
NP-Hard problems
NP-Hard Problems
- NP-Non deterministic Polynomial time complexity
- A non deterministic algorithm can exhibit different behaviours on different runs for the same input variables.
NP-Hard Problems: Exhaustive search
Creating all possible candidates for the solution and checking whether each candidate satisfies the problem's statement
It will find a solution – within time and space constraints
The time / space cost is proportional to the number of candidate solutions – which tends to grow very quickly as the size of the problem increases
It is used when the when the problem size is limited (it is impractical when the size is large)
Travelling salesman problem
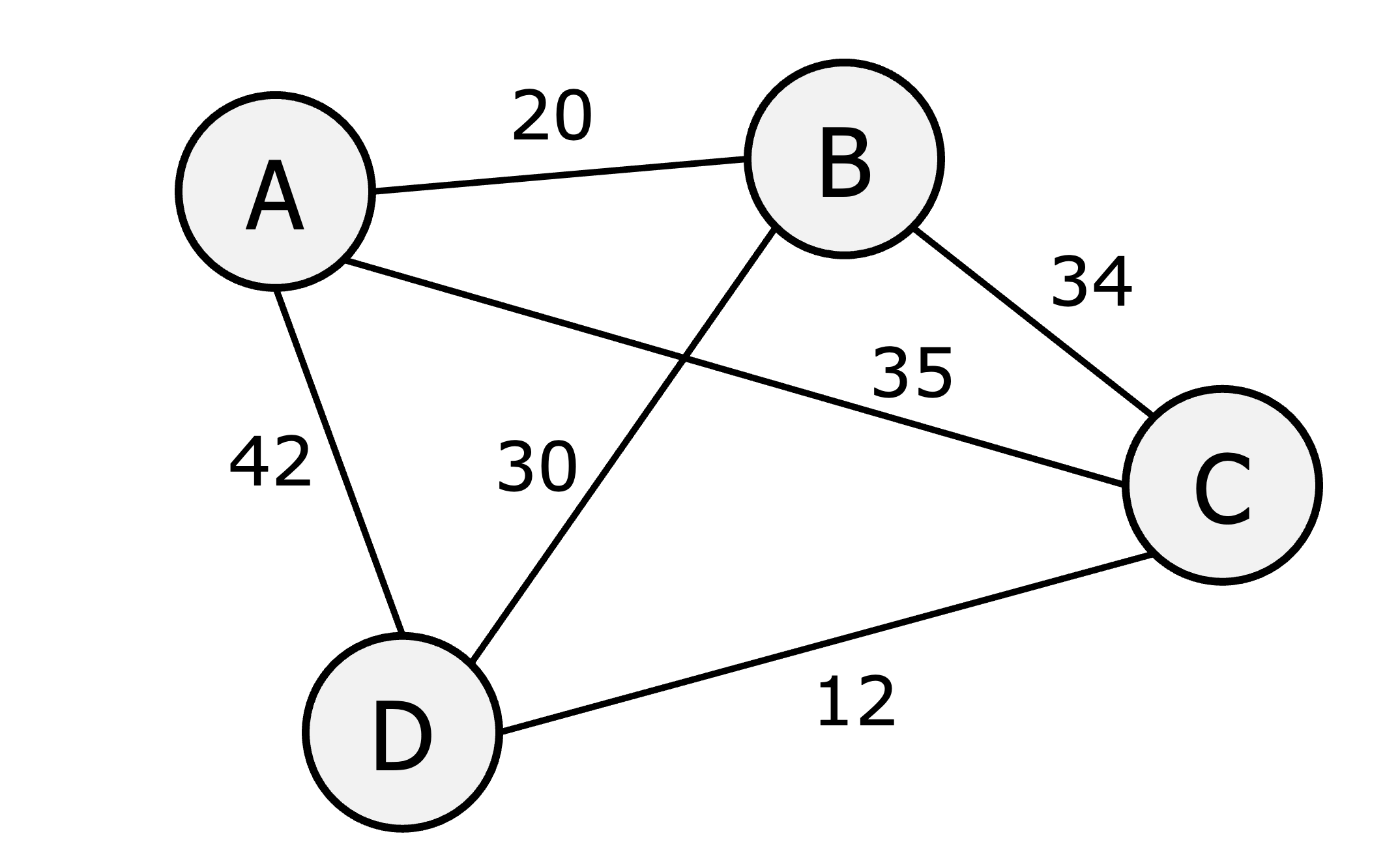
n cities
Each is connected to every other, with a cost
Salesman has to start from any city, visit every city, and return to the city s/he started
S/he has to do this with the least cost
Exhaustive search: pseudocode for travelling salesman problem
allPossibleRoutes ← allPermutationsOfTheRoutes()
r ← allPossibleRoutes[0]
best_route ← r
best_score ← score(r)
FOR i ← 1 TO SIZE (allPossibleRoutes) DO
r ← allPossibleRoutes[i]
if score(r) < best_score
best_route ← r
best_score ← score(r)from itertools import permutations
# 定义城市之间的距离
distances = {
('A', 'B'): 20, ('A', 'C'): 35, ('A', 'D'): 42,
('B', 'A'): 20, ('B', 'C'): 34, ('B', 'D'): 30,
('C', 'A'): 35, ('C', 'B'): 34, ('C', 'D'): 12,
('D', 'A'): 42, ('D', 'B'): 30, ('D', 'C'): 12
}
# 计算给定路线的总成本
def calculate_route_cost(route):
cost = 0
for i in range(len(route) - 1):
cost += distances[(route[i], route[i + 1])]
# 回到起点的成本
cost += distances[(route[-1], route[0])]
return cost
# 所有城市
cities = ['A', 'B', 'C', 'D']
# 生成所有可能的路线
all_possible_routes = permutations(cities)
# 初始化最佳路线和最佳成本
best_route = None
best_score = float('inf')
# 遍历所有可能的路线,找出成本最小的路线
for route in all_possible_routes:
current_score = calculate_route_cost(route)
if current_score < best_score:
best_route = route
best_score = current_score
# 输出结果
print("最佳路线:", best_route)
print("最低成本:", best_score)from itertools import permutations # 引入 permutations 函数,用于生成城市的所有排列组合(即所有可能的路线)
# 定义城市之间的距离,使用字典表示,键是城市对(元组),值是它们之间的距离
distances = {
('A', 'B'): 20, ('A', 'C'): 35, ('A', 'D'): 42,
('B', 'A'): 20, ('B', 'C'): 34, ('B', 'D'): 30,
('C', 'A'): 35, ('C', 'B'): 34, ('C', 'D'): 12,
('D', 'A'): 42, ('D', 'B'): 30, ('D', 'C'): 12
}
# 定义一个函数,用于计算给定路线的总成本
def calculate_route_cost(route):
cost = 0 # 初始化总成本为0
# 遍历路线中的每一对相邻城市,累加它们之间的成本
for i in range(len(route) - 1):
cost += distances[(route[i], route[i + 1])] # 将相邻城市间的距离加到总成本上
# 加上回到起点的成本(最后一个城市到第一个城市)
cost += distances[(route[-1], route[0])]
return cost # 返回该路线的总成本
# 定义所有城市的列表
cities = ['A', 'B', 'C', 'D']
# 生成所有可能的路线(即所有城市的排列组合)
all_possible_routes = permutations(cities)
# 初始化最佳路线为 None,因为一开始还没有最佳路线
# 初始化最佳成本为正无穷大,这样在第一次比较时任何路线都会比它小
best_route = None
best_score = float('inf')
# 遍历所有可能的路线,找出成本最小的路线
for route in all_possible_routes:
current_score = calculate_route_cost(route) # 计算当前路线的总成本
# 如果当前路线的成本比已知的最佳成本更小,则更新最佳路线和最佳成本
if current_score < best_score:
best_route = route # 更新最佳路线
best_score = current_score # 更新最佳成本
# 输出结果:最佳路线和最低成本
print("最佳路线:", best_route)
print("最低成本:", best_score)from itertools import permutations # 引入 permutations 函数,用于生成城市的所有排列组合(即所有可能的路线)
# 定义城市之间的距离,使用字典表示,键是城市对(元组),值是它们之间的距离
distances = {
('A', 'B'): 20, ('A', 'C'): 35, ('A', 'D'): 42,
('B', 'A'): 20, ('B', 'C'): 34, ('B', 'D'): 30,
('C', 'A'): 35, ('C', 'B'): 34, ('C', 'D'): 12,
('D', 'A'): 42, ('D', 'B'): 30, ('D', 'C'): 12
}
# 定义一个函数,用于计算给定路线的总成本
def calculate_route_cost(route):
cost = 0 # 初始化总成本为0
# 遍历路线中的每一对相邻城市,累加它们之间的成本
for i in range(len(route) - 1):
cost += distances[(route[i], route[i + 1])] # 将相邻城市间的距离加到总成本上
# 加上回到起点的成本(最后一个城市到第一个城市)
cost += distances[(route[-1], route[0])]
return cost # 返回该路线的总成本
# 定义所有城市的列表
cities = ['A', 'B', 'C', 'D']
