
Build a RAG System with DeepSeek R1 & Ollama
Learn how to build a Retrieval-Augmented Generation (RAG) system using DeepSeek R1 and Ollama. Step-by-step guide with code examples, setup instructions, and best practices for smarter AI applications.
If you’ve ever wished you could ask questions directly to a PDF or technical manual, this guide is for you. Today, we’ll build a Retrieval-Augmented Generation (RAG) system using DeepSeek R1, an open-source reasoning powerhouse, and Ollama, the lightweight framework for running local AI models.
In this post, we’ll explore how DeepSeek R1—a model that rivals OpenAI’s o1 in performance but costs 95% less—can supercharge your RAG systems. Let’s break down why developers are flocking to this tech and how you can build your own RAG pipeline with it.
How Much Does This Local RAG System Cost?
| Component | Cost |
|---|---|
| DeepSeek R1 1.5B | Free |
| Ollama | Free |
| 16GB RAM PC | $0 |
DeepSeek R1’s 1.5B model shines here because:
- Focused retrieval: Only 3 document chunks feed into each answer
- Strict prompting: “I don’t know” prevents hallucinations
- Local execution: Zero latency vs. cloud APIs
What You’ll Need
Before we code, let’s set up our toolkits:
1. Ollama
Ollama lets you run models like DeepSeek R1 locally.
- Download: https://ollama.com/
- Install, then open your terminal and run:
ollama run deepseek-r1 # For the 7B model (default)
2. DeepSeek R1 Model Variants
DeepSeek R1 comes in sizes from 1.5B to 671B parameters. For this demo, we’ll use the 1.5B model—perfect for lightweight RAG:
ollama run deepseek-r1:1.5bPro tip: Larger models like 70B offer better reasoning but require more RAM. Start small, then scale up!

Building the RAG Pipeline: Code Walkthrough
Step 1: Import Libraries
We’ll use:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama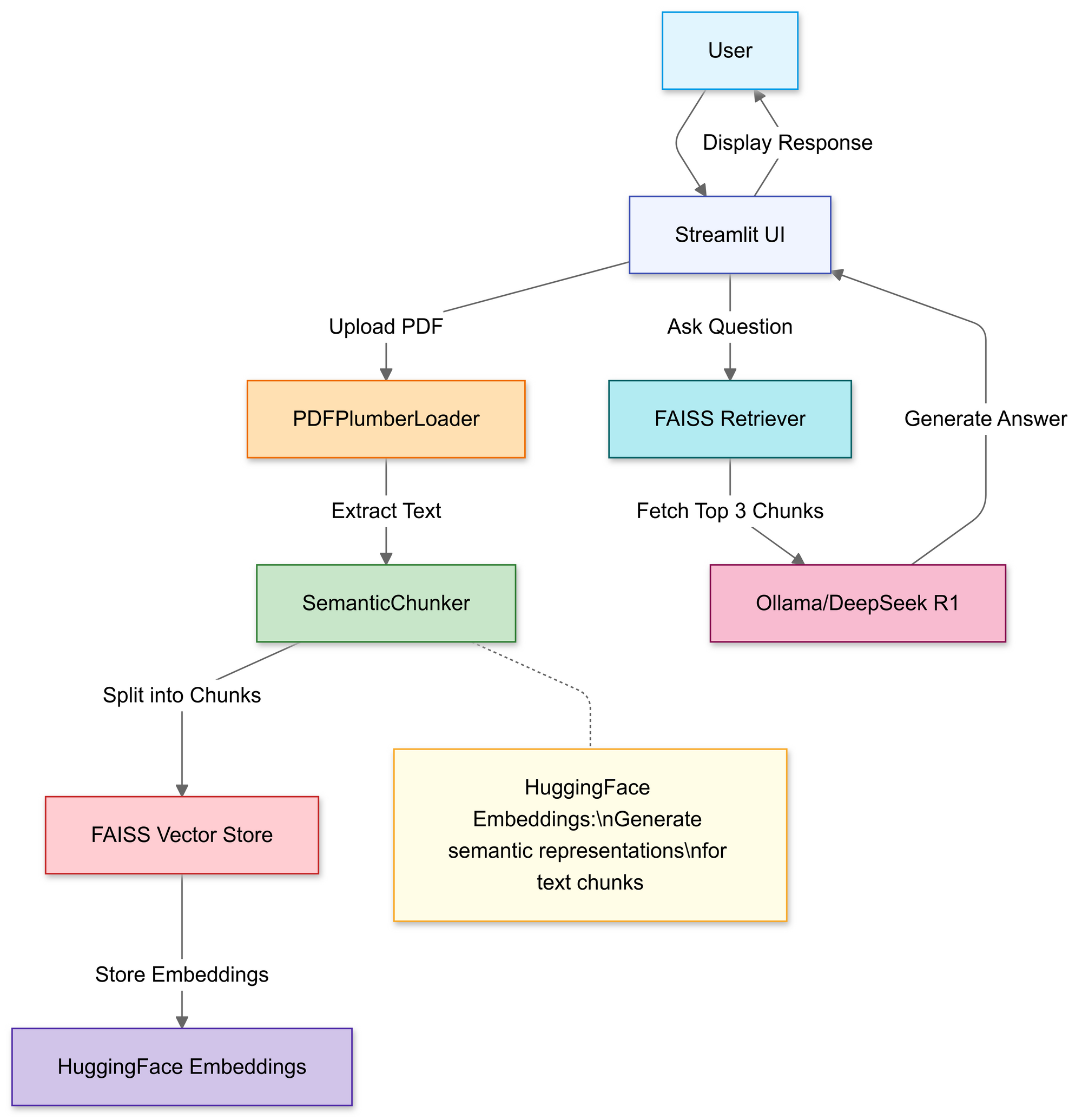
Step 2: Upload & Process PDFs
In this section, you use Streamlit’s file uploader to allow users to select a local PDF file.
