分析
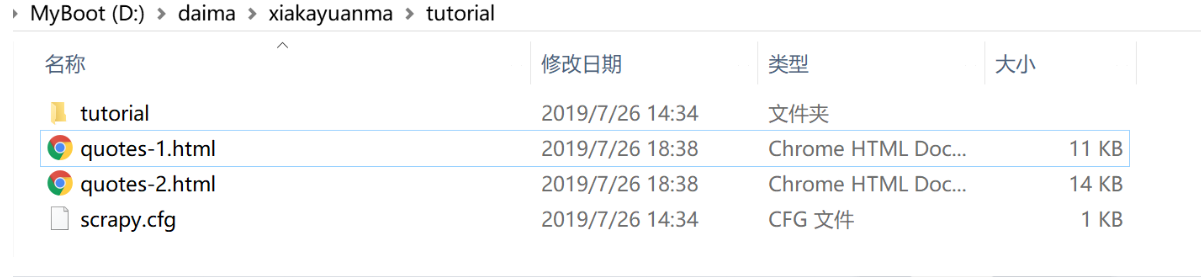
观察我们的根目录,发现了两个新文件 HTML:
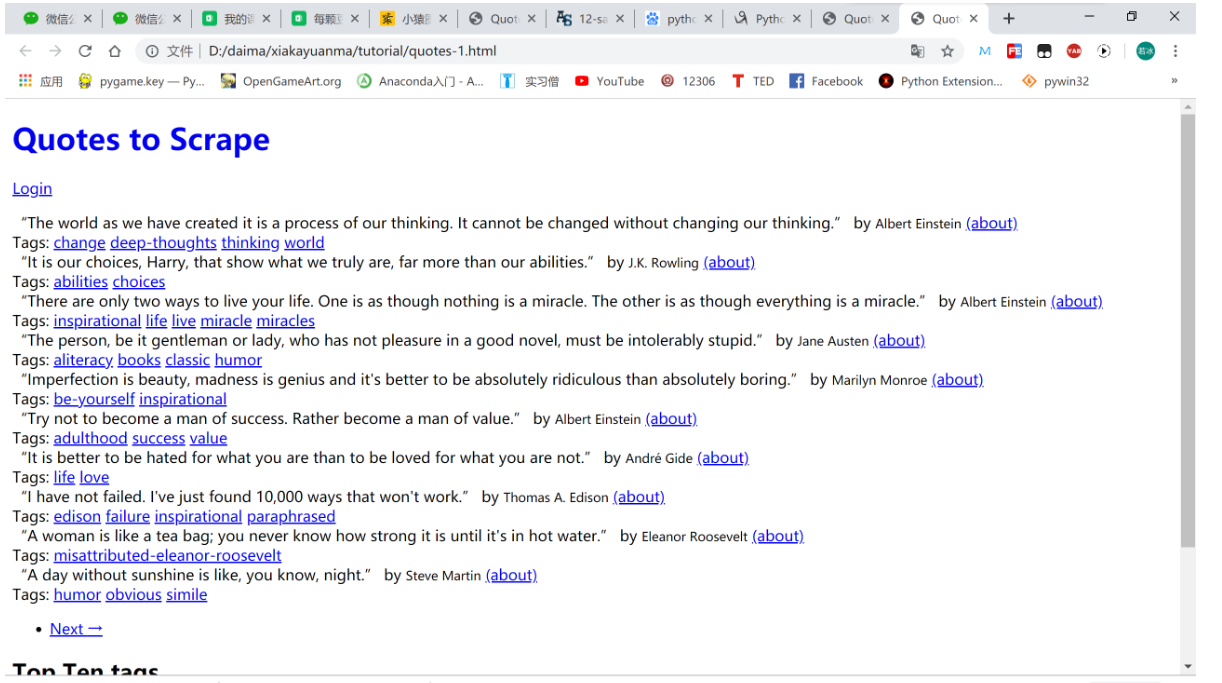
刚刚得到的是整个网页的 body。现在,我们可以用如下代码:
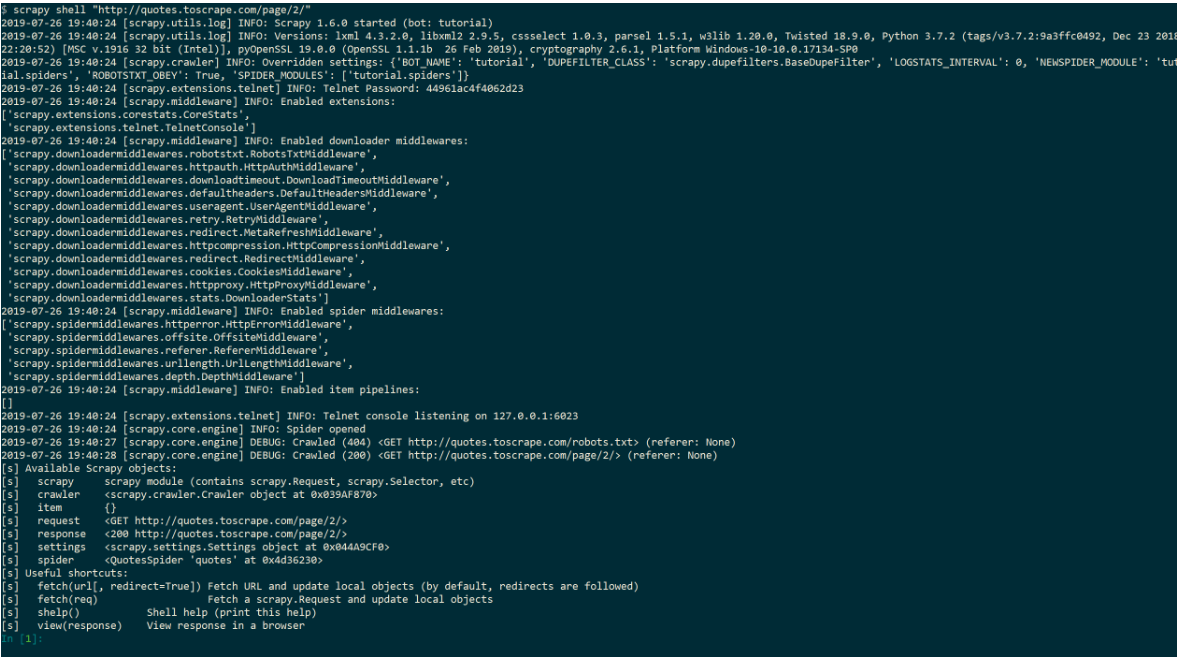
scrapy shell "http://quotes.toscrape.com/page/2/"
进入scrapy的交互模式注意:
- 在根目录下输入
- 网址必须用双引号括起来,不能用单引号,否则会报错:
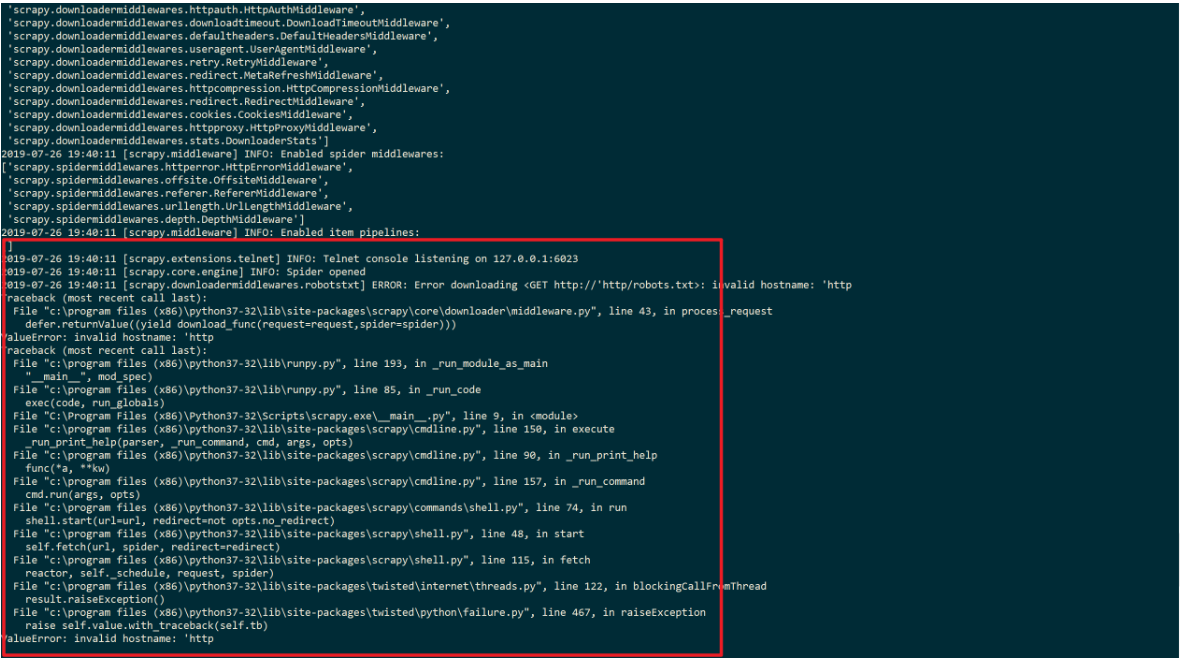
正确输入之后的结果:
进入交互模式之后,提取数据:

response 是通过 Scrapy 直接爬取到的网页内容,response.css(‘title’) 得到一个 CSS 选择器结果。
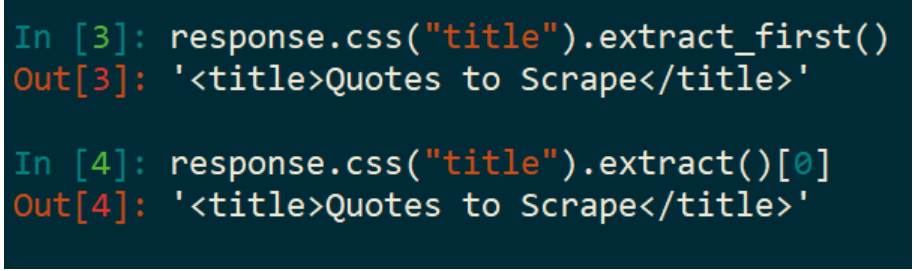
提取其中的内容:response.css(‘title’).extract() 将 HTML 元素提取出来:

.extract() 返回的是一个列表,而只想处理第一个结果:
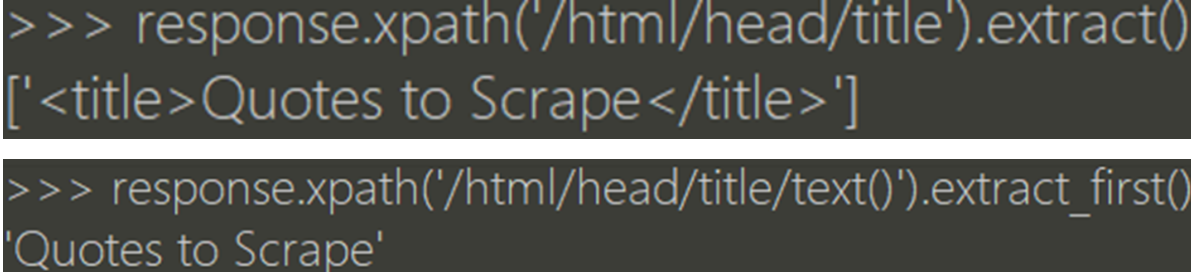
必知必会:除了 CSS,Scrapy 选择器还支持 Xpath。
提取数据
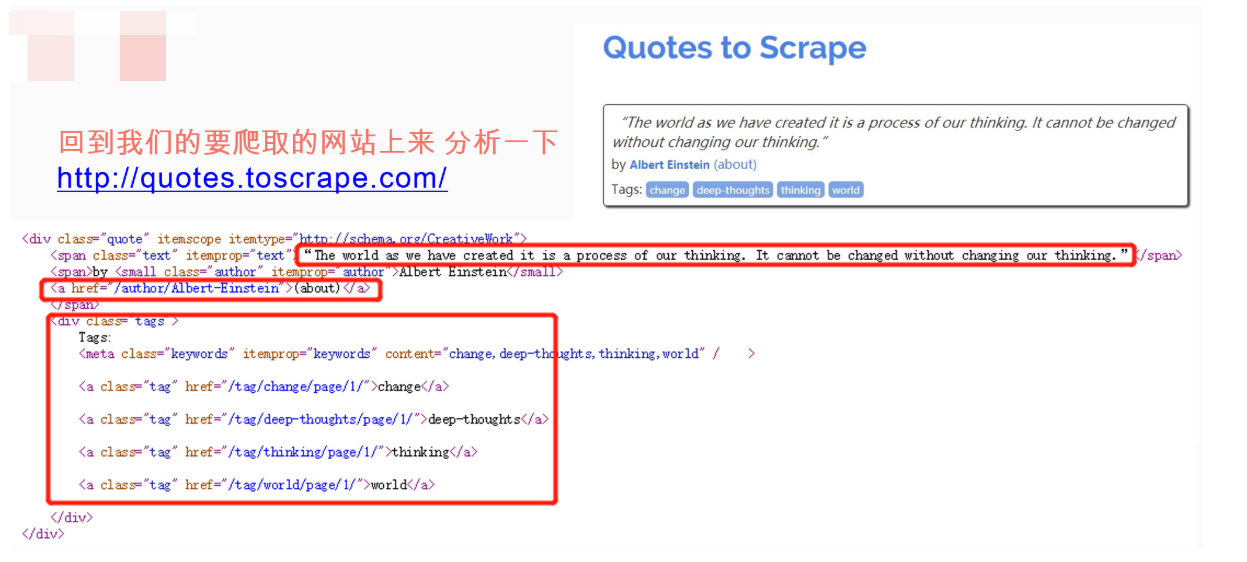
我们先提取 class="quote" 的,div 可以省略不写。代码如下:
response.css("div.quote")让我们一起提取 Quote 和内容:
response.css("div.quote").extract()
# extract() 提取实际的内容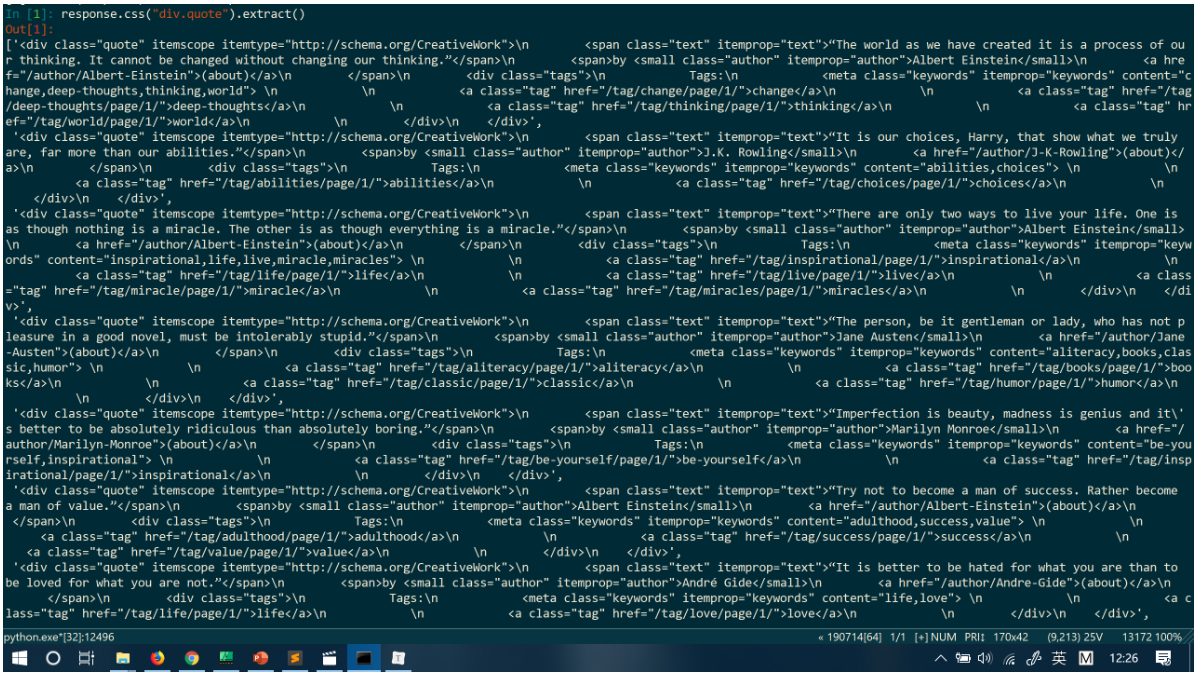
注意:两个冒号 text >>> ::text >>> 作用是把这个元素的文本提取出来。
没有加 ::text

有加 ::text

由以上分析可知,加上 ::text 可以得到纯文本的内容,而没加 ::text 得到的是带标签的文本内容。以下操作示例,认真观察并学会自己直接总结。
提取 Quote 并储存到 TXT 文件
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
# start_urls = [
# 'http://quotes.toscrape.com/page/1/',
# 'http://quotes.toscrape.com/page/2/'
# ]
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/'
]
for url in urls:
yield scrapy.Request(url = url, callback = self.parse)
def parse(self, response):
page = response.url.split("/")[-2] # 获取我们当前爬取到第几页!