# 生成所有可能的路线(即所有城市的排列组合)
all_possible_routes = permutations(cities)
# 遍历所有可能的路线,找出成本最小的路线
for route in all_possible_routes:
current_score = calculate_route_cost(route) # 计算当前路线的总成本
# 将路线加上回到起点的城市和总成本,一并输出
print(list(route) + [route[0], current_score])在 calculate_route_cost 函数中,len(route) - 1 的原因是我们需要计算相邻城市之间的成本,但不需要在最后一个城市之后再访问一个不存在的城市。具体来说:
- 假设
route = ['A', 'B', 'C', 'D'],这是一个可能的行程路线。 len(route) - 1的目的是确保我们只遍历到倒数第二个城市的索引位置。- 在循环中,我们逐对计算每两个相邻城市之间的成本,即:
A -> BB -> CC -> D
- 这时,循环已经完成了
A -> B -> C -> D的成本计算。 - 然后,最后我们手动添加从最后一个城市
D回到起始城市A的成本,这样就完整了一个环形路线。
如果不减去 1,循环会尝试访问一个超出索引范围的元素,比如 route[4](假设 route 长度为 4),这会导致错误。
Travelling Salesman worked examples with code
import itertools # python library for handling iterators
# extremely useful!
dists = [['A','B',20],['A','C',35],['A','D',42], # list of all edges (distances between cities)
['B','A',20],['B','C',34],['B','D',30], # could be represented as adjacency matrix
['C','A',35],['C','B',34],['C','D',12],
['D','A',42],['D','B',30],['D','C',12]]
def get_and_convert_perm_list(dests): # get all the permutations, i.e. possible routes
perm_list = list(itertools.permutations(dests)) # this outputs a list of tuples
new_perm_list = [] # convert to a list of lists
for item in perm_list: # (easier to work with)
new_perm_list.append(list(item))
return new_perm_list
def TSP_get_dists(dests, dists):
results = [] # we will build a list of results
perm_list = get_and_convert_perm_list(dests)
for item in perm_list: # for each permutation (i.e. route)
item.append(item[0]) # add the origin as the destination
total_dist = 0 # initialise total distance
for i in range(len(item)-1): # iterate through each permutation
for dist in dists: # match each pair in permutation
if item[i] == dist[0] and item[i+1] == dist[1]: # with appropriate pair in dist
total_dist = total_dist + dist[2] # add cost to total distance
if i == len(item)-2: # if we've gone through the whole permutation
item.append(total_dist) # append the total cost to the permutation
print(item) # print the permutation with cost for convenience
results.append(item) # append the permutation with cost to results
return results # return results list
TSP_get_dists(['A','B','C','D'],dists) # callimport itertools # 导入Python库 itertools,用于处理迭代器,尤其适用于生成排列和组合等。
# 定义一个包含城市间距离的列表,每个元素表示一个边,包含两个城市和它们之间的距离。
dists = [['A','B',20],['A','C',35],['A','D',42], # 边的列表(城市之间的距离)
['B','A',20],['B','C',34],['B','D',30], # 可以通过邻接矩阵来表示,但这里用列表表示
['C','A',35],['C','B',34],['C','D',12],
['D','A',42],['D','B',30],['D','C',12]]
# 定义函数 `get_and_convert_perm_list`,用于获取目的地的所有排列(即所有可能的行程)。
def get_and_convert_perm_list(dests): # 获取所有排列,即所有可能的路线
perm_list = list(itertools.permutations(dests)) # 使用 itertools.permutations 输出一个包含所有排列的元组列表
new_perm_list = [] # 初始化一个新列表,用于存储列表格式的排列
for item in perm_list: # 遍历每个排列(它是一个元组)
new_perm_list.append(list(item)) # 将元组转换为列表并添加到新列表中
return new_perm_list # 返回转换后的排列列表
# 定义 TSP_get_dists 函数,计算所有排列(路线)的总距离。
def TSP_get_dists(dests, dists):
results = [] # 初始化一个空列表,用于存储结果(路线及其总成本)
perm_list = get_and_convert_perm_list(dests) # 获取所有目的地的排列(可能的路线)
# 遍历每条排列(每条路线)
for item in perm_list:
item.append(item[0]) # 将起始城市添加到排列的末尾,使其成为一个环(回到起始点)
total_dist = 0 # 初始化路线的总距离
# 遍历排列中的每一对连续城市
for i in range(len(item)-1):
# 遍历 dists 列表,匹配当前城市对的距离
for dist in dists:
# 如果排列中的当前城市对与 dists 中的城市对匹配
if item[i] == dist[0] and item[i+1] == dist[1]:
total_dist = total_dist + dist[2] # 将距离添加到总距离中
# 如果已遍历到排列的最后一对城市
if i == len(item)-2:
item.append(total_dist) # 将总距离添加到排列中
print(item) # 打印带有总距离的排列(用于方便查看)
results.append(item) # 将带有总距离的排列添加到结果列表中
return results # 返回结果列表,包含每条路线及其总成本
# 调用 TSP_get_dists 函数,传入目的地列表 ['A', 'B', 'C', 'D'] 和距离列表 dists
TSP_get_dists(['A','B','C','D'],dists) # 执行函数并输出每条路线及其总成本- 列表题目+for 题目:使用循环实现列表的全排列
NP-Hard Problems: Heuristics
A heuristic function produces a solution in a reasonable time frame that is good enough for solving the problem.
The solution may not be the best solution.
The solution might still be valuable because it does not take a long time to find it.
Heuristic algorithms
Don’t promise to find the best solution.
Quickly find a ‘good enough’ solution.
There are several heuristic algorithms that can solve the travelling salesmen problem. For example:
Nearest neighbour (greedy algorithm):
The salesman starts at a random city and visits the nearest city until all have been visited
Nearest neighbour
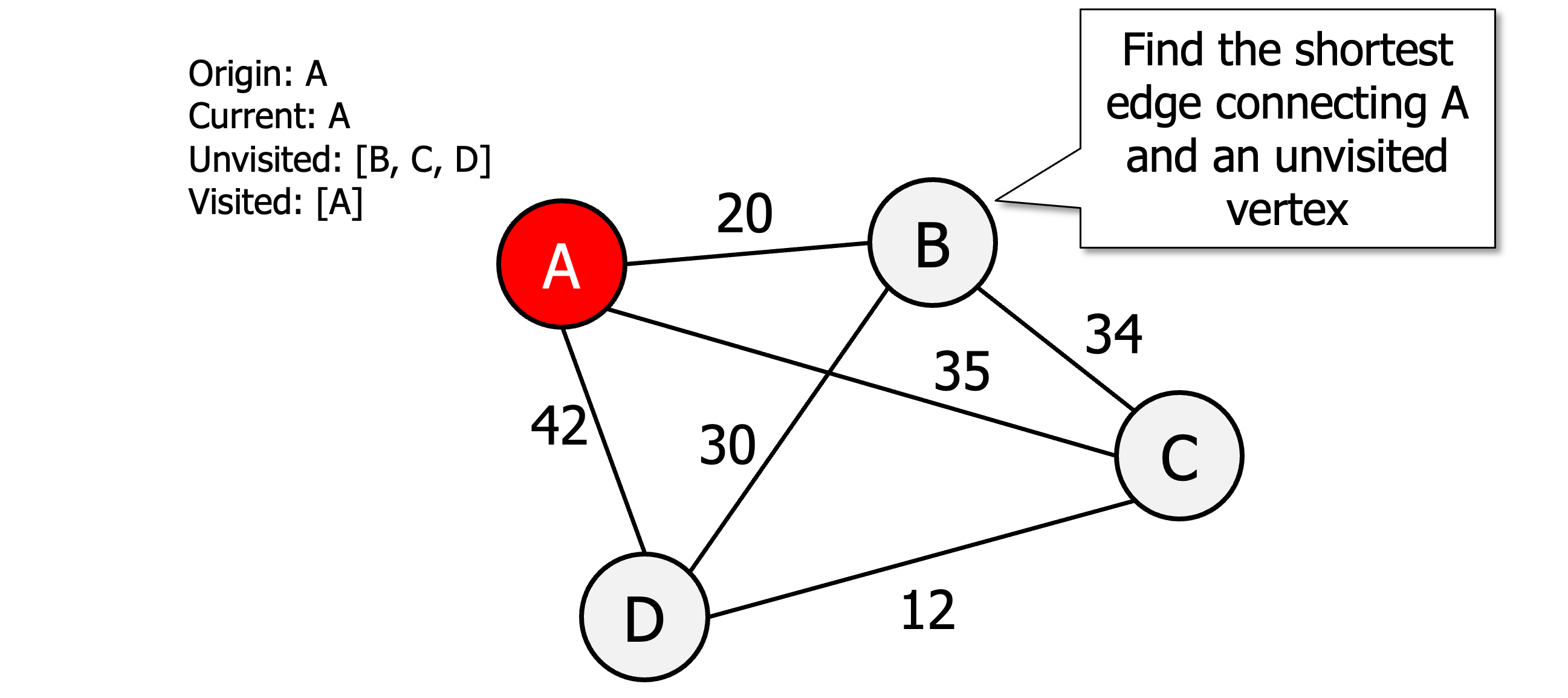