# Streamlit file uploader
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file:
# Save PDF temporarily
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Load PDF text
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()Once uploaded, the PDFPlumberLoader function extracts text from the PDF, readying it for the next stage of the pipeline. This approach is convenient because it takes care of reading the file content without demanding extensive manual parsing.
Step 3: Chunk Documents Strategically
We want to use the RecursiveCharacterTextSplitter, the code breaks down the original PDF text into smaller segments (chunks). Let's explain the concepts of good chunking vs bad chunking here:
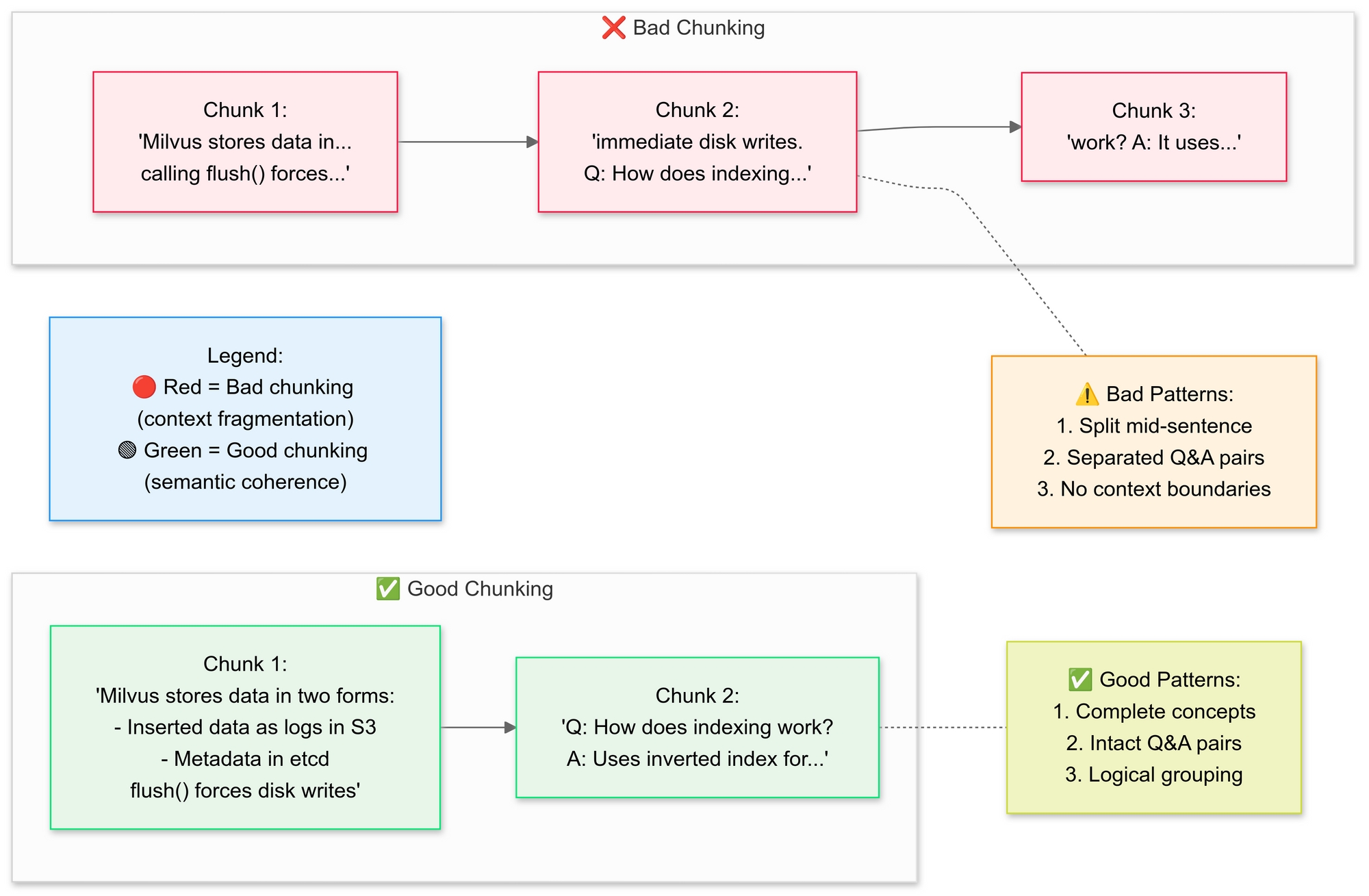
Why semantic chunking?
- Groups related sentences (e.g., "How Milvus stores data" stays intact)
- Avoids splitting tables or diagrams
# Split text into semantic chunks
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)This step preserves context by overlapping segments slightly, which helps the language model answer questions more accurately. Small, well-defined document chunks also make searches more efficient and relevant.
Step 4: Create a Searchable Knowledge Base
After splitting, the pipeline generates vector embeddings for the segments and stores them in a FAISS index.
# Generate embeddings
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# Connect retriever
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Fetch top 3 chunksThis transforms text into a numerical representation that is much easier to query. Queries later run against this index to find the most contextually relevant chunks.
Step 5: Configure DeepSeek R1
Here, you instantiate a RetrievalQA chain using Deepseek R1 1.5B as the local LLM.
llm = Ollama(model="deepseek-r1:1.5b") # Our 1.5B parameter model
# Craft the prompt template
prompt = """
1. Use ONLY the context below.
2. If unsure, say "I don’t know".
3. Keep answers under 4 sentences.
Context: {context}
Question: {question}
Answer:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)This template forces the model to ground answers in your PDF’s content. By wrapping the language model with a retriever tied to the FAISS index, any queries made through the chain will look up context from the PDF’s content, making the answers grounded in the source material.
Step 6: Assemble the RAG Chain
Next, you can tie together the uploading, chunking, and retrieval steps into a coherent pipeline.
# Chain 1: Generate answers
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Chain 2: Combine document chunks
document_prompt = PromptTemplate(
template="Context:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
# Final RAG pipeline
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)This is the core of the RAG (Retrieval-Augmented Generation) design, providing the large language model with verified context instead of having it rely purely on its internal training.
Step 7: Launch the Web Interface
Finally, the code uses Streamlit’s text input and write functions so users can type in questions and view responses right away.
# Streamlit UI
user_input = st.text_input("Ask your PDF a question:")
if user_input:
with st.spinner("Thinking..."):
response = qa(user_input)["result"]
st.write(response)As soon as the user enters a query, the chain retrieves the best matching chunks, feeds them into the language model, and displays an answer. With the langchain library properly installed, the code should work now without triggering the missing module error.
Ask and submit questions and get instant answers!