# file_name = f'quotes-{page}.html'
file_name = f'quotes-{page}.txt'
with open(file_name, 'wb') as f:
quotes = response.css(".quote") # 得到的 quotes 是个列表,所以需要对列表进行遍历
for index, quote in enumerate(quotes):
text = quote.css("span.text::text").extract_first() #筛选出文本
author = quote.css('small.author::text').extract_first()
tags = quote.css(".tags .tag::text").extract()
# f.write(f"No.{(index + 1).encode()}")这个为什么不行?
f.write("No.{}".format(index + 1).encode())
f.write("\r\n".encode())
f.write(text.encode())
f.write("\r\n".encode())
f.write("By {}".format(author).encode())
f.write("\r\n".encode())
tags_str = ''
for tag in tags:
tags_str += tag + ","
f.write(("Tags: " + tags_str).encode())
f.write("\r\n".encode())
f.write(("-"*20).encode())
f.write("\r\n".encode())
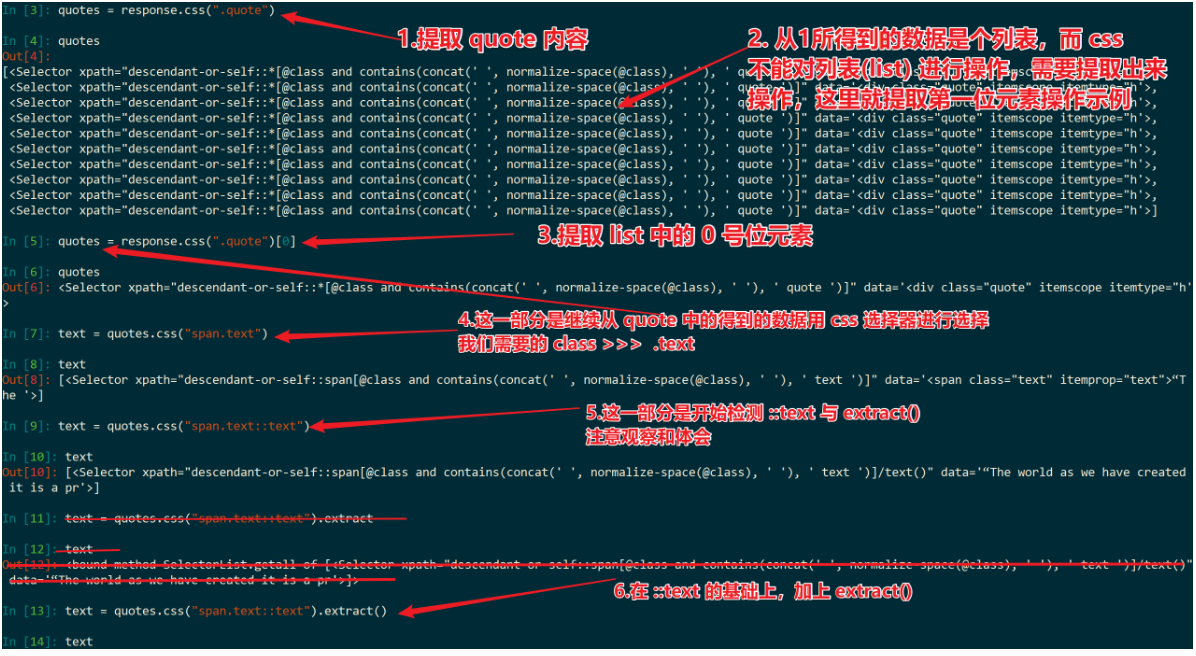
self.log(f"Saved file{file_name}")小结
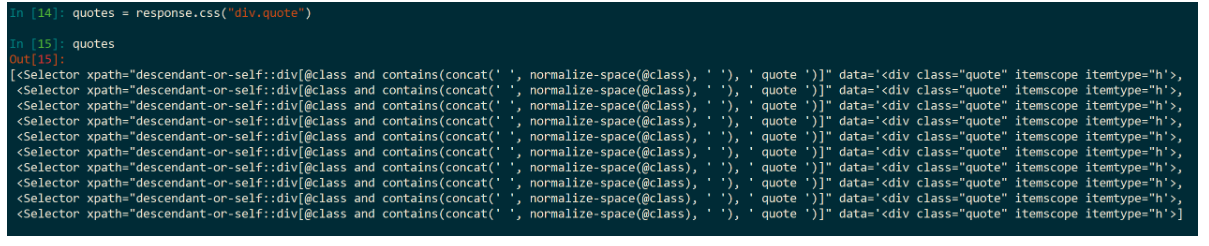
- response.css("div.quote") 得到的数据类型是个列表(list),而我们在使用 CSS 选择器再一次选择操作的时候不能对列表操作。所以,需要提取 0 号位上的数据(当然,其他位上的数据也是可以的)。