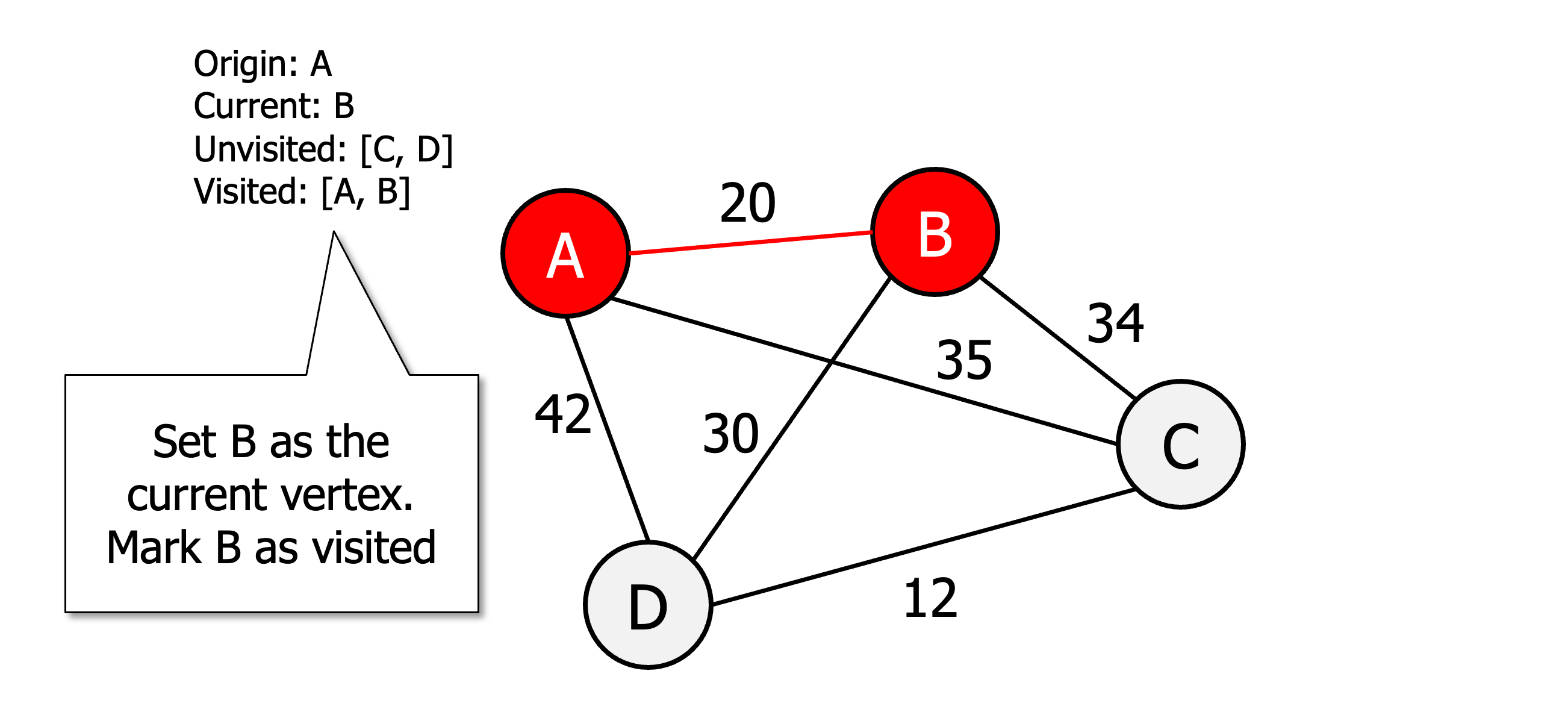
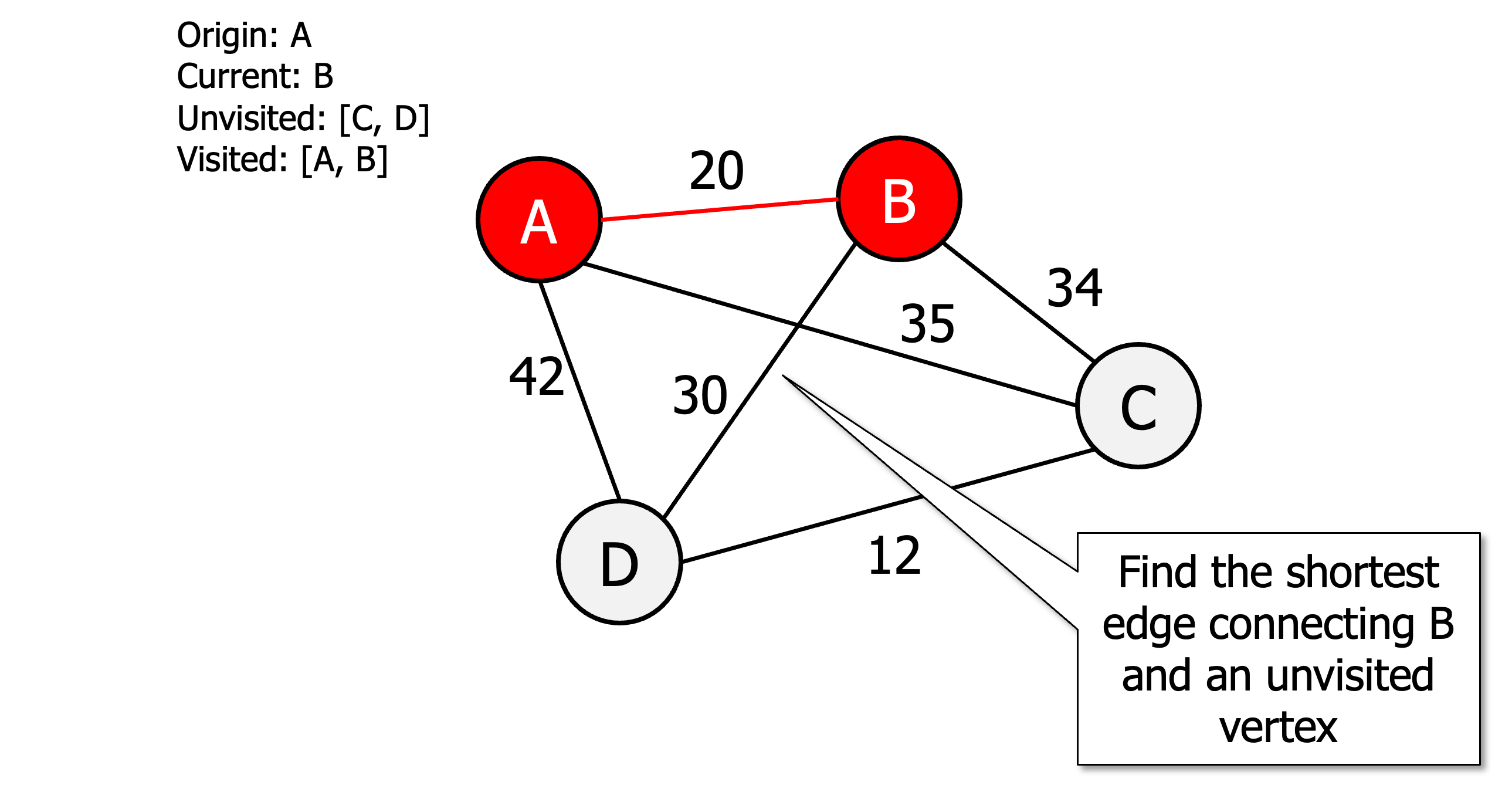
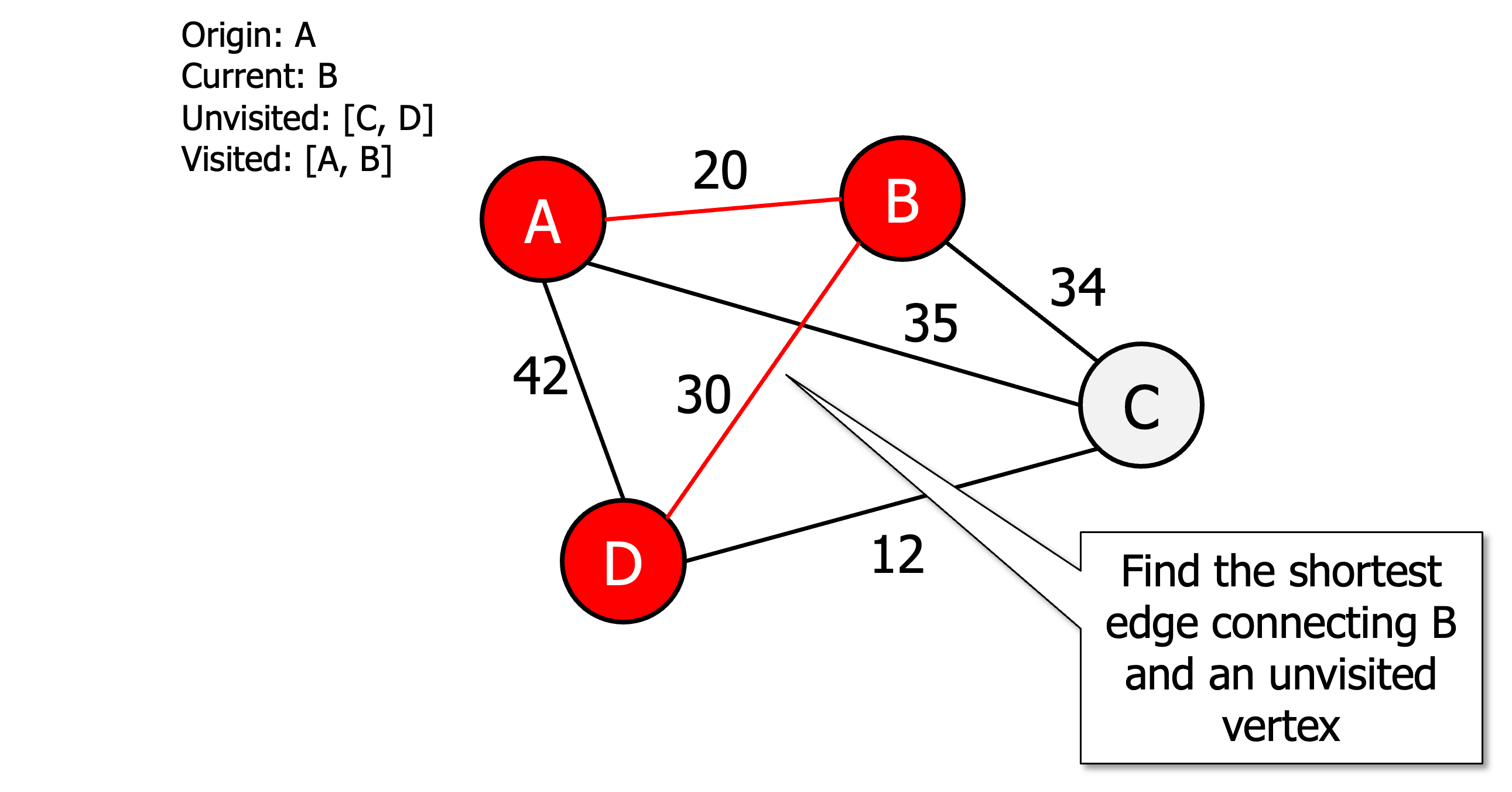
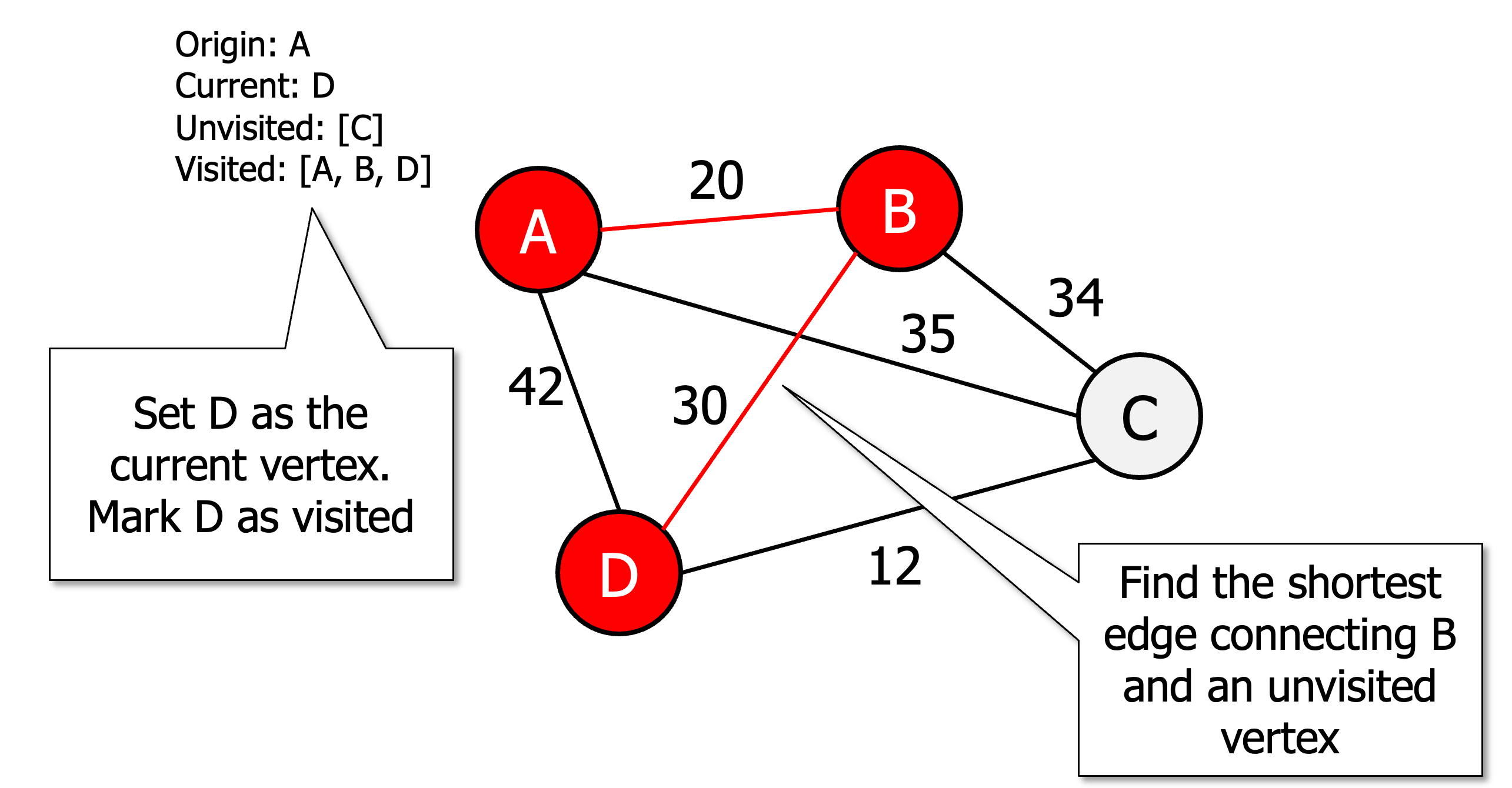
Initialise all vertices as unvisited
Select an arbitrary vertex, set it as the current vertex u and mark it as visited.
Find the shortest edge connecting u and an unvisited vertex v.
Set v as the current vertex u. Mark v as visited.
If all the vertices are visited then terminate (moving back to origin) otherwise go to step 3.
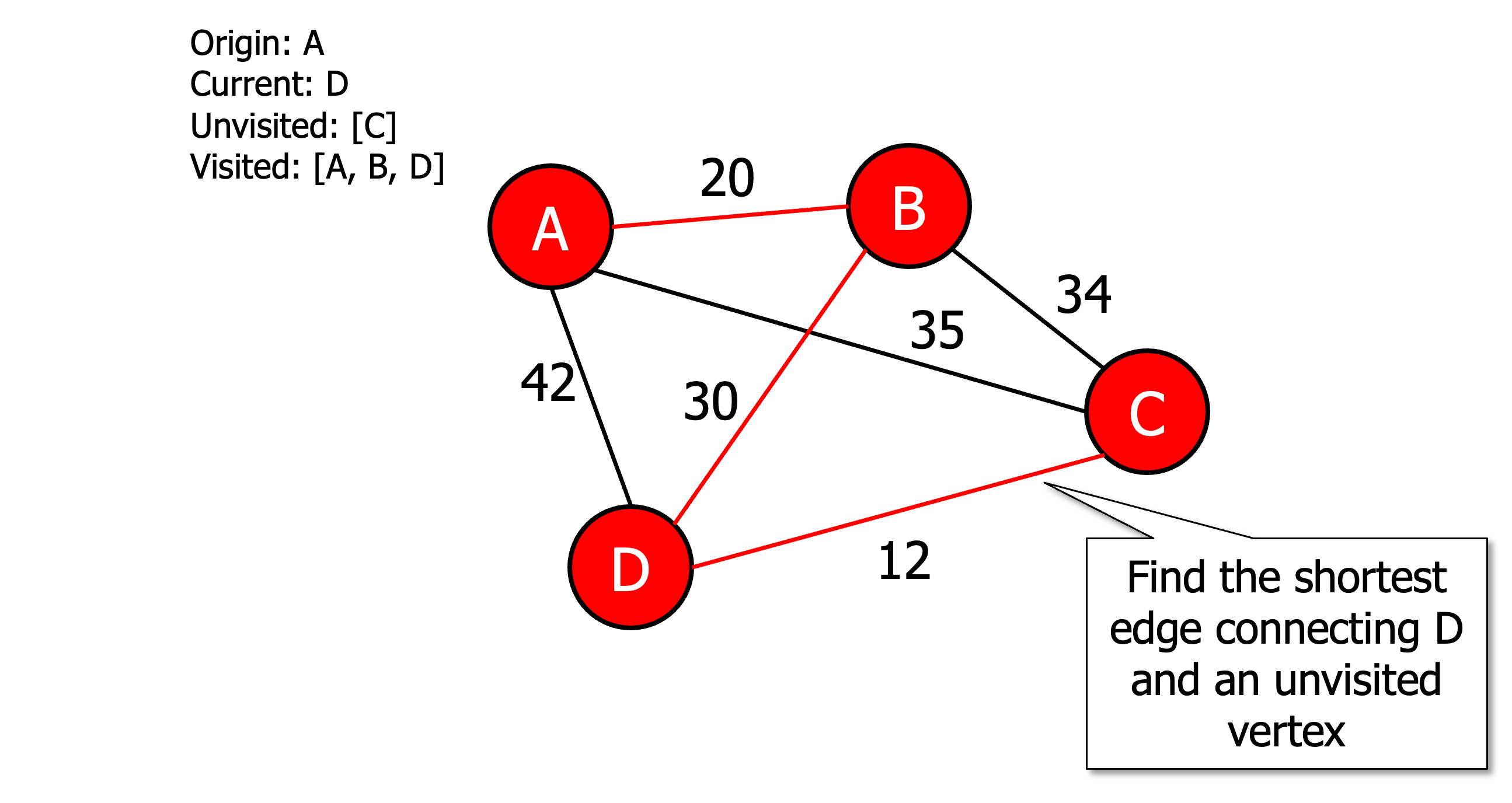
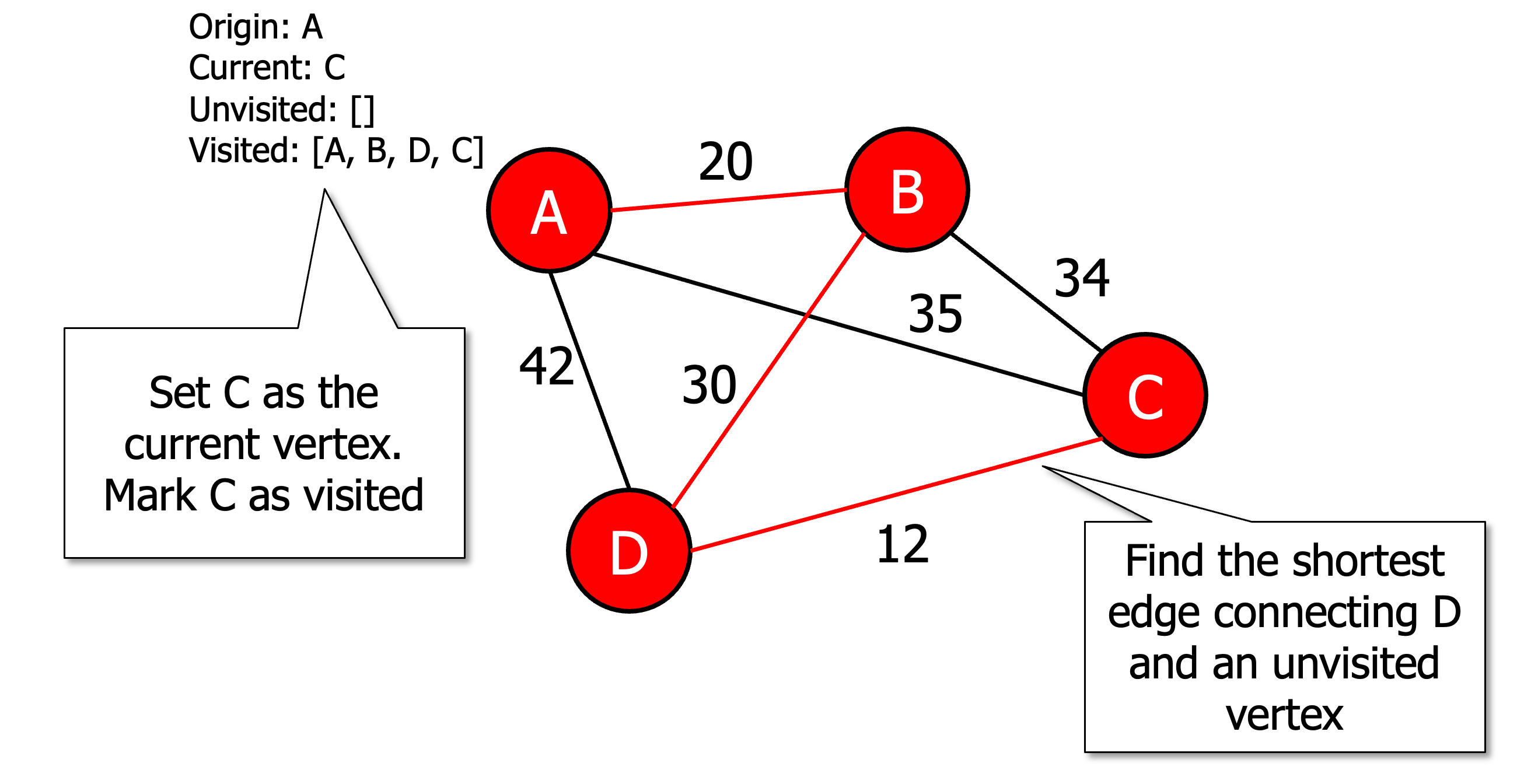
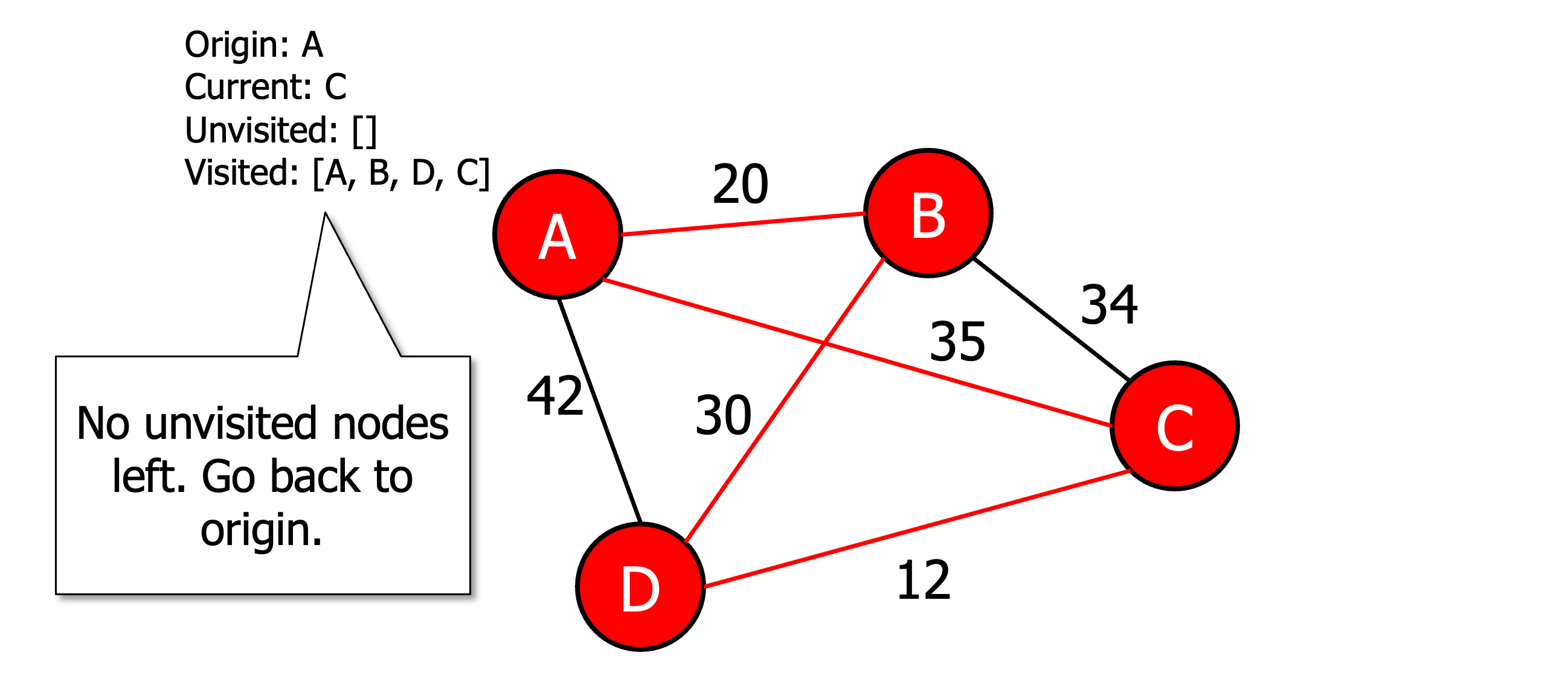
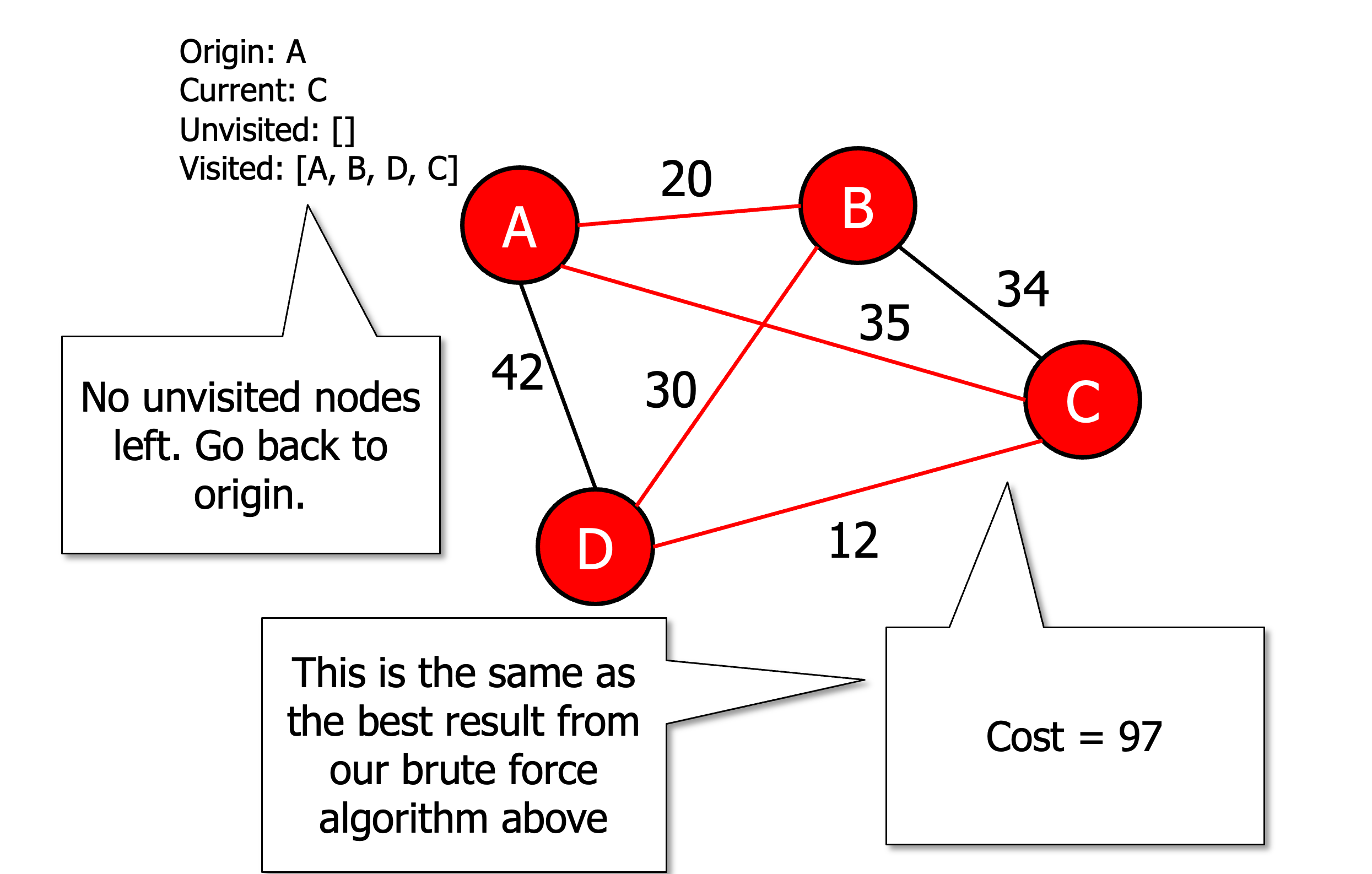
Heuristic algorithms
So a heuristic solution can be as good as the optimal result!
Plus way faster and more space efficient
However, it may not be so accurate for more complex problems
Nearest neighbour: pseudocode
unvisited ← remaining vertices
visited ← []
connections ← NULL
u ← unvisited[0]
visited ← visited + u
unvisited ← unvisited - u
while (unvisited ≠ NULL )
Find edge e = (u, v) such that:
1. u ∈ visited
2. v ∈ unvisited
3. e has smallest cost
u ← v
connections ← connections + e
visited ← visited + v
unvisited ← unvisited - v# 初始化未访问的节点集、已访问的节点列表和连接列表
unvisited = set(remaining_vertices) # 用剩余的顶点列表来初始化未访问的节点集
visited = [] # 已访问的节点列表,最初为空
connections = [] # 连接边的列表,最初为空
# 从未访问的节点集中选取一个节点作为起点
u = unvisited.pop() # 从未访问的节点集中取出一个节点(任意一个)作为起点
visited.append(u) # 将起点加入已访问的节点列表
# 只要未访问的节点集中还有节点,就继续循环
while unvisited:
# 找到满足以下条件的边 e = (u, v):
# 1. u 属于已访问的节点列表
# 2. v 属于未访问的节点集合
# 3. e 的权重(代价)最小
# 假设 edges 是一个包含边信息的列表,其中每条边表示为 (u, v, cost)
# u 是起始节点,v 是终止节点,cost 是边的权重
min_edge = None # 初始化最小边为 None
min_cost = float('inf') # 初始化最小成本为无穷大,以便找到更小的成本
# 遍历所有已访问的节点,寻找连接到未访问节点的最小成本边
for u in visited:
# 从 edges 中筛选出与已访问节点 u 相连的边,且终止节点 v 在未访问节点集合中
for v, cost in [(v, cost) for _, v, cost in edges if _ == u and v in unvisited]:
# 如果找到更小的成本,则更新最小成本和对应的最小边
if cost < min_cost:
min_cost = cost
min_edge = (u, v)
# 如果找到符合条件的边,将其添加到连接边的列表中
if min_edge:
u, v = min_edge # 解包最小边的起点 u 和终点 v
connections.append((u, v)) # 将该边加入连接边的列表
visited.append(v) # 将终点 v 加入已访问的节点列表
