
你好,我是悦创。
对于比较大型的爬虫来说,URL 管理的管理是个核心问题,管理不好,就可能重复下载,也可能遗漏下载。这里,我们设计一个 URL Pool 来管理 URL。
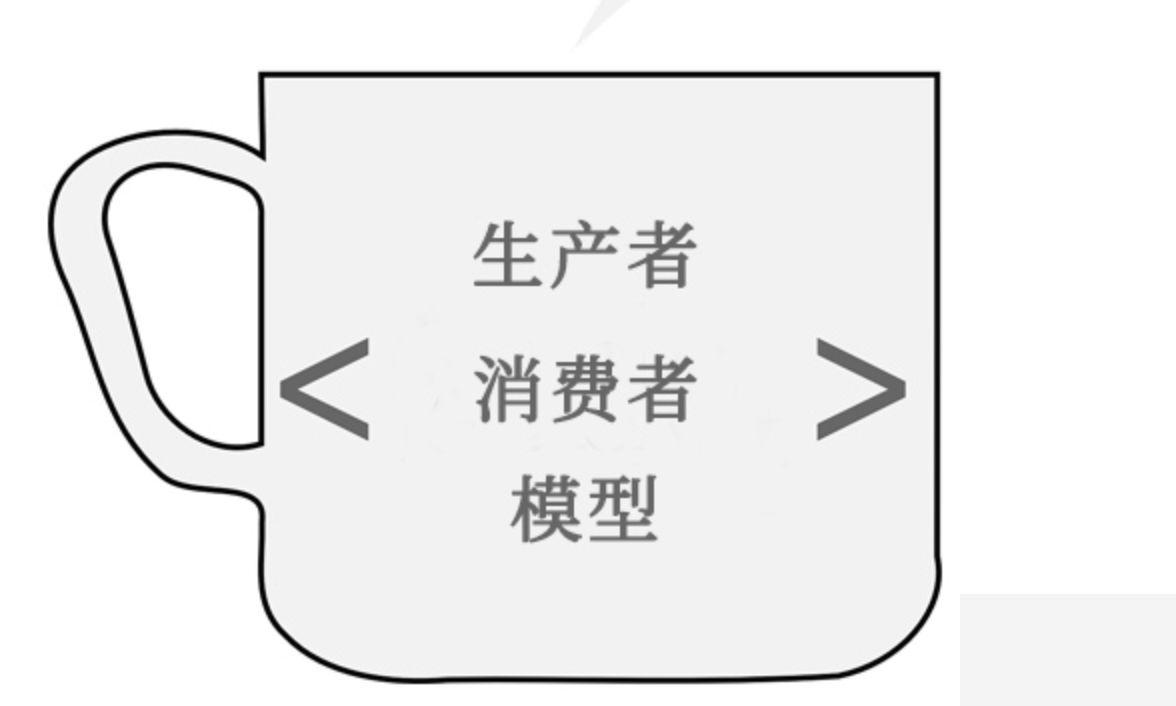
这个 URL Pool 就是一个生产者-消费者模式:
原创2023/2/4...大约 2 分钟
你好,我是悦创。
对于比较大型的爬虫来说,URL 管理的管理是个核心问题,管理不好,就可能重复下载,也可能遗漏下载。这里,我们设计一个 URL Pool 来管理 URL。
这个 URL Pool 就是一个生产者-消费者模式:
你好,我是悦创。
上一节我们实现了一个简单的再也不能简单的新闻爬虫,这个爬虫有很多槽点,估计大家也会鄙视这个爬虫。上一节最后我们讨论了这些槽点,现在我们就来去除这些槽点来完善我们的新闻爬虫。
问题我们前面已经描述清楚,解决的方法也有了,那就废话不多讲,代码立刻上(Talk is cheap, show me the code!)。

你好,我是悦创。
这个实战例子是构建一个大规模的异步新闻爬虫,但要分几步走,从简单到复杂,循序渐进的来构建这个 Python 爬虫。
要抓取新闻,首先得有新闻源,也就是抓取的目标网站。
国内的新闻网站,从中央到地方,从综合到垂直行业,大大小小有几千家新闻网站。百度新闻(https://news.baidu.com/)收录的大约两千多家。那么我们先从百度新闻入手。
打开百度新闻的网站首页:https://news.baidu.com/