- 两个冒号 text >>> ::text >>> 作用是把这个元素的文本提取出来,
- extract() 提取元素,由上面可知,没加 ::text。
- extract_first() 得到的数据是列表的第一位元素,
7.3 Scrapy 的交互式模式——番外篇
看完交互式模式内容,更将进一步理解 Scrapy 当中的 CSS 选择操作。
进入 Scrapy 的交互模式
代码如下:
scrapy shell "Url" # 这个 Url 就是scrapy爬取的网址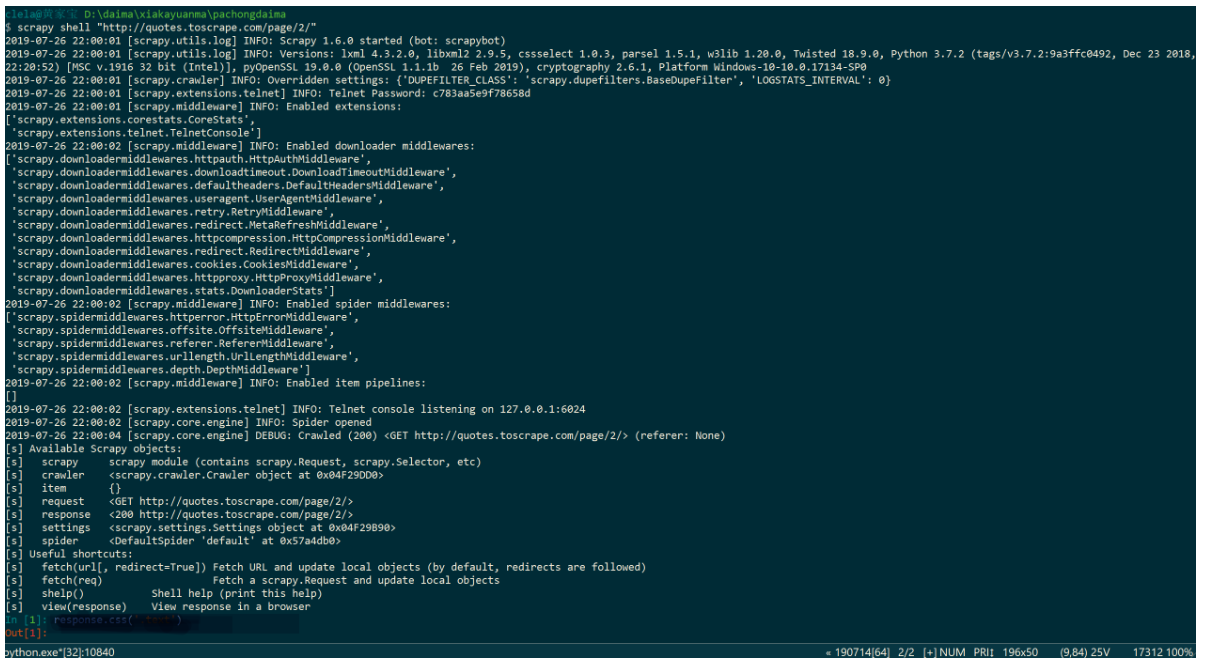
我们来简单分析一下。
1. response 是通过 Scrapy 直接爬取到的网页内容,代码如下:
response.css('.text')得到数据:
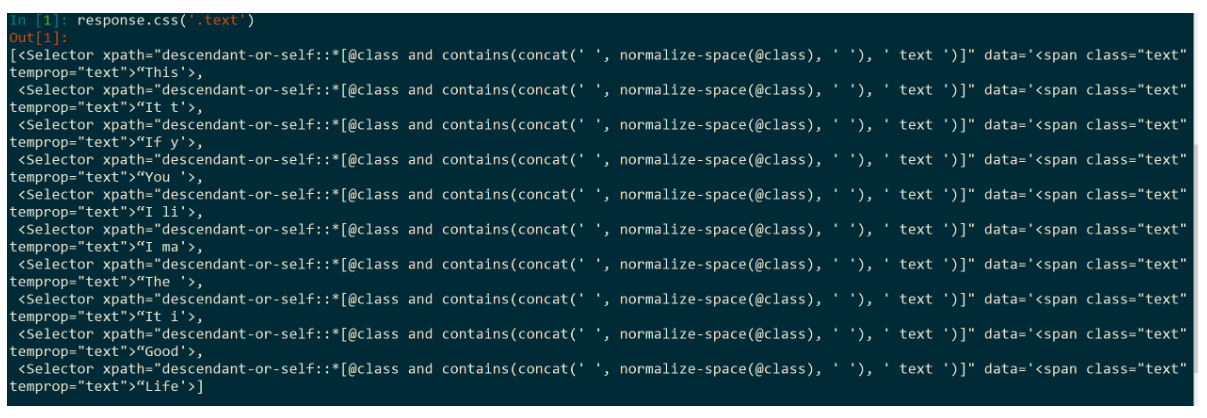
分析:
- 得到一个 list 的数据类型
- 爬取到想要的 text 标签
- 并且我们会发现,我们爬取的网页一共页,都在一个列表里面
那我们接下来要提取其中的数据呢?加个 extract()。
response.css(".text").extract()输出示例:
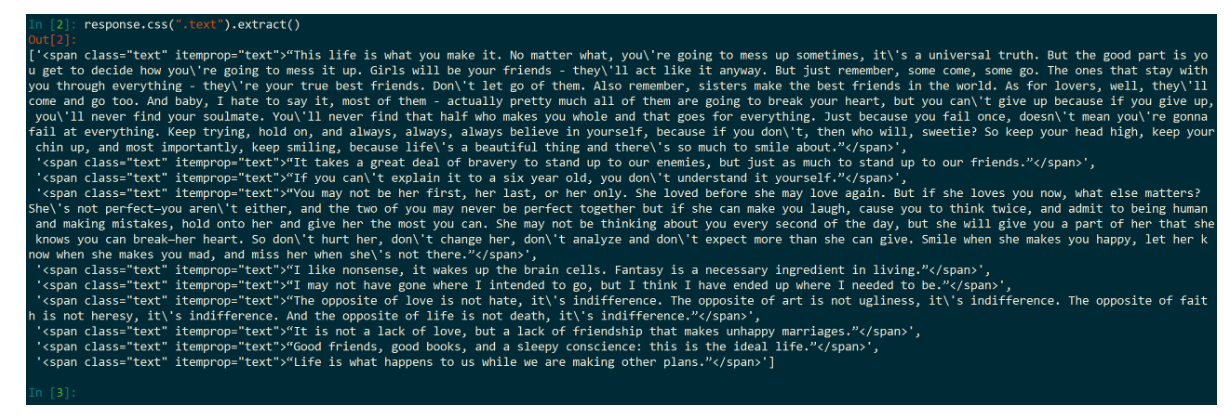
我们只要这个列表的第一个元素有两个方法。
方法一:extract_first()
response.css(".text").extract_first()方法二:就是类似与列表操作的方法一样
# 回顾一下列表知识点
# 创建一个列表
list1 = ['LiLei', 'Make', 'AIYC']
print(list1[0]) # 获取列表的0号位元素
print(list1[1]) # 获取列表的1号位元素
print(list1[2]) # 获取列表的2号位元素
>>> LiLei
>>> Make
>>> AIYC好,我回顾之后步入正题方法二:
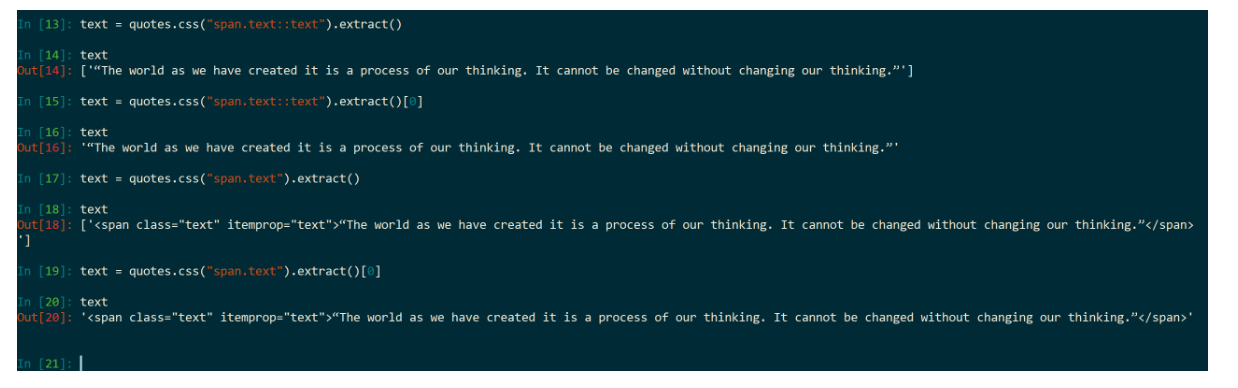
response.css(".text").extract()[0] # 获取列表0号为元素两种方法的运行过程:
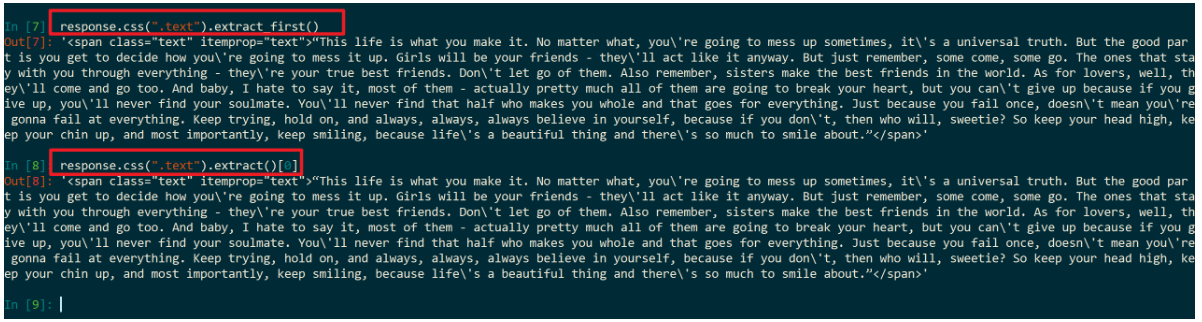
但是,到这一步你会发现不管是方法一还是方法二,通过 response.css(".text").extract_first() 或者是 response.css(".text").extract()[0] 得到的数据是带有 span 标签的!
那如何解决此问题呢?
使用 ::text:
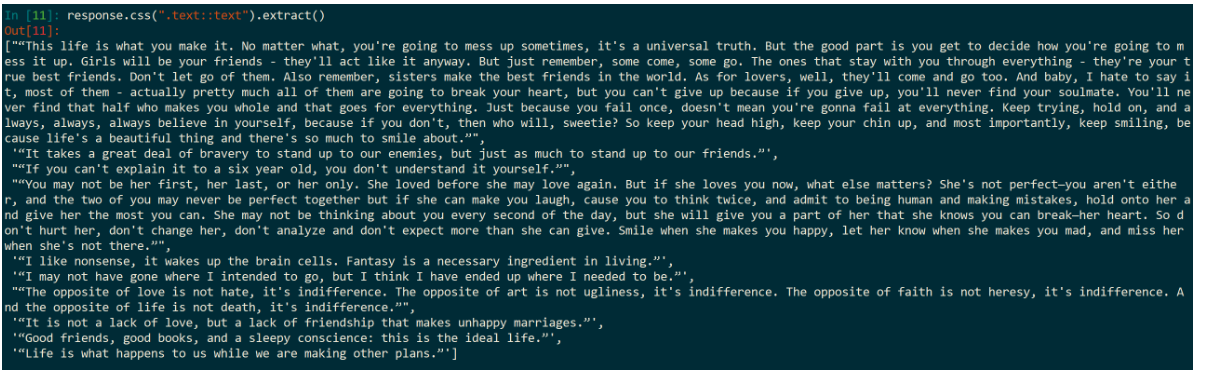
这时我们发现,列表中得到的是文本了,数据类型当然是列表,里面是字符串组成的每一个元素。
提取数据
上面已经全部提到的,咱们大体过一遍:
- 提取 Quote 和内容
- 作者信息
- 提取对应的 tag
7.4 提取 Quote 并储存到 TXT 文件
1. 让我们一起提取 Quote 和内容
运行示例:
那我们直接提取 text 文字。
原网页分析:
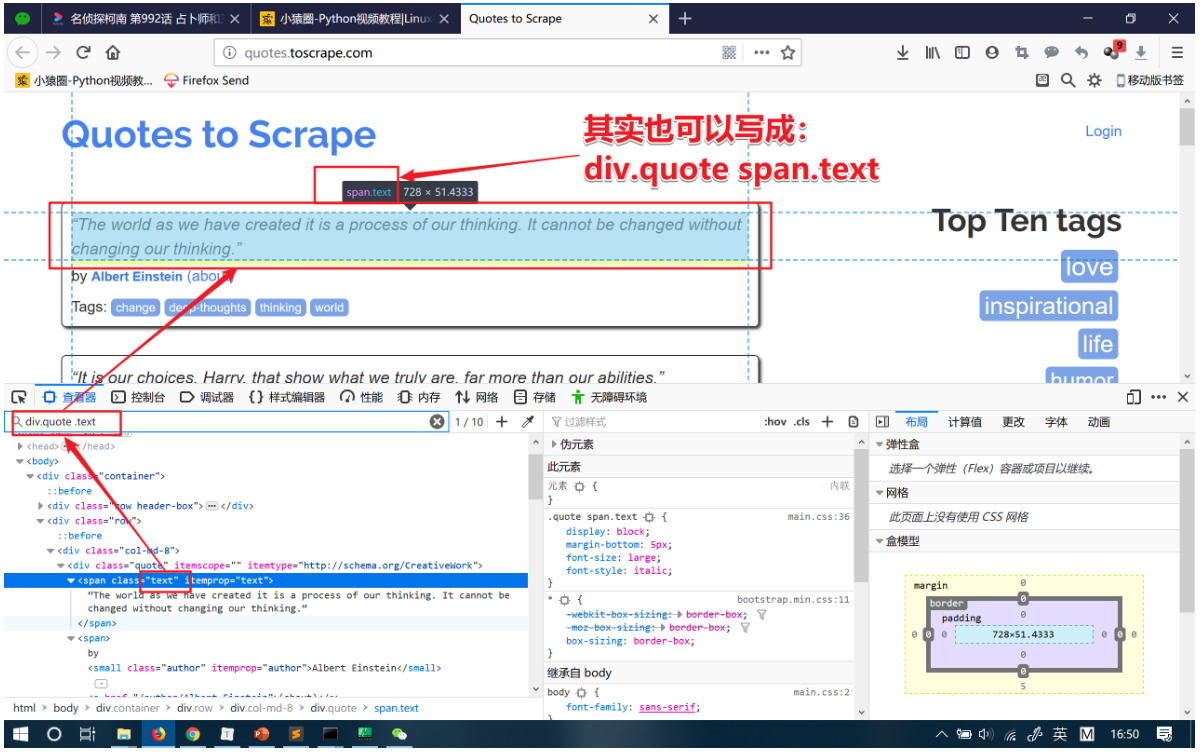
注意:div 可以省略不写。
运行示例:
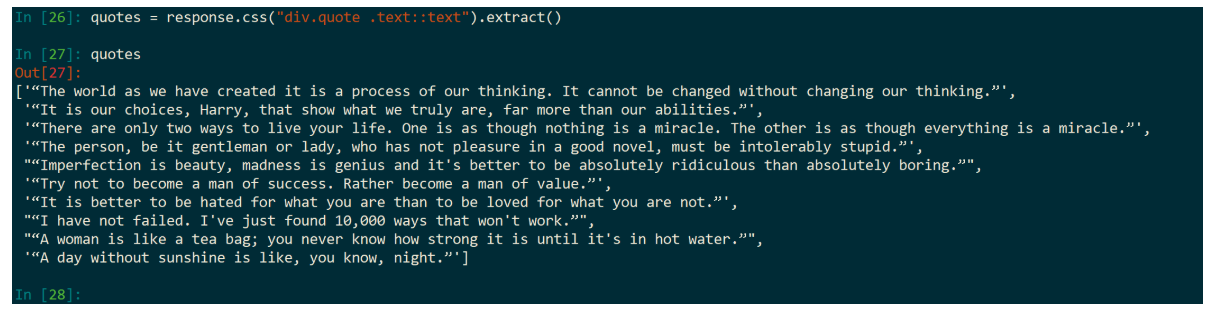
2. 让我们一起提取作者信息
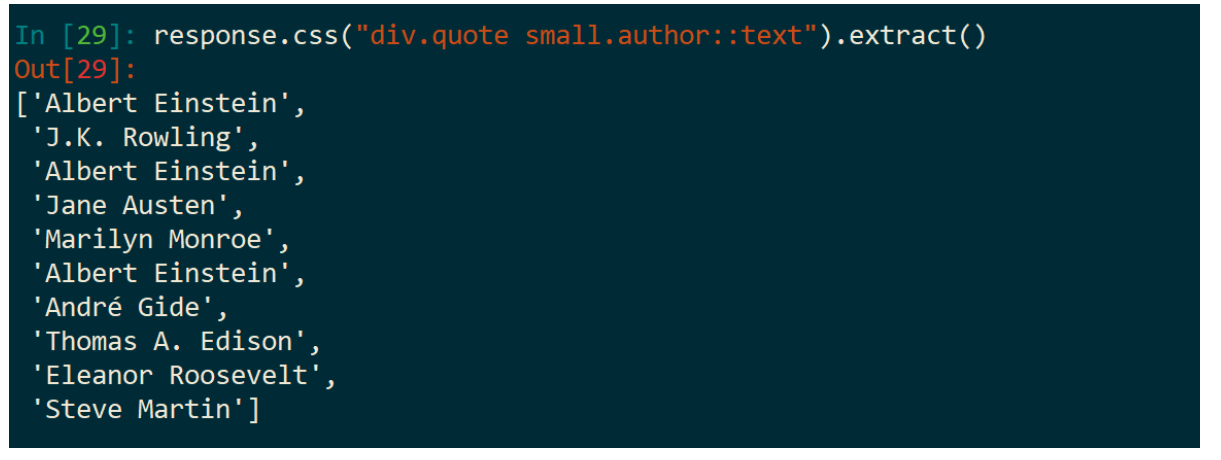
一样的步骤,先分析网页源码:
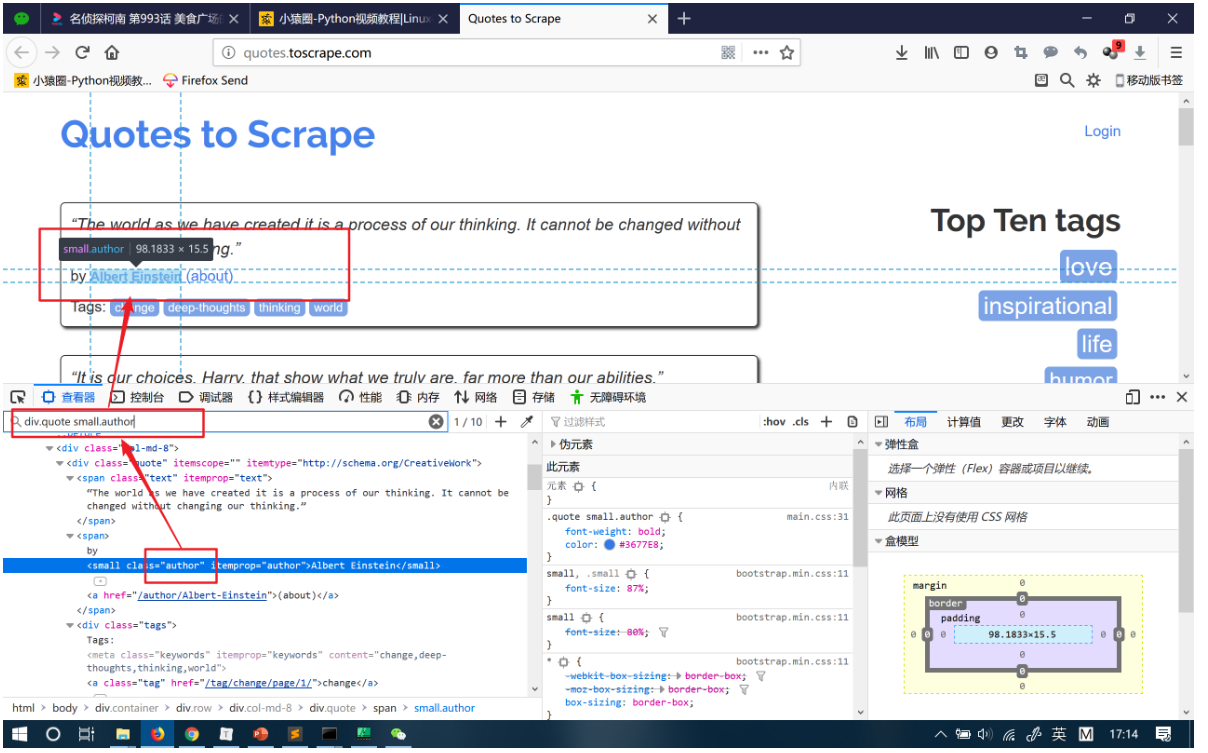
运行示例:
3. 提取对应的 tag
也是先分析网页:
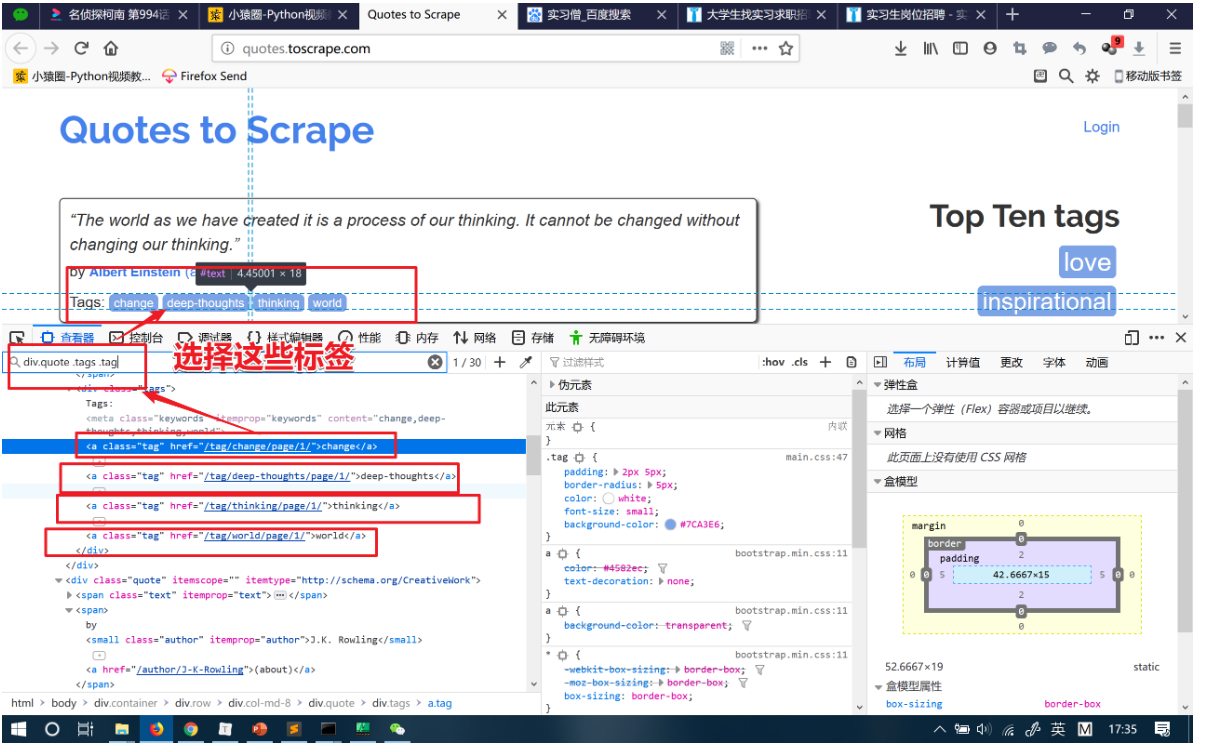
运行过程(当然,可以把 CSS 选择器简写,这里我为了让零基础的更加容易理解):
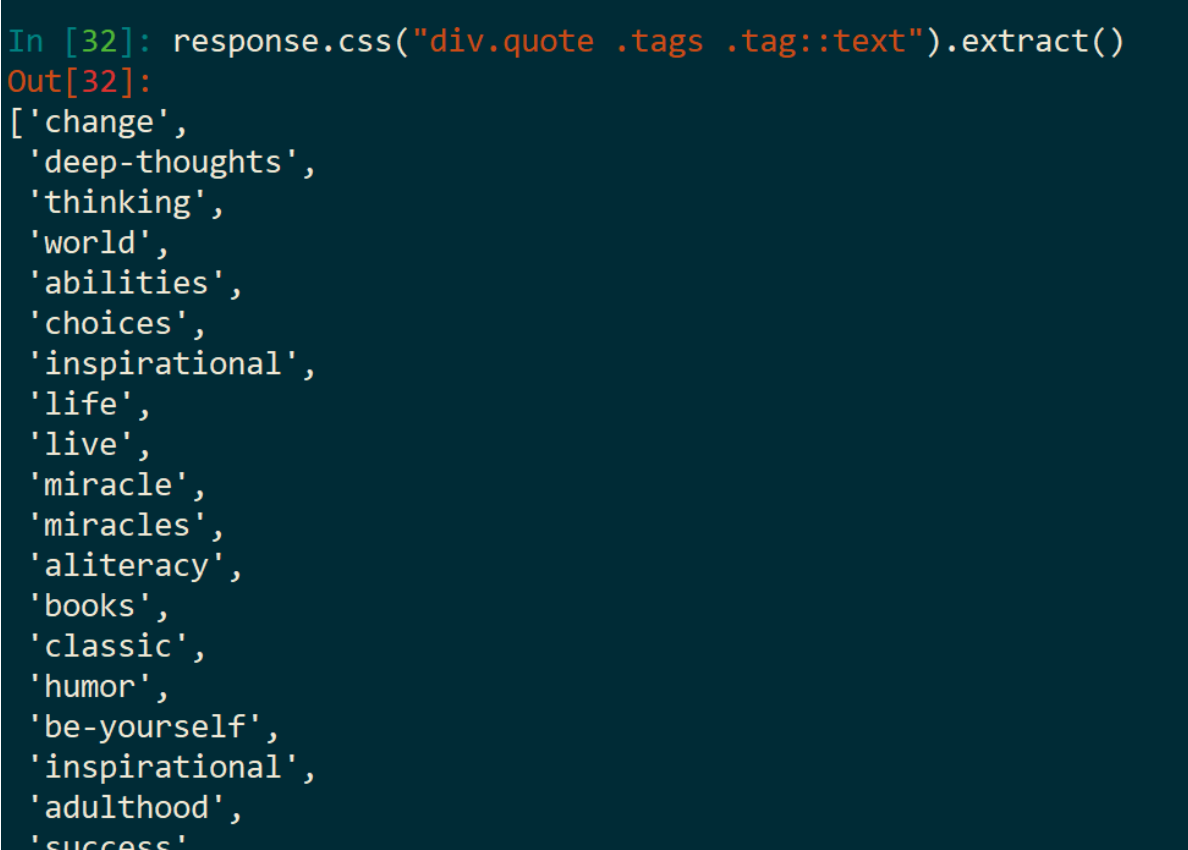
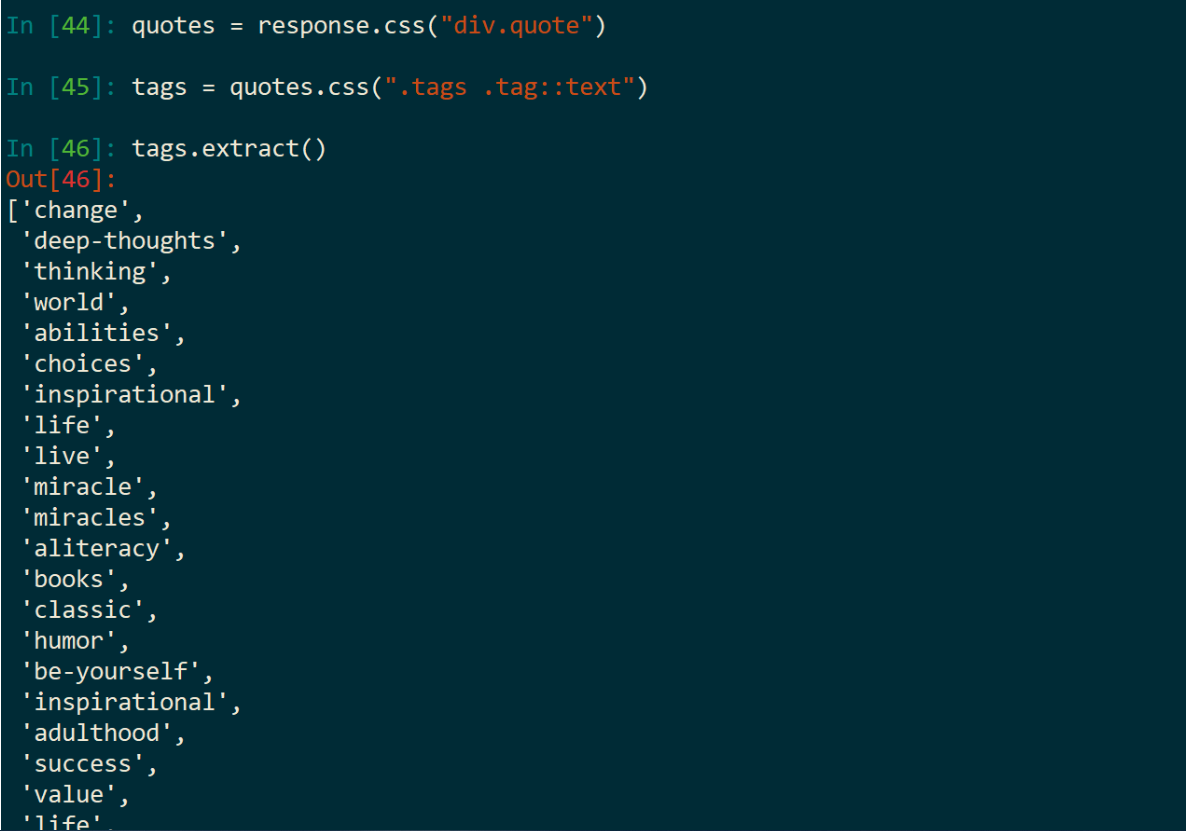
当然,还能这样操作:

接下来我们正式开始网易新闻实战!
八、Scrapy 实战——爬取新闻
8.1 新建项目
代码如下:
# 新建项目的命令
# 1\. 在目标目录下启动控制台
# 2\. 然后,在命令行里面输入如下命令:
# scrapy startproject 项目名称
# 那这里的项目名称就设为:news
# 最终输入:
scrapy startproject news如下:

https://mp.weixin.qq.com/s/yBkXGT6dFgg46WeaZ18rjA8.2 创建 Spider
注意:这里创建的 Spider 名称不能与项目名称相同,否则会报错!!!
代码如下:
# 在项目根目录运行命令行命令(注意是否已经cd news进入到项目根目录):
# scrapy genspider 蜘蛛名称 要爬取的域名
# 这里我们创建一个项目名称为:news163
# 爬取的域名是:news.163.com
# 注意:
# 1\. 这里的域名前面不要加 协议:https:// 或者添加 www
# 2\. Scrapy 生成 Spider 的时候会自动添加
# 最终输入:
scrapy genspider news163 news.163.com
# 扩展
scrapy genspider -t crawl news163 news.163.com如下:

实际文件夹文件图片:
图一
图二
8.3 进入创建的 Spider >>> news163.py
如图:
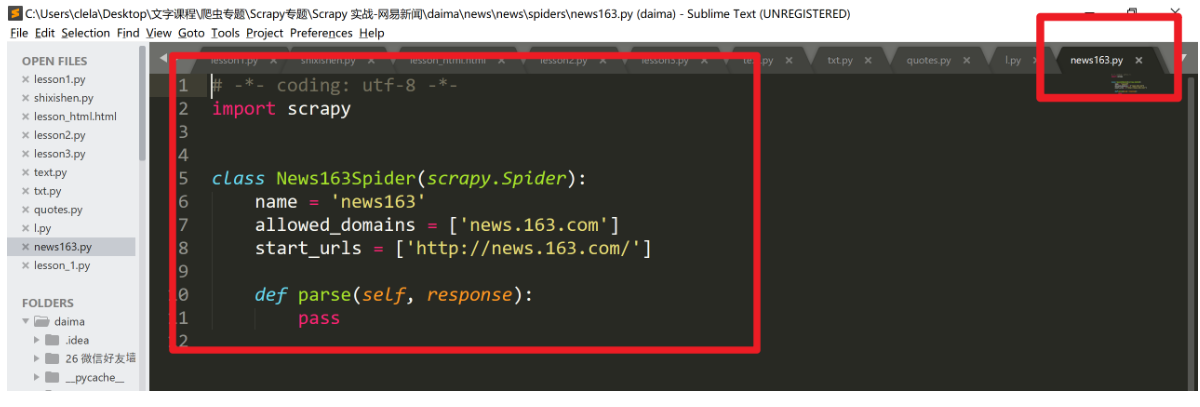
解析每一部分的内容:
import scrapy:导入 scrapy 库class News163Spider(Scrapy.Spider):这是一个类,然后这个类继承于 Scrapy 这个父类- name:爬虫的名字叫 news163
allowed_domains = ['news.163.com']:这是设置这个爬虫允许爬取的域名,如果初始或后续的请求不是在这个域名下的,则请求链接会被过滤掉start_urls = ['http://news.163.com/']- parse:start_urls 第一个传下来的参数默认先运行 parse 函数。之后我们自己定义类似 parse 函数的话,也要做出区分,例如 parse1、parse2 之类的
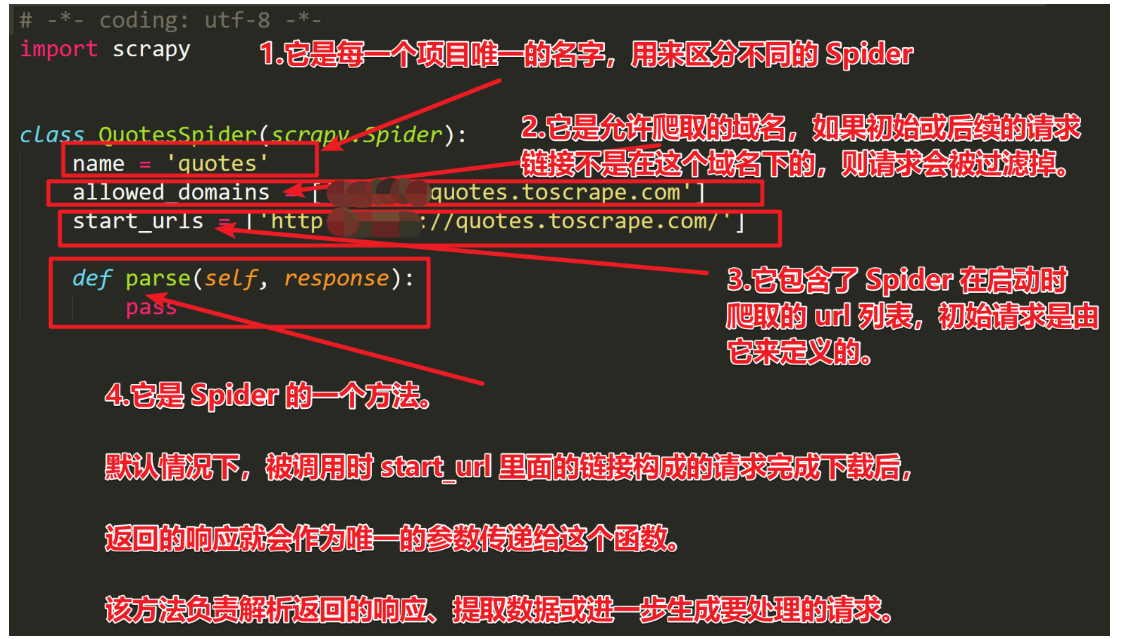
这里我觉得还是用图片能让大家更好的理解:
8.4 扩展——Xpath

XPath 定义:[4]
是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
因此,对 XPath 的理解是很多高级 XML 应用的基础。
什么是 XPath?
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 包含一个标准函数库
- XPath 是 XSLT 中的主要元素
- XPath 是一个 W3C 标准
8.5 items.py
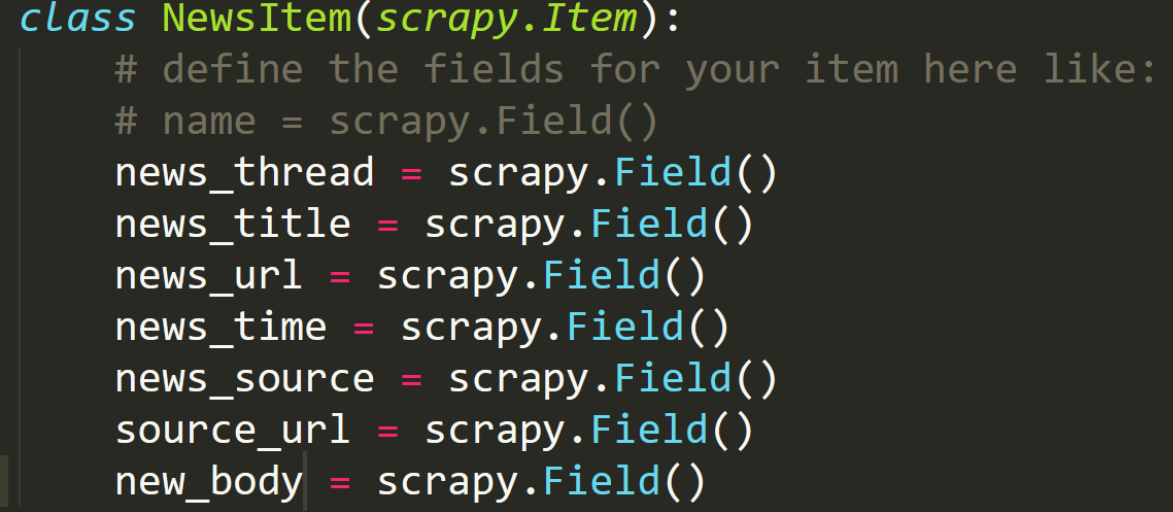
请记住这部分, 这是我们对于每个网页爬取的信息要获得的属性:
8.6 spiders.py
导入库:
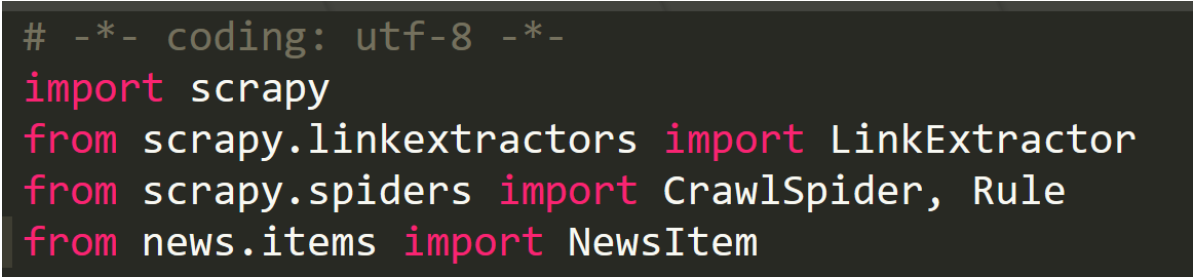
解析:
- import scrapy:导入这个 Scrapy 框架
- from scrapy.linkextractors import LinkExtractor:链接提取器(提取链接)
- from scrapy.spiders import CrawlSpider, Rule:其中 CrawlSpider 是 Spider 的派生类,具有更多的方法和功能;Rule 表示的是爬取的规则
- from news.items import NewsItem:导入刚刚我们编写的 Items.py
扩展:
- CralwSpider:CrawlSpider 是 Spider 的派生类
- LinkExtractor:LinkExtractor 是从网页(scrapy.http.Response)中抽取会被 follow 的链接的对象
注意:
- 我们的类 ExampleSpider 一定要继承自 CrawlSpider
- callback 不要用 parse,把自动生成的 parse 删掉
8.7 编写 URL 爬取规则

- Rule:规则
- LinkExtractor 链接提取,即然这个是提取链接的,那这提取的链接的内容肯定是有要求的!所以就引出第 3 点
- allow:允许爬取的网址形式
- callback:但爬取到符合规则(allow)的链接(LinkExtractor),那得到了链接就调用函数
- 我们把调用函数 parse_news 的这个形式,称为:回调
8.8 正则表达式简单介绍
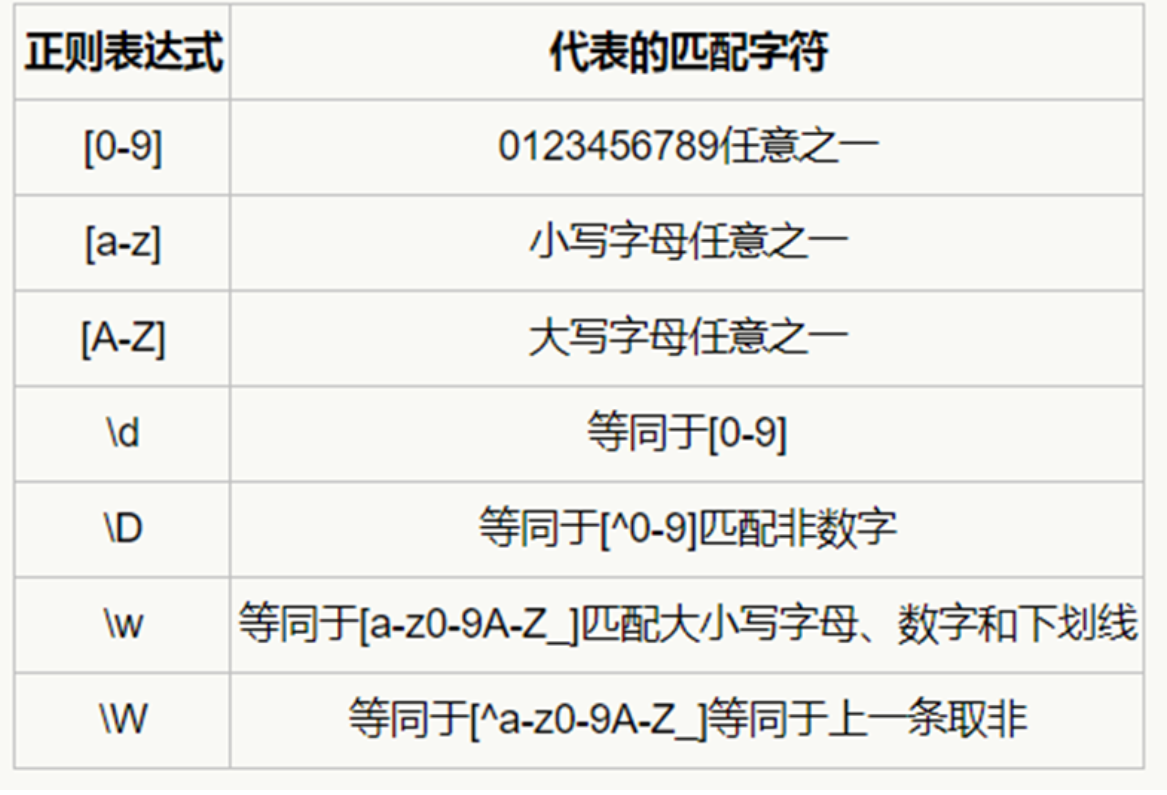
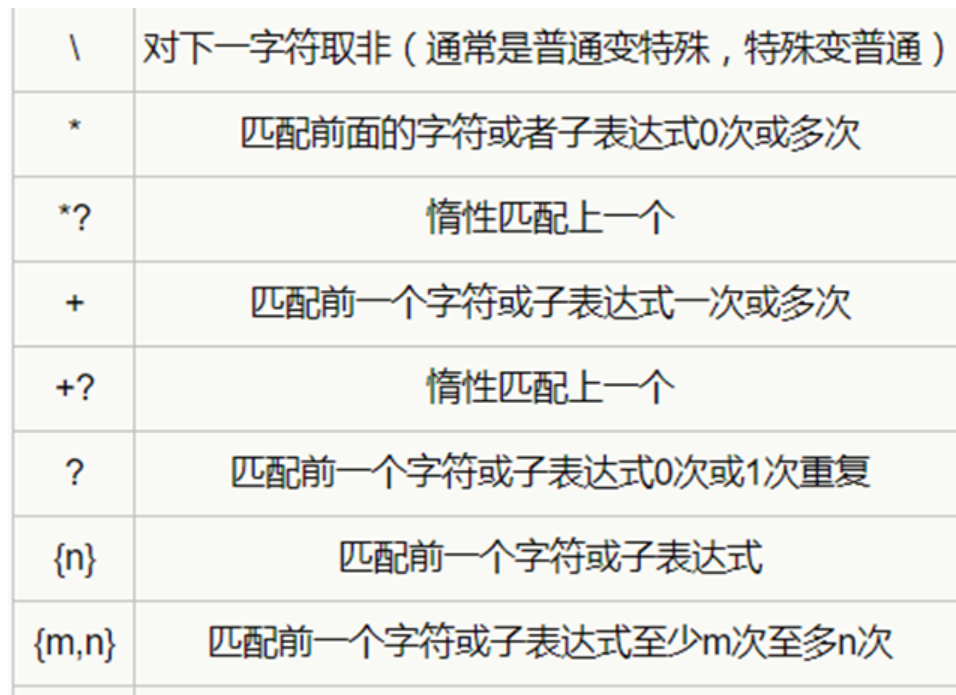
突破理解正则表达式,分析目标网址。
这里我们使用网易新闻:
https://news.163.com/19/0801/15/ELGM0GIV000187VE.html
https://news.163.com/19/0801/20/ELH57GI0000189FH.html我们把前面的域名去掉:
/19/0801/15/ELGM0GIV000187VE.html
/19/0801/20/ELH57GI0000189FH.html然后我们编写正则表达式(正则表达式匹配变换的,不变化的我们就直接写原来的):
/19/0801/\w+/.*?.html
/19/0801/ :就是日期 >>> 19 年 8 月 01 日\w 我们通过分析网址可知,后面的数字开始不同了,而且是数字我们就用 \w 匹配字母(大小写字母)数字及下划线;而我们又发现日期后面的数字的两位数字,所以在后面加上 +;之后又一串很长的英文加数字,那这里我们就直接用惰性匹配 >>> .*?。
8.9 parse_news
parse_news 是我们的回调函数,为了防止代码的臃肿,我们来写这些类函数。代码如下:
# 在爬虫里面写,我这里的爬虫名称是 :news163.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from news.items import NewsItem
class News163Spider(CrawlSpider):
name = 'news163'
allowed_domains = ['news.163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'/19/0801/\w+/.*?.html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = NewsItem() # 实例化
item['news_thread'] = response.url.strip().split('/')[-1][:-5]
self.get_title(response, item)
self.get_time(response, item)
self.get_source(response, item)
self.get_url(response, item)
self.get_source_url(response, item)
self.get_text(response, item)
return item# 判断得到的数据是否为空!
if title:
pass
# 等价于
if title is not None:
pass
# 去掉空格
str2 = " Runoob " # 去除首尾空格
print(str2.strip())
>>>Runoob
# 下面也会写出来Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
为有助于理解,代码示例:
str = "00000003210Runoob01230000000"
print(str.strip( '0' )) # 去除首尾字符 0
str2 = " Runoob " # 去除首尾空格
print(str2.strip())
str = "123abcrunoob321"
print(str.strip( '12' )) # 字符序列为 12
# 输出结果
>>>3210Runoob0123
>>>Runoob
>>>3abcrunoob3好,有了上面的基础,我们可以来正式写各个部分的函数了!
获取时间,这里我们先通过一张图片直接来体现网页分析的步骤:
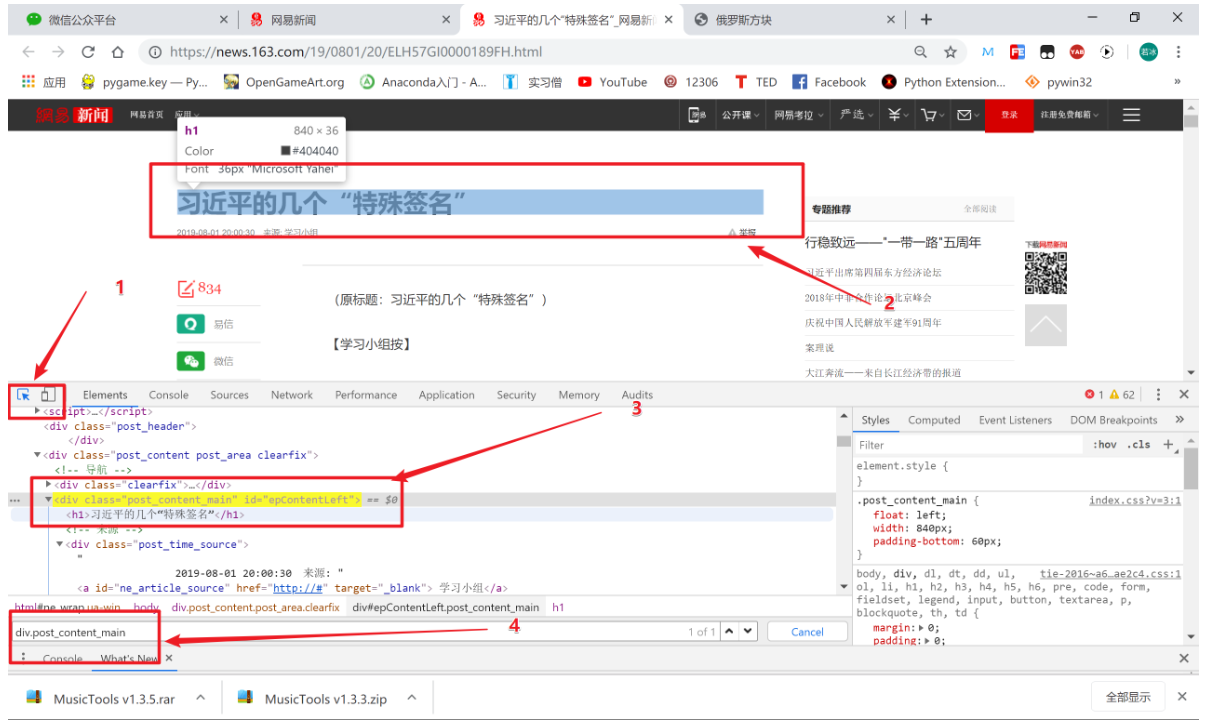
那我们就可以写下如下代码了:
def get_title(self, response, item):
title = response.css('.post_content_main h1').extract()
print('*'*10)
if title:
item['news_title'] = title[0]接下来可以继续写获取时间,时间有个特殊的点:
- 分析网页
- 编写代码
- 观察初步运行结果
- 做出修改
分析网页
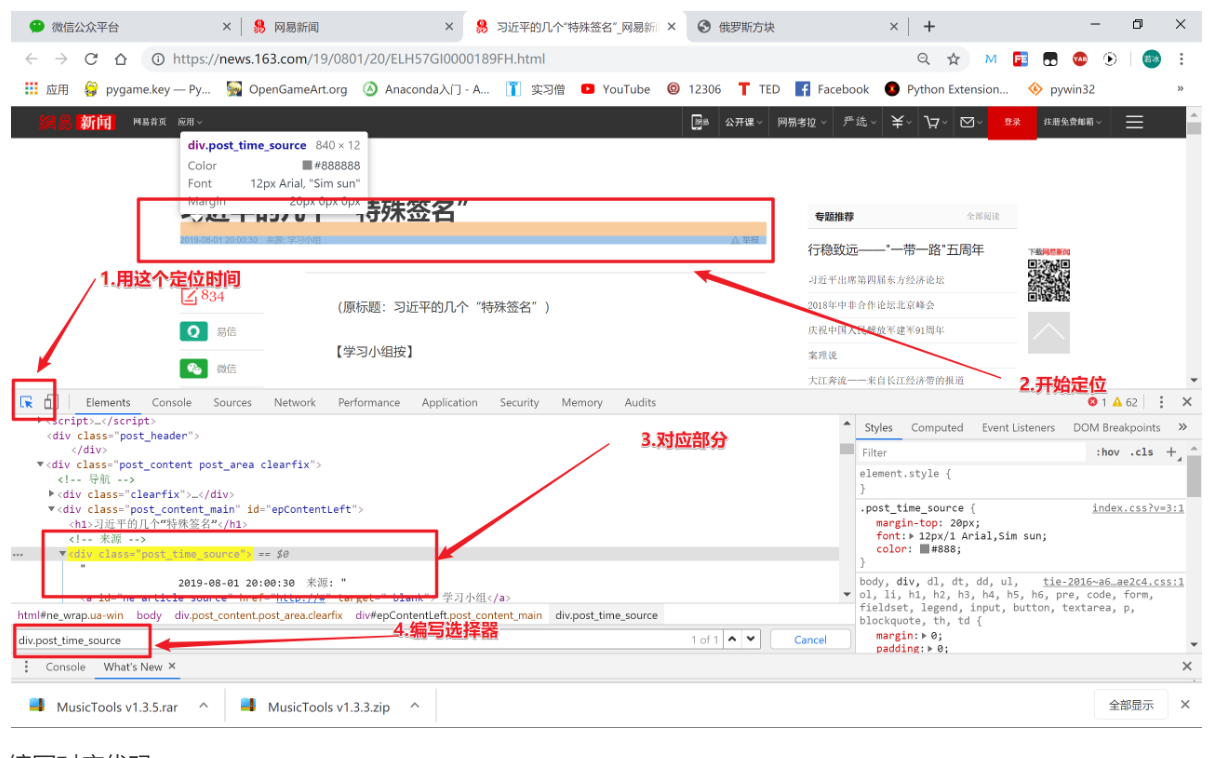
编写对应代码:
def get_time(self, response, item):
time = response.css('div.post_time_source').extract()
if time:
item['news_time'] = time[0]运行代码:
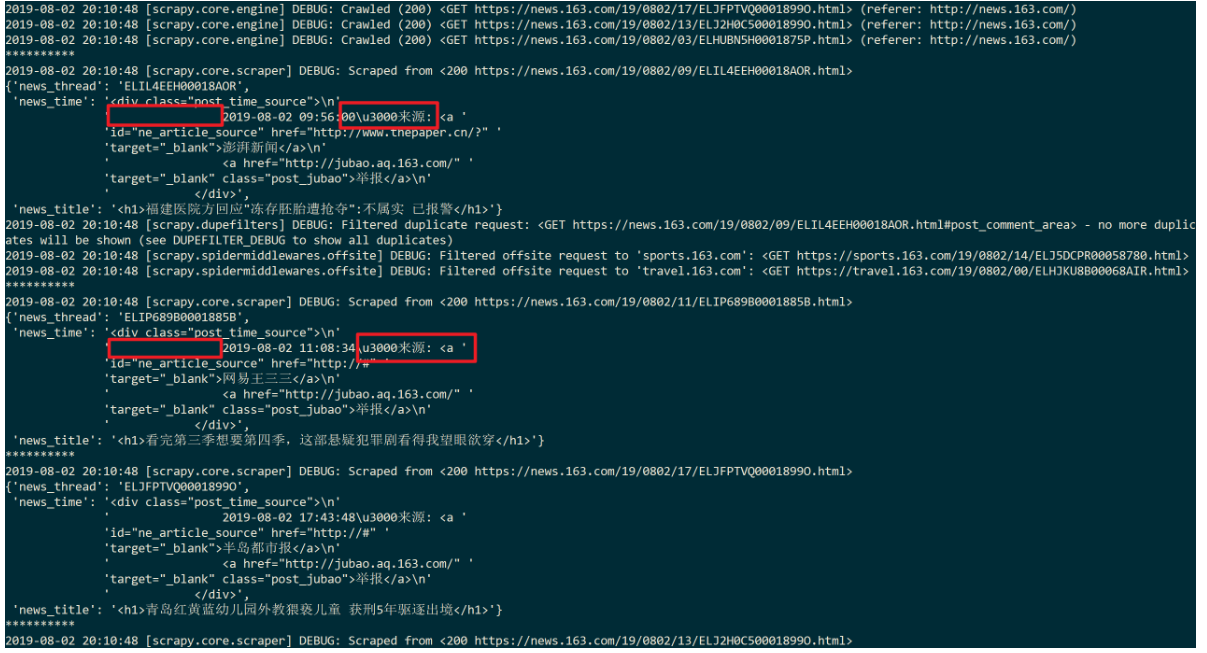
我们分析会发现,效果不太好,虽然时间成功爬取,但有多余的部分是我们不需要的。代码如下:
# ' 2019-08-02 09:56:00\u3000来源: '
# 1\. 这里面的日期 前面空格太多
# 2\. 日期后面都有: \u3000来源:
# 那如何解决这几个问题呢?
# 去掉字符串前后的空格
# .strip()
# 去掉: \u3000来源:
# 两种方法,方法一:
# 使用切片的方法,我们方向在我们还没爬取时间时,在日期后面有 5 个空格;
# 所以,如此操作:[:-5]
# 方法二:
# 使用 .replace() 函数来操作, .replace() 内置函数操作对象是字符串;
# 所以,如此操作: .replace('\u3000来源:','')
# replace() 回顾:
str.replace(old, new[, max])
>>>old -- 将被替换的子字符串。
>>>new -- 新字符串,用于替换old子字符串。
>>>max -- 可选字符串, 替换不超过 max 次注意:在使用 response.css() 选择的时候,需要在里面添加 ::text,外面添加:extract()。目前完整的 Spider 代码:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from news.items import NewsItem
class News163Spider(CrawlSpider):
name = 'news163'
allowed_domains = ['news.163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'/19/08\w+/\w+/.*?.html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = NewsItem() # 实例化
item['news_thread'] = response.url.strip().split('/')[-1][:-5]
self.get_title(response, item)
# 告诉程序,我们要调用的函数是自己的函数,不用去外面找这个函数;
self.get_time(response, item)
# self.get_source(response, item)
# self.get_url(response, item)
# self.get_source_url(response, item)
# self.get_body(response, item)
return item
def get_title(self, response, item):
title = response.css('.post_content_main h1::text').extract()
print('*'*10)
if title:
item['news_title'] = title[0]
def get_time(self, response, item):
time = response.css('div.post_time_source::text').extract()
if time:
item['news_time'] = time[0].strip().replace('\u3000来源:', '')由上面可知,我们还有这几样所需要的数据还未编写:
self.get_source(response, item)
self.get_url(response, item)
self.get_source_url(response, item)
self.get_body(response, item)那接下来我们继续编写。
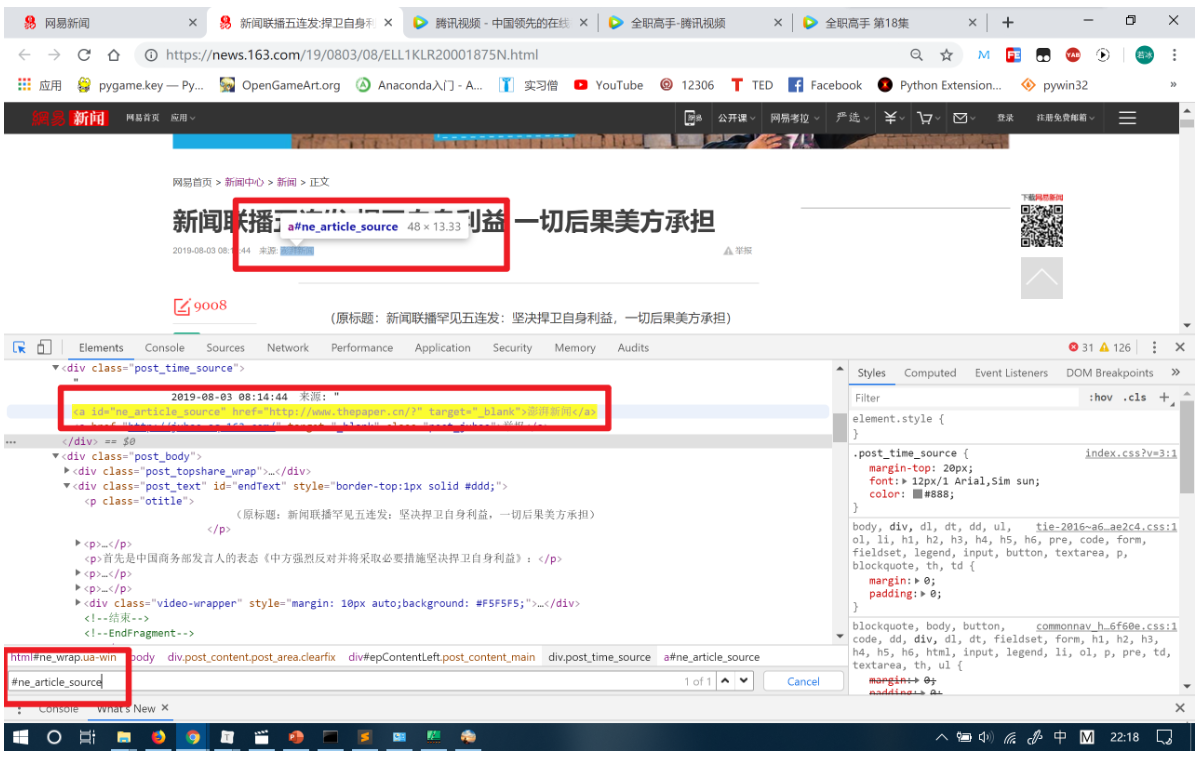
获取新闻来源
分析原网页:
代码如下:
# get_source(response, item)
def get_source(self, response, item):
source = response.css('#ne_article_source::text').extract()
if source:
item['news_source'] = '来源:'+ source[0]获取网页地址
def get_url(self, response, item):
url = response.url
if url:
item['news_url'] = url获取新闻所在的页面的网址
self.get_source_url(response, item)
由网页源码图可知,该来源的新闻网址为 href 中的属性值。那我们该如何提取该地址呢?
我们使用:attr()。
def get_source_url(self, response, item):
source_url = response.css('#ne_article_source::attr(href)').extract()
if source_url:
item['source_url'] = source_url[0]接下来是最重要的一步啦,获取网页的新闻内容:
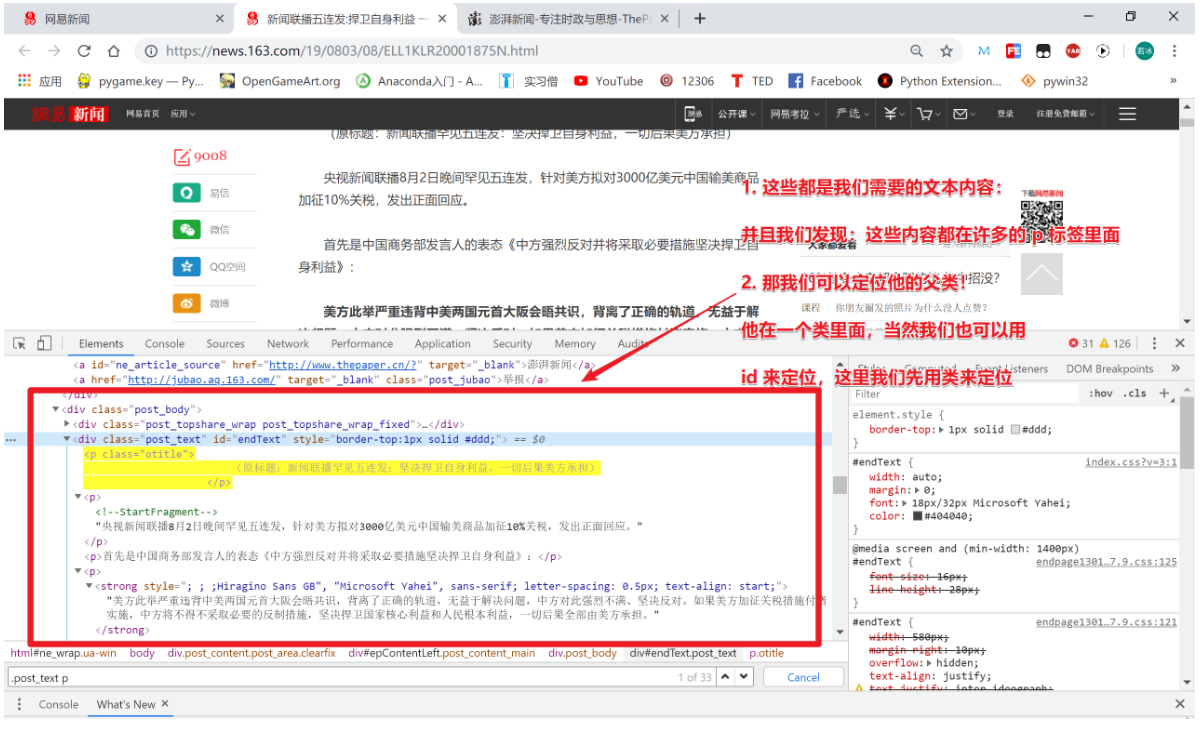
代码如下:
def get_body(self, response, item):
bodys = response.css('.post_text p::text').extract()
# l = []
# for body in bodys:
# body = body.replace('\n','')
# body = body.replace('\t','')
# l.append(body)
# item['news_body'] = str(l)
if bodys:
item['news_body'] = bodys我们现在所需要的数据都已经爬取完成。
现在,我们来写 pipline.py。
8.10 pipelines.py
首先我们先观察一下该网页的字符编码,帮助之后的数据存储,不然有可能会乱码。
右键查看源码 >>> control + F >>> 输入 charset
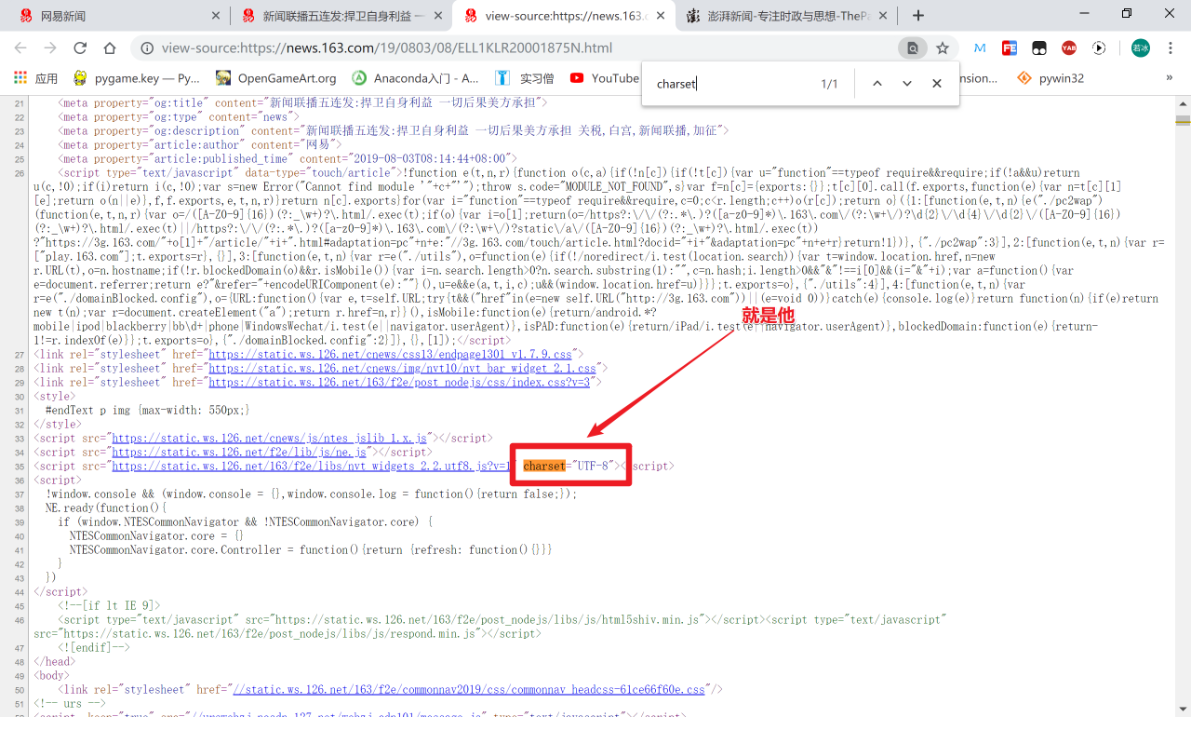
然后,我们再来了解一个基本属性:
由图片可知,该网页是由 UTF-8 而组成的。编写代码:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
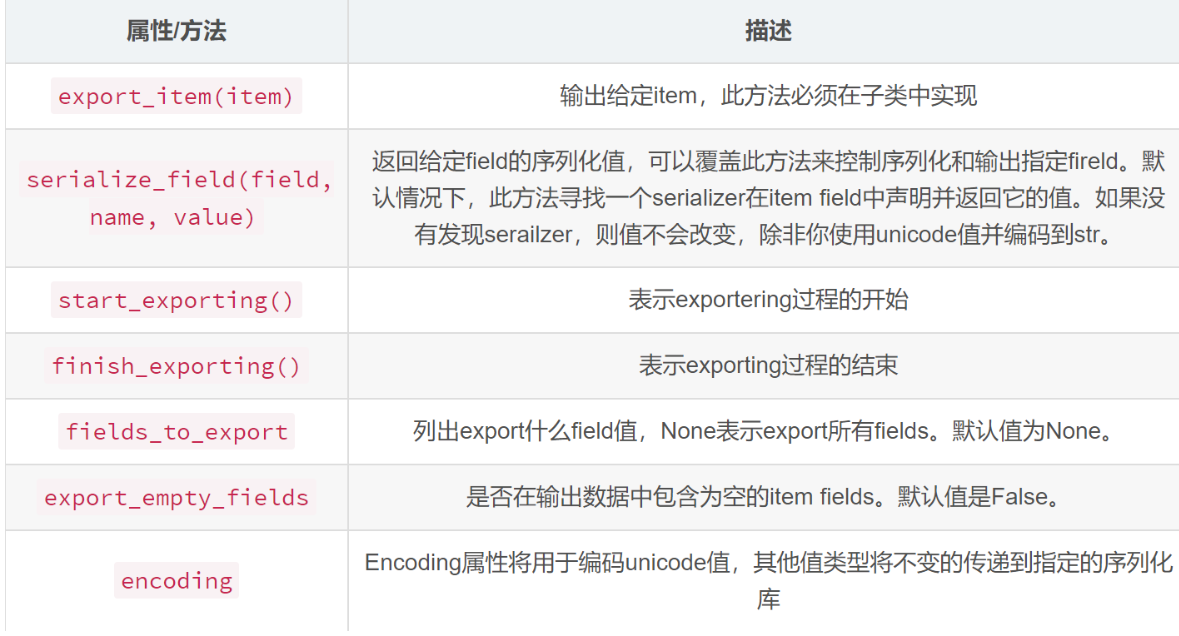
from scrapy.exporters import CsvItemExporter
class NewsPipeline(object):
def __init__(self):
# 补充: self 就是把这个属性绑定在这个类上, 以后就可以直接调用。
# 创建文件,以二进制的方式写入
self.file = open('news_data.csv', 'wb')
# 数据的导入口:self.file , 导入的编码方式
self.exporter = CsvItemExporter(self.file, encoding = 'utf-8')
# 设置好了之后, self.exporter 开始工作。
# 表示exportering过程的开始
self.exporter.start_exporting()
# 有打开文件, 存入爬取数据
# 那就要有关闭操作和已经保存的数据
def close_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item8.11 settings.py
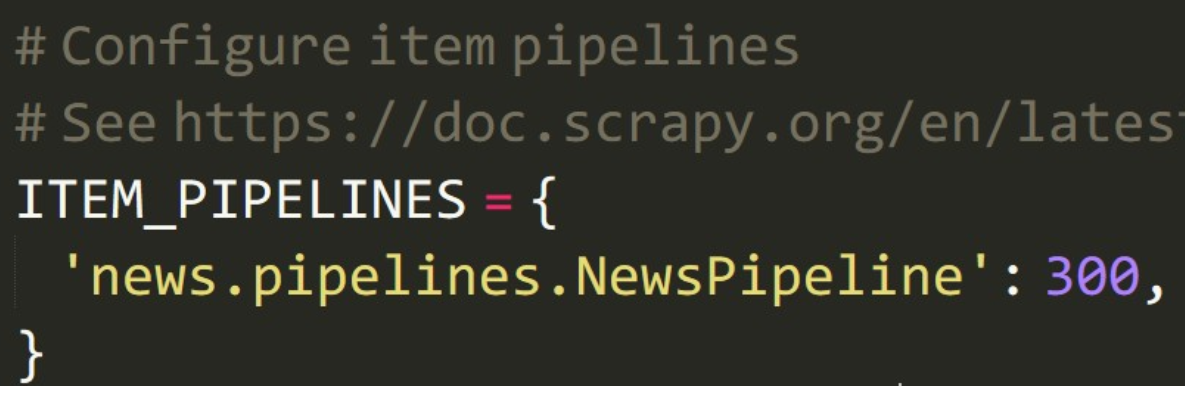
我们还需要设置一下 settings.py 文件。找到 setting.py 中的 ITEM_PIPELINES:
ITEM_PIPELINES = {
'news.pipelines.NewsPipeline': 300,
}如下图片:
运行代码:
# 要在你项目文件夹里面运行哦!
# 命令行输入以下命令运行:
scrapy crawl news163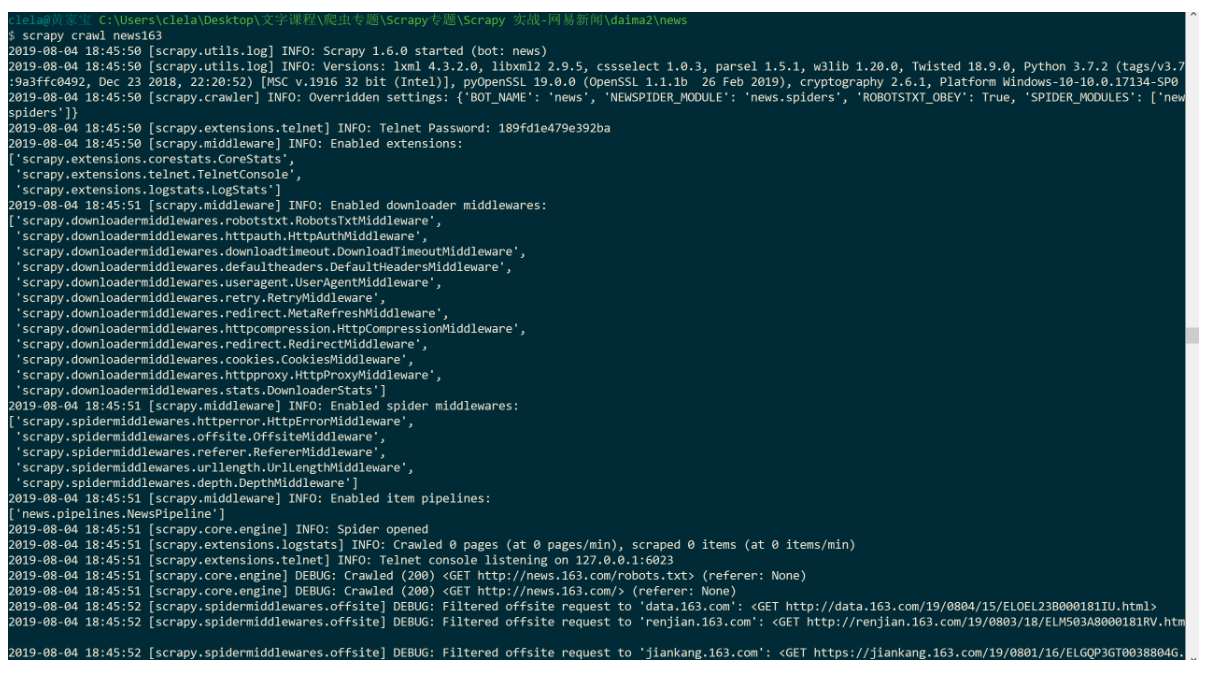
扩展技能:快速存储爬取的文件
# scrapy crawl 爬虫名称 -o 保存文件名称
scrapy crawl news163 -o data.csv有了上面的命令,我们就不用写中间件(pipeline.py)和编写 setting.py。
加速爬取:
# 1\. Configure maximum concurrent requests performed by Scrapy (default: 16)
#2\. CONCURRENT_REQUESTS = 32
# 1中是 scrapy 默认设定 1s 爬取 16 个请求
# 2\. 这里的数字是表示,同时发起多少个命令
# 建议不要改这个数值,因为你给人家改了,人家容易封你 IP ,毕竟你不能给人家带来流量
8.12 加餐:图片爬取
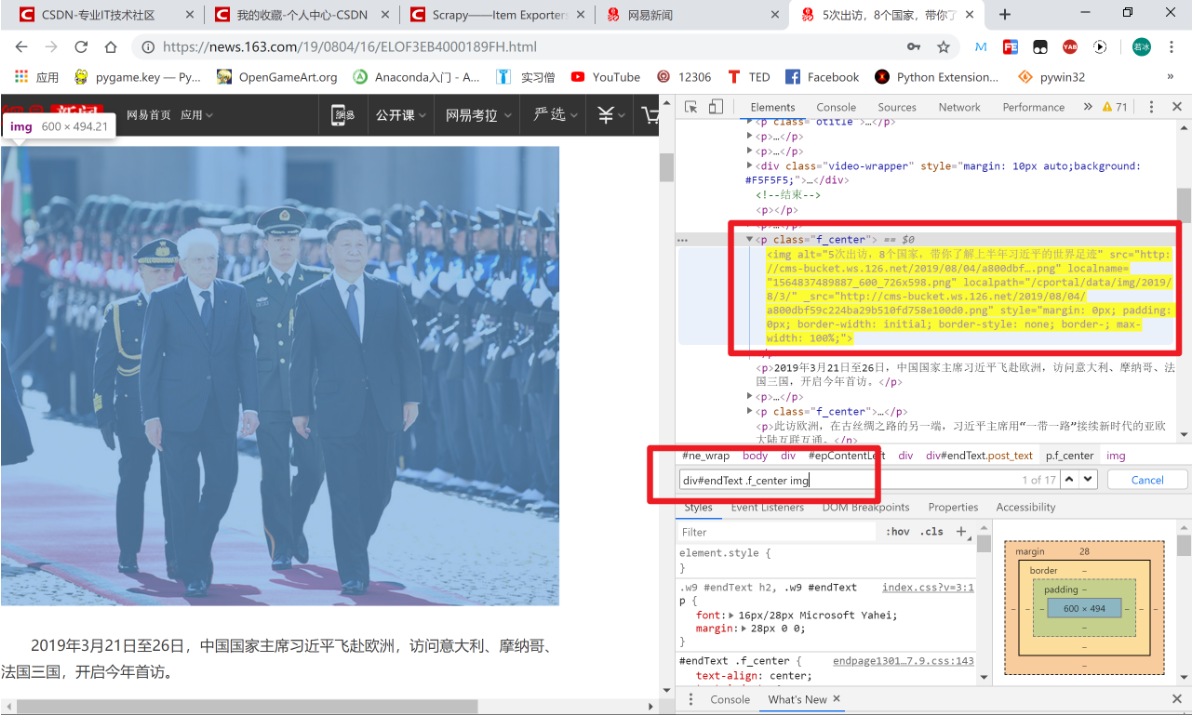
方法一: 代码如下
import requests
from bs4 import BeautifulSoup
url = 'https://news.163.com/19/0804/16/ELOF3EB4000189FH.html'
req = requests.get(url)
soup = BeautifulSoup(req.text, 'lxml')
image_url = soup.select('div#endText .f_center img')[0].get('src')
with open('image.jpg', 'wb') as f:
picture = requests.get(image_url)
f.write(picture.content)方法二:
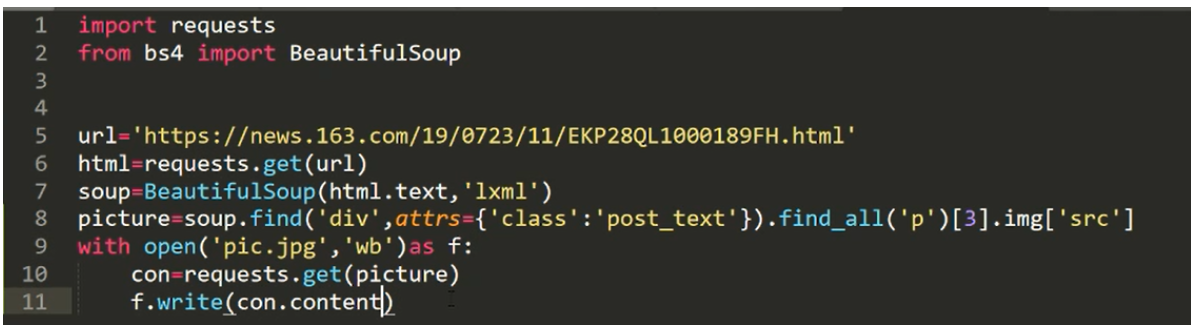
8.13 作业

爬取 http://www.animeshow.tv/ 下的 full anime list 的动漫列表,获取动漫信息并存储(存储格式不限,可以 TXT、数据库、JSON 格式等),必须要有的数据(动漫名称、动漫地址、类型、播出时间、状态、流派、摘要)
九、总结
到此本篇 Chat 基本结束了,十分感谢您的观看,由于内容及文字过多,为了帮您更好地理清思路,提高阅读效果,以下是本篇 Chat 的总结。
前端:
- 域名、开发网页使用工具等前端相关知识
- HTML 主要元素解析
爬虫基础:
- 爬虫的原理及基本流程
- Request 和 Response 概念,包含内容以及常用请求方式的介绍
Requests 及 Beautifulsoup 库的操作:
- 抓取,解析数据
- 常见问题解决
- 保存爬取数据
- 深入介绍 Python 网络模块基础 Requets Beautifulsoup 和 Cookies
爬虫专业库 Scrapy 基础:
- Scrapy 的原理与安装
- 入门使用——爬取 Quotes to Scrape 网站
- 番外篇:Scrapy 的交互模式
深入:Scrapy 实战——爬取新闻
另为了缓解零基础童鞋的阅读压力,我们在 Chat 开头也对 Python 的安装与基础知识进行了介绍。
参考文献
出于对原创的尊重,我们将在此列出本篇 Chat 文字所引用的博客与书籍:
- [1] https://www.w3school.com.cn/xpath/index.asp
- [2] 《Python3 网络爬虫开发实战》P468-P470-崔庆才
- [3] 《Python3 网络爬虫开发实战》P468-P470-崔庆才
- [4] https://www.w3school.com.cn/xpath/index.asp
再次感谢您的观看,若您在学完 HTML 基础后对前端产生兴趣,可以学习我们的下一篇 Chat,我们将对前端常用框架 Django 进行详细介绍。
欢迎关注我公众号:AI悦创,有更多更好玩的等你发现!
公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Web全栈、Linux」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh

更新日志
1c35a-于aed17-于1ce1f-于9567c-于cbb3a-于610fe-于76989-于86c50-于027da-于