unvisited.remove(v) # 从未访问节点集合中移除终点 v# 初始化数据
unvisited = {'B', 'C', 'D'} # 使用集合,便于添加和删除
visited = ['A']
connections = []
# 假设 edges 列表定义了图的边和它们的权重
edges = [
('A', 'B', 1),
('A', 'C', 4),
('A', 'D', 3),
('B', 'C', 2),
('B', 'D', 5),
('C', 'D', 1)
]
# 从当前节点开始
u = visited[0]
# 只要未访问的节点集中还有节点,就继续循环
while unvisited:
# 找到满足条件的最小成本边 e = (u, v)
min_edge = None
min_cost = float('inf')
# 遍历已访问的节点
for u in visited:
# 查找所有从已访问节点 u 出发且终点在未访问集合中的边
for start, end, cost in edges:
if start == u and end in unvisited and cost < min_cost:
min_cost = cost
min_edge = (start, end)
# 如果找到符合条件的边,将其添加到连接列表中
if min_edge:
u, v = min_edge # 获取最小边的起点和终点
connections.append((u, v)) # 将边加入连接列表
visited.append(v) # 将终点 v 加入已访问节点列表
unvisited.remove(v) # 从未访问集合中移除 v
# 输出结果
print("已访问的节点:", visited)
print("构建的最小生成树连接:", connections)公众号:AI悦创【二维码】

C:::
AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Web、Linux」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh