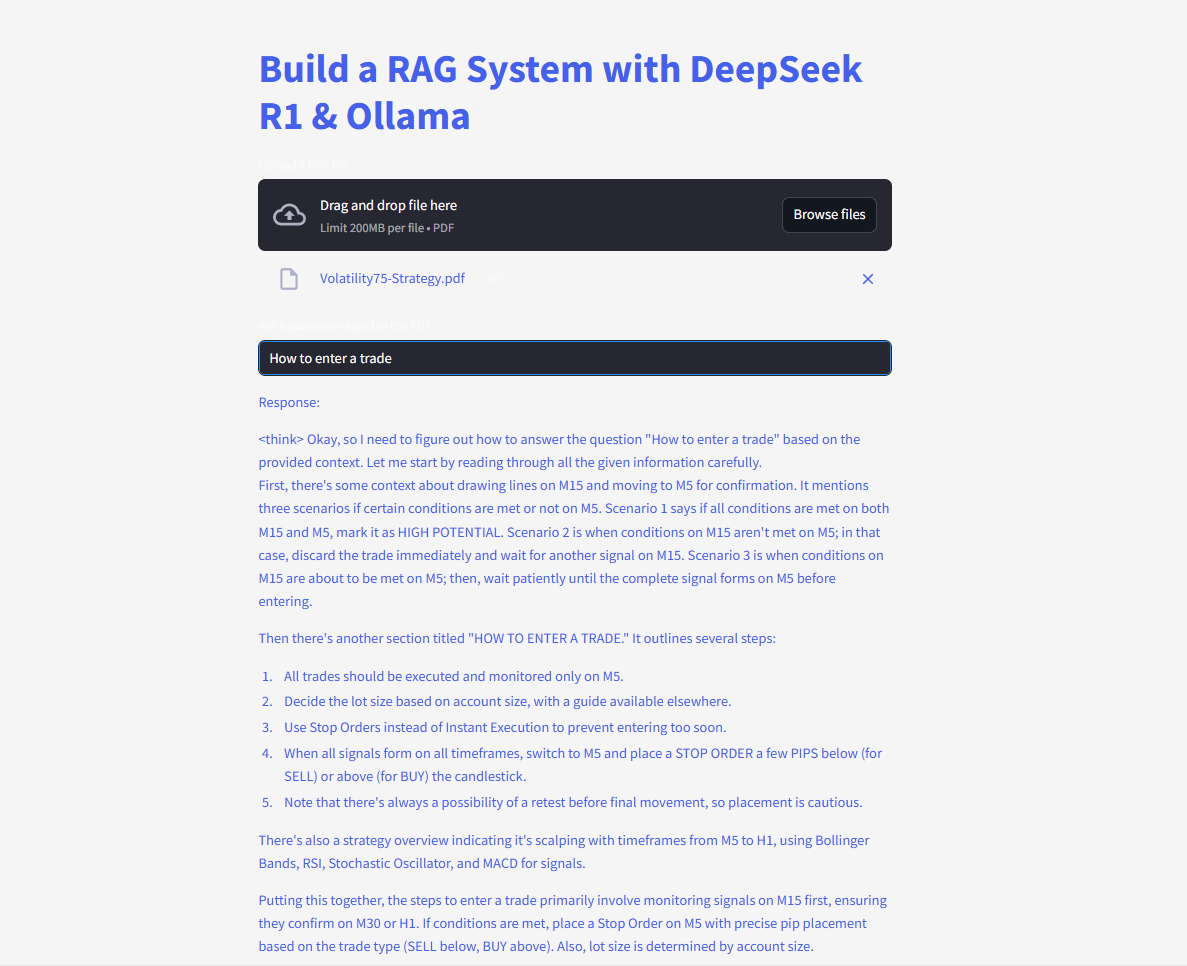
Here's the complete code:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains import RetrievalQA
# color palette
primary_color = "#1E90FF"
secondary_color = "#FF6347"
background_color = "#F5F5F5"
text_color = "#4561e9"
# Custom CSS
st.markdown(f"""
<style>
.stApp {{
background-color: {background_color};
color: {text_color};
}}
.stButton>button {{
background-color: {primary_color};
color: white;
border-radius: 5px;
border: none;
padding: 10px 20px;
font-size: 16px;
}}
.stTextInput>div>div>input {{
border: 2px solid {primary_color};
border-radius: 5px;
padding: 10px;
font-size: 16px;
}}
.stFileUploader>div>div>div>button {{
background-color: {secondary_color};
color: white;
border-radius: 5px;
border: none;
padding: 10px 20px;
font-size: 16px;
}}
</style>
""", unsafe_allow_html=True)
# Streamlit app title
st.title("Build a RAG System with DeepSeek R1 & Ollama")
# Load the PDF
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file is not None:
# Save the uploaded file to a temporary location
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Load the PDF
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
# Split into chunks
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
# Instantiate the embedding model
embedder = HuggingFaceEmbeddings()
# Create the vector store and fill it with embeddings
vector = FAISS.from_documents(documents, embedder)
retriever = vector.as_retriever(search_type="similarity", search_kwargs={"k": 3})
# Define llm
llm = Ollama(model="deepseek-r1")
# Define the prompt
prompt = """
1. Use the following pieces of context to answer the question at the end.
2. If you don't know the answer, just say that "I don't know" but don't make up an answer on your own.\n
3. Keep the answer crisp and limited to 3,4 sentences.
Context: {context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
llm_chain = LLMChain(
llm=llm,
prompt=QA_CHAIN_PROMPT,
callbacks=None,
verbose=True)
document_prompt = PromptTemplate(
input_variables=["page_content", "source"],
template="Context:\ncontent:{page_content}\nsource:{source}",
)
combine_documents_chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_variable_name="context",
document_prompt=document_prompt,
callbacks=None)
qa = RetrievalQA(
combine_documents_chain=combine_documents_chain,
verbose=True,
retriever=retriever,
return_source_documents=True)
# User input
user_input = st.text_input("Ask a question related to the PDF :")
# Process user input
if user_input:
with st.spinner("Processing..."):
response = qa(user_input)["result"]
st.write("Response:")
st.write(response)
else:
st.write("Please upload a PDF file to proceed.")欢迎关注我公众号:AI悦创,有更多更好玩的等你发现!
公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Linux、Web 全栈」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh
