
05丨Python科学计算:用NumPy快速处理数据
你好,我是悦创。
我来分享一下数据分析中 Numpy 库的使用,本文内容较多,不可能每段代码的输出过程、输出结果分析这显然工作量不是一点点。但我都结合了大量的代码块,希望小伙伴动手运行代码并分析所得到的结果。当你能做到这点的时候,在未来:不管是 Numpy 版本升级导致 API 变化还是其他,你都可以游刃有余的去解决和学习新知识。
而对于结果,分析得不到的结果中规律的小伙伴呢,也不要慌。花了九块钱买的,我的服务也是要有的,如果你对本文中的示例代码的运行结果不理解或者其他问题,都可以在本文下方留言。当然,也可以通过关注公众号:AI悦创,加我好友「不是小号哦」,我拉你进群。有问题可以直接在群里直接提问,也可以并且 @我。我有时间并看到了,是肯定回你哒。「不推荐私聊看,因为你遇到的问题,有可能恰好其他人也遇到过,不要害羞,一起交流学习。这条信息一直有效,欢迎你来撩小编哦!『skr~』
1. 数据分析基础
也就是我们来看看,数据分析当中最底层的东西——数组「Array」,这也是其中最关键的概念,所以接下来我们来看看数组的概念。
1.1 什么是数组?
简单说就是有序的元素序列。比如列表 [1,2,3,4] ,这个是简单的一维数组,只有 4个元素,并且不能被拆分为其他的数组组合;复杂一点呢, [[1,2,3],[4,5,6]] 是一个二维数组,由两个一维数组组成。
有同学说,数组这东西不知道是什么东西,其实很简单:把数字编成组,当然它这一组数字肯定有不同的方式进行排列。我们可以看到下图:1D、2D、3D 是什么意思?其实也就是:一维数组、二维数组、三维数组。
所以,也就是说,我们对数字进行排列的时候我可以以一维的方式进行排列,那一维的长啥样呢?也就是下图的左边第一个图。那二维的呢?有点像个表格,也就是下图的中间「第二个图」。三维的就变成了这样的立方体,也就是下图的最右边的图形。
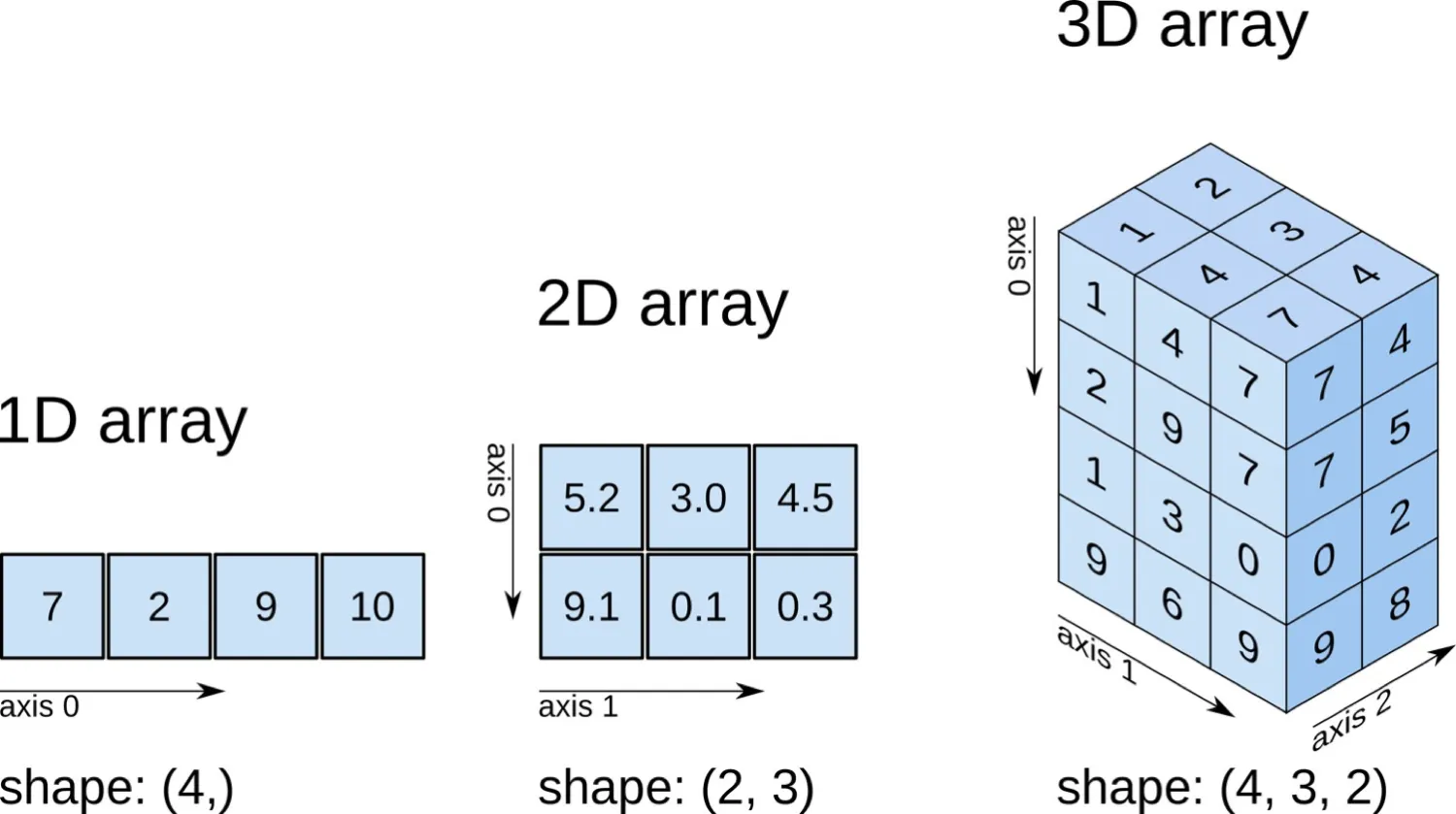
所以,这样大家看上图基本上可以看出来是什么意思:
- 一维的数组它就只有一个方向;
- 二维的数组它就是两个方向;
- 三维的数组自然也就是三个方向「也就是在二维的基础上加了一个方向」;
2. 数据处理的一般流程

接下来,我们来看看我们对于数据分析一般来说会有怎样的流程,一般来说会有如上所示的四步:
- 数据收集 :第一步其实也是很重要的,也就是我们的数据从哪里来。
- 数据预处理 :在正式处理数据之前,我们要做数据预处理。那有同学可能会问:预处理和处理有什么区别?
数据处理这一步呢,是我正式的要对数据进行处理和分析。预处理,它的作用是为了方便我们在第三部数据处理而做的数据预处理。 - 数据展示 :到这里也就是,我数据处理和分析完成了,我如何来把我们分析得出来的结果更加直观。
2.1 数据收集
数据收集有如下几种常用的方法:
- 网络爬虫:可以自己写爬虫代码,自由度较高,麻烦的就是自己得写爬虫;
- 公开数据:比如一些新闻数据、微博评论数据等等一些可以为你提供下载的数据集;
- 购买数据:有专门的爬虫公司,可以为你的需求进行编写特定代码获取数据;
- 公司内部直接提供:比如你是做运营的,利用数据分析给运营看见销售情况等等;
- 其他渠道获取数据:调查问卷等其他形式;
2.2 数据预处理
这里我简单的给大家列一下,不理解也是没有关系的:
- 归一化
- 二值化
- 维度变换
- 去重
- 无效数据过滤
2.2.1 归一化
归一化方法有两种形式,一种是把数变为(0,1)之间的小数,一种是把有量纲表达式变为无量纲表达式。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
把数变为(0,1)之间的小数。
例1:{2.5 3.5 0.5 1.5} 归一化后变成 {0.3125 0.4375 0.0625 0.1875}
解:
这个归一化就是将括号里面的总和变成1,然后写出每个数的比例。
2.2.2 无量纲表达式「选看」
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
在统计学中,归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1--+1之间是统计的坐标分布。
归一化化定义 :归一化就是要把需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。
- 首先归一化是为了后面数据处理的方便,其次是保证程序运行时收敛加快。
- 归一化的具体作用是 归纳统一样本的统计分布性 。
- 归一化在 0-1之间是 统计的概率分布 ,归一化在某个区间上是 统计的坐标分布 。
- 归一化有同一、统一和合一的意思。
如果是区间上的值,则可以用区间上的相对位置来归一化,即选中一个相位参考点,用相对位置和整个区间的比值或是整个区间的给定值作比值,得到一个归一化的数据,比如类似于一个概率值 0<=p<=1;
如果是数值,则可以用很多常见的数学函数进行归一化,使它们之间的可比性更显然,更强,比如对数归一,指数归一,三角or反三角函数归一等,归一的目的:可能是使得没有可比性的数据变得具有可比性 ,但又还会保持相比较的两个数据之间的相对关系,如大小关系,大的仍然大,小的仍然小,或是为了作图,原来很难在一张图上作出来,归一化后就可以很方便的给出图上的相对位置等;
从集合的角度来看,可以做维度的维一,即抽象化归一,把不重要的,不具可比性的集合中的元素的属性去掉,保留人们关心的那些属性,这样,本来不具有可比性的对象或是事物,就可以归一,即归为一类,然后就可以比较了,并且,人们往往喜欢用相对量来比较,比如人和牛,身高体重都没有可比性,但身高/体重的值,就可能有了可比性,人吃多少,牛吃多少,可能也没有直接的可比性,但相对于体重,或是相对于一天的各自的能量提供需要的食量,就有了可比性;这些,从数学角度来看,可以认为是把有纲量变成了无纲量了。
数据标准化方法(Data Normalization Method)
数据处理之标准化/归一化,形式上是变化表达,本质上是为了比较认识 。数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。由于信用指标体系的各个指标度量单位是不同的,为了能够将指标参与评价计算,需要对指标进行规范化处理,通过函数变换将其数值映射到某个数值区间。
2.2.3 二值化


二值化(英语:Binarization)是图像分割的一种最简单的方法。二值化可以把灰度图像转换成二值图像。把大于某个临界灰度值的像素灰度设为灰度极大值,把小于这个值的像素灰度设为灰度极小值,从而实现二值化。
根据阈值选取的不同,二值化的算法分为固定阈值和自适应阈值。 比较常用的二值化方法则有:双峰法、P参数法、迭代法和OTSU法等。
二值化就是
我可能一堆数据,我们拿到手之后直接把它分成两类:低的跟高的,就类似于这样。
2.2.4 二值化辅助理解
1. 图像分割
在计算机视觉领域,图像分割(segmentation)指的是将数字图像细分为多个图像子区域(像素的集合)(也被称作超像素)的过程。图像分割的目的是简化或改变图像的表示形式,使得图像更容易理解和分析。[1]图像分割通常用于定位图像中的物体和边界(线,曲线等)。更精确的,图像分割是对图像中的每个像素加标签的一个过程,这一过程使得具有相同标签的像素具有某种共同视觉特性。
图像分割的结果是图像上子区域的集合(这些子区域的全体覆盖了整个图像),或是从图像中提取的轮廓线的集合(例如边缘检测)。一个子区域中的每个像素在某种特性的度量下或是由计算得出的特性都是相似的,例如颜色、亮度、纹理。邻接区域在某种特性的度量下有很大的不同。[1]
2. 灰度
在计算机领域中,灰度(Gray scale)数字图像是每个像素只有一个采样颜色的图像。这类图像通常显示为从最暗黑色到最亮的白色的灰度,尽管理论上这个采样可以是任何颜色的不同深浅,甚至可以是不同亮度上的不同颜色。灰度图像与黑白图像不同,在计算机图像领域中黑白图像只有黑白两种颜色,灰度图像在黑色与白色之间还有许多级的颜色深度。但是,在数字图像领域之外,“黑白图像”也表示“灰度图像”,例如灰度的照片通常叫做“黑白照片”。在一些关于数字图像的文章中单色图像等同于灰度图像,在另外一些文章中又等同于黑白图像。
灰度图像经常是在单个电磁波频谱如可见光内测量每个像素的亮度得到的。
用于显示的灰度图像通常用每个采样像素8 bits的非线性尺度来保存,这样可以有256种灰度(8bits就是2的8次方=256)。这种精度刚刚能够避免可见的条带失真,并且非常易于编程。在医学图像与遥感图像这些技术应用中经常采用更多的级数以充分利用每个采样10或12 bits的传感器精度,并且避免计算时的近似误差。在这样的应用领域流行使用16 bits即65536个组合(或65536种颜色)。
3. 二值图像
二值图像是每个像素只有两个可能值的数字图像。人们经常用黑白、B&W、单色图像表示二值图像,但是也可以用来表示每个像素只有一个采样值的任何图像,例如灰度图像等。
二值图像经常出现在数字图像处理中作为图像掩码或者在图像分割、二值化和dithering的结果中出现。一些输入输出设备,如激光打印机、传真机、单色计算机显示器等都可以处理二值图像。
二值图像经常使用位图格式存储。
二值图像可以解释为二维整数格 Z2,图像变形处理领域很大程度上就是受到这个观点启发。
2.2.5 维度变换
可以理解为:二维变一维数组这样的变换。
2.2.6 去重
如果重复的数据较多,我们可以在数据预处理的时候处理掉。
2.2.7 无效数据过滤
有可能数据缺漏不全之类的。
举个例子🌰:
假设我们有一个关于用户购买记录的数据集,其中包括以下字段:
- 用户 ID(UserID):标识用户的唯一编号。
- 购买金额(PurchaseAmount):用户一次购买的金额。
- 购买日期(PurchaseDate):购买发生的日期。
| UserID | PurchaseAmount | PurchaseDate |
|---|---|---|
| 101 | 50.0 | 2024-11-01 |
| 102 | 2024-11-02 | |
| 103 | 75.5 | 2024-11-03 |
| 100.0 | 2024-11-04 | |
| 105 | -25.0 | 2024-11-05 |
| 106 | 120.0 |
- 购买金额缺失或无效:
PurchaseAmount应该为正数,缺失或小于等于 0 的数据为无效。 - 用户ID 缺失:
UserID为空的数据为无效。 - 购买日期缺失:
PurchaseDate为空的数据为无效。
import pandas as pd
# 创建数据集
data = {
"UserID": [101, 102, 103, None, 105, 106],
"PurchaseAmount": [50.0, None, 75.5, 100.0, -25.0, 120.0],
"PurchaseDate": ["2024-11-01", "2024-11-02", "2024-11-03", "2024-11-04", "2024-11-05", None],
}
df = pd.DataFrame(data)
# 过滤无效数据
filtered_df = df.dropna(subset=["UserID", "PurchaseDate"]) # 移除 UserID 或 PurchaseDate 缺失的行
filtered_df = filtered_df[filtered_df["PurchaseAmount"] > 0] # 移除购买金额 <= 0 或缺失的行
# 查看过滤后的数据
print(filtered_df)| UserID | PurchaseAmount | PurchaseDate |
|---|---|---|
| 101 | 50.0 | 2024-11-01 |
| 103 | 75.5 | 2024-11-03 |
通过这种方式,我们可以确保后续分析或处理的数据质量较高,减少因无效数据引发的错误。
2.3 数据处理
- 数据排序:类似从大到小排序;
- 数据查找:按某种条件进行查找;
- 数据统计分析
这里其实有很多,我只是列了几个而已。
- 列表
- 图表
- 动态交互图形;
以上就是数据处理的基本流程。
3. 为什么使用 Numpy
- 高性能
- 开源
- 数组运算
- 读写迅速
简单来讲,Python 内置的若干种数据类型,无法高效地应对计算密集型场景,比如矩阵运算。因此 Numpy 随之应运而生,并被认为是高性能科学计算和数据分析的基础包。
数据分析中所介绍到几乎所有的高级工具,都是基于 Numpy 开发的。因为 NumPy 的大部分代码都是用 C 语言写的,其底层算法在设计时就有着极优异的性能,所以使得 NumPy 比纯 Python 代码高效得多。作为基础工具,其实玩转 Numpy 很简单,只要掌握三个关键知识点,即:数据类型的创建、数据层的索引切片、数组运算。下面我们分不同的篇幅一一展开。
对于新入门的同学,尤其需要注意的是,虽然大多数的数据分析工作并不会直接操作 Numpy 对象,但是深谙面向数组的编程方式和逻辑能力是成为 Python 数据分析大牛的关键,切记磨刀不误砍柴工。
面向数组的编程方式,最大的特点就是用数组表达式完成数据操作任务,无需写大量循环。向量化的数组操作会比纯 Python 的等价实现快一到两个数量级。在后续的学习中,我们会有机会细细品味其中的差别和优势。
import numpy as np
import time
list_array = list(range(int(1e6))) # 10 的 6次方
start_time = time.time()
python_array = [val * 5 for val in list_array] # 一百万个数字,里面每个数字都乘于 5
end_time = time.time()
print('Python array time: {}ms'.format(round((end_time - start_time) * 1000, 2)))
np_array = np.arange(1e6)
start_time = time.time()
np_array = np_array * 5
end_time = time.time()
print('Numpy array time: {}ms'.format(round((end_time - start_time) * 1000, 2)))
print('What sup!')Python array time: 30.36ms
Numpy array time: 1.24ms
What sup!4. 安装 Numpy
pip install numpypip3 install numpyconda install numpy5. 新建一个 Python 文件
导入 Numpy 模块
import numpy as npas np表示在接下来的程序里 用 np 表示 numpyimport 某某模块 as 一个缩写
6. Numpy 的基础类型——ndarray
Numpy 最重要的一个特点就是它可以快速地创建一个 N 维数组对象(即 ndarray ,本文在 ndarray 对象和 数组 并不做概念上的区分),然后你可以利用 ndarray 这种数据结构非常高效地执行一些数学运算,并且语法风格和 Python 基本一致。
6.1 创建数组
6.1.1 一维数组
创建一个 ndarray 数组,我们在 Python 里面直接创建数组原本是这样创建的:
data = [2, 4, 6.5, 8]创建 ndarray 最简单的方法就是使用 array 函数,它接受一个序列型对象(比如列表),并转化为 ndarray 对象。所以,如果要创建一个 Numpy 类型的 一维数组 ,就需要如下编写代码:
data = np.array([2, 4, 6.5, 8]) # np.array() 里面直接填一个由数字组成的列表当然,你有可能想把列表单独的来写,那就可以像下面这么来写:
In [14]: python_list = [2, 4, 6.5, 8]
...: data = np.array(python_list)
In [15]: data
Out[15]: array([2. , 4. , 6.5, 8. ])这里细心的朋友会发现一个有趣的现象,我们传入的列表中,存在 float 和 int 两种数据类型,但是在创建的 ndarray 对象中,默认转化为了 float 结构,这是因为 ndarray 是一个通用的同构数据多维容器,也就是说,其中的所有的元素必须是相同的类型, Numpy 会根据输入的实际情况进行转换。「也就是如果创建的时候,没有指定数据类型,那 Numpy 就会以数组中最小的数据类型为数据。」
6.1.2 二维数组
上面我们创建了一个一维数组,接下来我们来创建一个 二维数组,有行有列的,我们是如下去创建的:
import numpy as np
data = np.array([[1, 2, 3], [4, 5, 6]]) # 也可以这么写:data = np.array([(1, 2), (3, 4)])当然,我们的格式还可以这么写:「更加清晰一些」
import numpy as np
data = np.array(
[
[1, 2, 3],
[4, 5, 6]
]
)提示
嵌套列表或者嵌套元祖都是可以的,输出结果可以自行尝试。
这里我再次创建一个二维数组,并为同学们添加上了一张图片,方便同学们理解。
#创建二维数组
arr2d=np.arange(9, dtype=np.float32).reshape(3,3)显然,二维数组有两个维度的索引,映射到平面空间的话,二维数组的两个轴分别为 axis 0 和 axis 1,Numpy 默认先对 axis 0 轴索引,再对 axis 1轴索引。(数组其实可以视作嵌套列表,通常把最外层的索引定义为 axis 0,依次往里递增,该规律对于高维数组也适用)
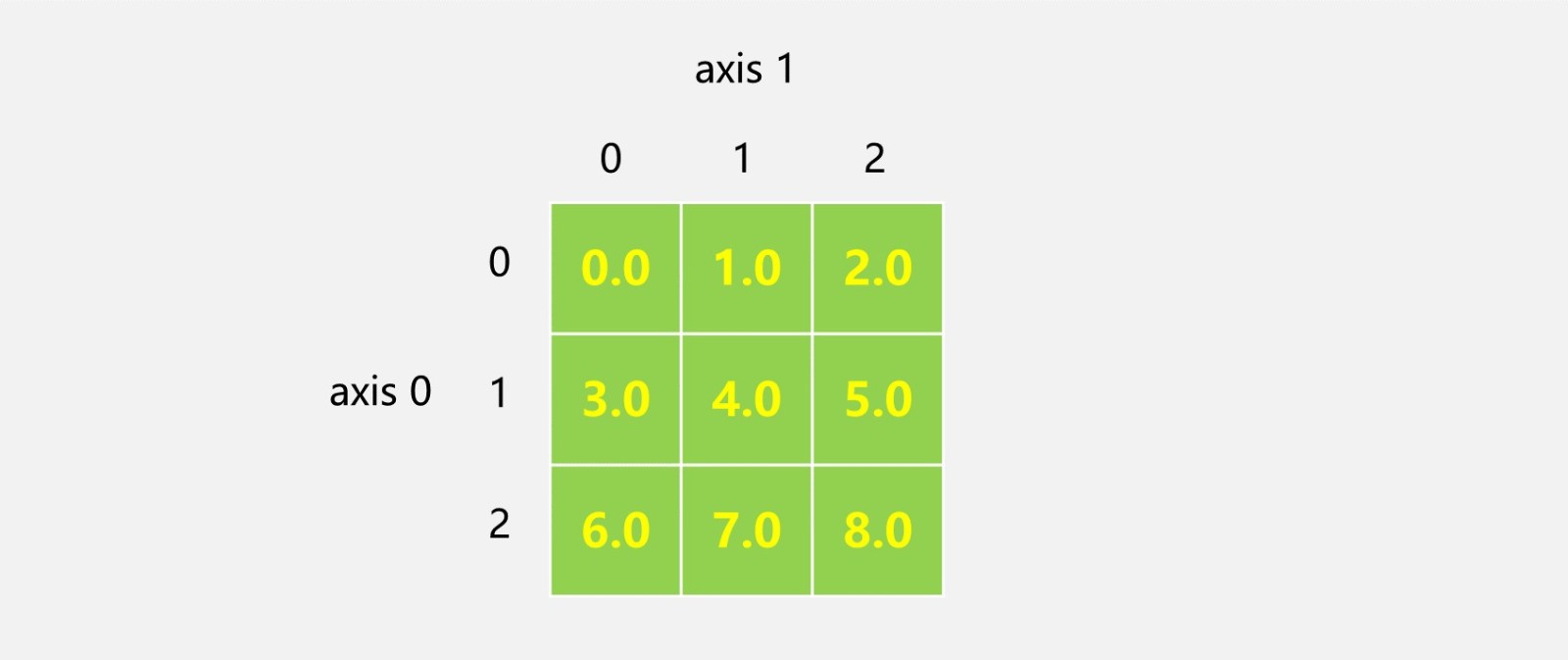
细心的同学会发现上面,我使用了 dtype 那我来补充一下:
#判断数组的数据类型
data = np.array([1, 2, 3, 4, 5])
np.issubdtype(data.dtype, np.integer)
Out: True
##数组类型也可以用字符代码来指代,主要是为了保持与诸如 Numeric 之类的旧程序包的向后兼容性。一些文档可能仍引用这些文档,例如:
data = np.array([1, 2, 3], dtype='f') # 等价于:array([ 1., 2., 3.], dtype=float32) 我们建议改为使用 dtype 对象。
data
Out: array([1., 2., 3.], dtype=float32)
data.dtype
Out[13]: dtype('float32')6.1.3 三维数组
三维数组比二维数组多了一维。三维数组在图片领域比较常见,对于 RGB 三原色模式的图片,就是用 大小的数组来表示一张图片,其中 m 表示图片垂直尺寸, n 表示图片水平尺寸,3 表示三原色。那在 Python 中我们如何创建三维数组呢?
import numpy as np
data = np.array(
[
[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]
]
)
print(data.ndim)6.1.4 高维数组
通常在我们的数据分析领域,甚至在 AI 大数据领域,原始的输入层都是二维的,即每个样本是一维的(由 n 个指标去定义一个样本),样本集则是二维的;在图片识别领域,通常用到的原始输入层都是三维的,因为图片一般都是三维的数组。所以朋友们熟悉二维和三维的常用索引、切片就足够应付绝大部分实际场景了。高维数组不建议大家深入挖掘。
import numpy as np
data = np.array(
[
[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
[[[13, 14, 15], [16, 17, 18]], [[19, 20, 21], [22, 23, 24]]]
]
)
print(data.ndim)import numpy as np
data = np.array(
[
[[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]], [[[13, 14, 15], [16, 17, 18]], [[19, 20, 21], [22, 23, 24]]]],
[[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]], [[[13, 14, 15], [16, 17, 18]], [[19, 20, 21], [22, 23, 24]]]]
]
)
print(data.ndim)import numpy as np
data = np.array(
[
[[[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]], [[[13, 14, 15], [16, 17, 18]], [[19, 20, 21], [22, 23, 24]]]],[[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]], [[[13, 14, 15], [16, 17, 18]], [[19, 20, 21], [22, 23, 24]]]]],
[[[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]], [[[13, 14, 15], [16, 17, 18]], [[19, 20, 21], [22, 23, 24]]]],[[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]], [[[13, 14, 15], [16, 17, 18]], [[19, 20, 21], [22, 23, 24]]]]],
]
)
print(data.ndim)其他维度的数组可以自行尝试,没写出来不代表没有!自己试一试才知道!
6.2 arange 创建等差数组
如果让大家创建一个等差列表,从1到100,一共 100 项,那一定非常方便,用 range(1, 101, 1) 快速搞定。Numpy 也提供了类似的方法 arange() ,用法与 range() 非常相似。
In [1]: import numpy as np
...: # 指定 start、stop、以及step。arange和range一样,是左闭右开的区间。
...: arr_uniform0 = np.arange(1,10,1)
...: # 也可以只传入一个参数,这种情况下默认start=0,step=1
...: arr_uniform1 = np.arange(10)
In [2]: arr_uniform0
Out[2]: array([1, 2, 3, 4, 5, 6, 7, 8, 9])
In [3]: arr_uniform1
Out[3]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])6.3 ndmin 指定创建的数组类型
'''
Minimum dimensions 2:
最小尺寸2:
Notes:ndmin: 指定维度类型,类似强制转换
'''
# 示例一:
import numpy as np
data = np.array([1, 2, 3], ndmin=2)
print(data)
print(data.ndim)
# 输出结果:
[[1 2 3]]
2
# 示例二:
import numpy as np
data = np.array([1, 2, 3], ndmin=3)
print(data)
print(data.ndim)
# 输出结果:
[[[1 2 3]]]
36.4 判断 ndarray 维度「判断数组维度」——ndim
ndim = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
"""Number of array dimensions.
数组维数。
Examples
--------
>>> x = np.array([1, 2, 3])
>>> x.ndim
1
>>> y = np.zeros((2, 3, 4))
# np.zeros((组,行,列)) 三维
# np.zeros((行,列)) 二维
>>> y.ndim
3
"""其实,上面的代码已经用到了 ndim ,这个可以帮助我们查看数组维度,有时候肉眼也不一定看的清楚,其次就是你的数组来源有可能是其他方式的来源,用 ndim 就会更加的智能化。
import numpy as np
data = np.array(
[
[1, 2, 3],
[4, 5, 6]
]
)
print(data.ndim)6.5 了解 ndarray 各维度的长度
我不仅要知道这个数组有多少维度,我们还想知道该数组在每个维度上面的长度是多少。 比如:我们有个二维数组,我们想要知道,这个二维数组是几行几列。「每个维度的长度」
import numpy as np
data = np.array(
[
[1, 2, 3],
[4, 5, 6]
]
)
print(data.shape)(2, 3) # 两行三列当然,我们不仅仅可以使用 shape 查看数组各维度的长度,还可以使用它变换数组的维度:
import numpy as np
data = np.array(
[
[1, 2, 3],
[4, 5, 6]
]
)
print(f"原本数组的维度:{data.ndim}")
data.shape = (6,)
print(data)
print(f"变换之后,数组的维度:{data.ndim}")6.5.1 详解
代码片段:
data = np.array(
[
[1, 2, 3],
[4, 5, 6]
]
)这里创建了一个 NumPy 数组,输入数据是一个二维列表。np.array() 将其转化为一个二维数组。
初始数组:
[[1 2 3]
[4 5 6]]属性:
- 形状 (
shape):(2, 3),表示数组有 2 行,每行有 3 列。 - 维度 (
ndim):2,表示这是一个二维数组。 - 元素总数 (
size):6,即数组中包含 6 个元素(2×3)。
输出:
原本数组的维度:2代码片段:
data.shape = (6,)关键点:
shape属性: 用于直接修改数组的形状(行列结构)。- 新形状
(6,): 表示将数组变为一维数组,包含 6 个元素。- 形状中的每一维的值必须能与数组的总元素数兼容。例如,总元素数是 6,
shape可以是(6,)、(2, 3)或(3, 2),但不能是(4, 2)或其他不匹配的形状。
- 形状中的每一维的值必须能与数组的总元素数兼容。例如,总元素数是 6,
修改后的数组:
[1 2 3 4 5 6]- 数组被 "拉平",变成了一维数组。
- 形状 (
shape):(6,),表示一维数组,包含 6 个元素。 - 维度 (
ndim):1,数组的维度变为 1。
代码片段:
print(data)
print(f"变换之后,数组的维度:{data.ndim}")输出:
[1 2 3 4 5 6]
变换之后,数组的维度:1shape属性:是一个元组,表示数组每一维的大小。
可以通过直接修改
shape来调整数组的形状,只要新形状的总元素数与原数组的总元素数一致。
维度 (
ndim) 的变化:维度与
shape的长度直接相关。原数组的
shape = (2, 3),是二维数组,ndim=2。修改后
shape = (6,),是一个一维数组,ndim=1。
数据存储不变:
- 修改
shape不会改变数组的数据内容,仅改变数据的组织方式。
- 修改
总元素数必须一致:
shape修改前后的元素总数必须相同,否则会抛出错误。data.shape = (4,) # ValueError: cannot reshape array of size 6 into shape (4,)
reshape虽然直接修改 shape 是一种方法,但更推荐使用 reshape() 方法,这样不会直接改变原数组,而是返回一个新的数组。
data_reshaped = data.reshape((6,))
print(data_reshaped)
print(data.shape) # 原数组的形状未改变在 NumPy 中,shape 是多维数组(ndarray)的一个属性,用于表示数组的维度大小。
shape 的返回值是一个元组,每个元素表示数组每一维的大小(即包含的元素个数)。
1. shape 的结构
- 如果数组是一维的,比如
[1, 2, 3],shape只有一个值,表示该维度的长度,例如(3,)。 - 如果数组是二维的,比如
[[1, 2, 3], [4, 5, 6]],shape是一个两元素的元组,第一个值表示行数,第二个值表示列数,例如(2, 3)。 - 如果数组是三维的,比如
[[[1, 2], [3, 4]], [[5, 6], [7, 8]]],shape是一个三元素的元组,依次表示深度、行数、列数,例如(2, 2, 2)。
2. 示例
一维数组:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(arr.shape) # 输出: (5,)二维数组:
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr.shape) # 输出: (2, 3)三维数组:
arr = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
print(arr.shape) # 输出: (2, 2, 2)3. 形状的意义
- 每个元素在数组中的位置,可以用一个元组来唯一标识,元组的长度与数组的
shape长度一致。 - 例如,
shape = (3, 4)表示有 3 行 4 列,可以通过(row, col)索引来访问元素。
示例:
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
print(arr.shape) # 输出: (3, 4)
# 访问元素
print(arr[1, 2]) # 输出: 7 (第2行,第3列)4. 改变形状
通过 reshape 方法,可以将数组转换成不同的形状,但总元素个数不能变。
示例:
arr = np.array([1, 2, 3, 4, 5, 6])
# 转换成 2行3列
arr_reshaped = arr.reshape(2, 3)
print(arr_reshaped)
# 输出:
# [[1 2 3]
# [4 5 6]]
# 转换成 3行2列
arr_reshaped = arr.reshape(3, 2)
print(arr_reshaped)
# 输出:
# [[1 2]
# [3 4]
# [5 6]]5. 特殊形状
- 一维数组:
shape = (n,),表示只有一个维度。 - 二维行向量:
shape = (1, n),表示有 1 行,n 列。 - 二维列向量:
shape = (n, 1),表示有 n 行,1 列。 - 高维数组:如
(d1, d2, d3)表示第1维长度为d1,第2维长度为d2,第3维长度为d3。
6. 动态获取和设置 shape
获取数组形状:
arr = np.array([[1, 2], [3, 4], [5, 6]])
print(arr.shape) # 输出: (3, 2)修改数组形状:
arr.shape = (2, 3) # 直接修改
print(arr)
# 输出:
# [[1 2 3]
# [4 5 6]]7. 常见错误
元素总数不匹配:
arr = np.array([1, 2, 3, 4, 5, 6]) arr.reshape(3, 3) # 会报错,因为元素总数不为 9忽略多维特性:
(3,)和(3, 1)的行为不同,前者是一维数组,后者是二维数组。
8. 总结
shape是 NumPy 中描述数组维度的核心属性。- 可以通过
shape理解数据的结构和大小。 - 使用
reshape可以方便地转换数组形状。
6.5.2 更多代码例子
import numpy as np
data = np.array([[1, 2, 3], [4, 5, 6]])
print("原数组:\n", data)
print("原 shape:", data.shape)
# 改变 shape 为一维
data.shape = (6,)
print("改变后的数组:\n", data)
print("改变后的 shape:", data.shape)
# ---output---
原数组:
[[1 2 3]
[4 5 6]]
原 shape: (2, 3)
改变后的数组:
[1 2 3 4 5 6]
改变后的 shape: (6,)data = np.array([1, 2, 3, 4, 5, 6])
print("原数组:\n", data)
print("原 shape:", data.shape)
# 改变 shape 为二维
data.shape = (3, 2)
print("改变后的数组:\n", data)
print("改变后的 shape:", data.shape)
# ---output---
原数组:
[1 2 3 4 5 6]
原 shape: (6,)
改变后的数组:
[[1 2]
[3 4]
[5 6]]
改变后的 shape: (3, 2)data = np.array([1, 2, 3, 4, 5, 6])
print("原数组:\n", data)
print("原 shape:", data.shape)
# 改变 shape 为三维
data.shape = (2, 1, 3)
print("改变后的数组:\n", data)
print("改变后的 shape:", data.shape)
# ---output---
原数组:
[1 2 3 4 5 6]
原 shape: (6,)
改变后的数组:
[[[1 2 3]]
[[4 5 6]]]
改变后的 shape: (2, 1, 3)data = np.array([1, 2, 3, 4, 5, 6, 7, 8])
print("原数组:\n", data)
print("原 shape:", data.shape)
# 改变 shape 为 (2, 4)
data.shape = (2, 4)
print("改变后的数组:\n", data)
# 再改为 (4, 2)
data.shape = (4, 2)
print("再次改变后的数组:\n", data)
# ---output---
原数组:
[1 2 3 4 5 6 7 8]
原 shape: (8,)
改变后的数组:
[[1 2 3 4]
[5 6 7 8]]
再次改变后的数组:
[[1 2]
[3 4]
[5 6]
[7 8]]reshape 方法 (推荐)# 直接修改 shape 是一种方法,但更推荐使用 reshape(),因为它不会改变原数组,而是返回一个新数组。
data = np.array([1, 2, 3, 4, 5, 6])
# 改变 shape 为二维
data_reshaped = data.reshape((2, 3))
print("原数组:\n", data)
print("新数组:\n", data_reshaped)
# 再改为三维
data_reshaped = data.reshape((3, 1, 2))
print("三维数组:\n", data_reshaped)
# ---output---
原数组:
[1 2 3 4 5 6]
新数组:
[[1 2 3]
[4 5 6]]
三维数组:
[[[1 2]]
[[3 4]]
[[5 6]]]data = np.array(range(24)) # 24 个元素
print("原数组 shape:", data.shape)
# 转换为 2x3x4 的三维数组
data.shape = (2, 3, 4)
print("三维数组:\n", data)
# 转换为 4x6 的二维数组
data.shape = (4, 6)
print("二维数组:\n", data)
# ---output---
原数组 shape: (24,)
三维数组:
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
二维数组:
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]# 如果新 shape 与数组总元素数不匹配,会抛出 ValueError。
data = np.array([1, 2, 3, 4, 5, 6])
# 尝试设置不兼容的 shape
try:
data.shape = (2, 4)
except ValueError as e:
print("错误:", e)
# ---output---
错误: cannot reshape array of size 6 into shape (2,4)总结:
shape的改变可以调整数组的行列结构,但总元素数必须保持一致。推荐使用
reshape(),因为它不会直接修改原数组,避免了潜在的问题。通过这些示例,可以灵活掌握数组的形状转换,适用于各种场景!
6.6 创建全是 0 的数组
比如,我想初始化一个全是 0 的数组,先暂时的创建全是 0 的数组。
详情
提示
我们想要处理的数据,需要存放在列表的特定位置,例如:酒店每个房间的每个时间点预约情况。
小悦要预约某个房间的 14:00 这个时间,我们如何实现呢:
room_reservation = []
room_reservation.append("📅14:00 小悦预约")从上面可知,我们不能直接使用 .append(),因为 append 只会添加在列表的末尾,不够直观且多个顾客会导致混乱🤪:
room_reservation = []
room_reservation.append("📅14:00 小悦预约")
room_reservation.append("📅19:00 小曲预约")
room_reservation.append("📅09:00 小檀预约")
room_reservation.append("📅07:00 小美预约")
# ---output---
['📅14:00 小悦预约', '📅19:00 小曲预约', '📅09:00 小檀预约', '📅07:00 小美预约']从上面的结果可知,混乱并且不利于管理!
而如果要按放在指定位置,我们就需要提前创建列表并且列表里面提前存储相关数据或无影响数据。
不提前创建情况:
room_reservation = [] room_reservation[3] = "📅14:00 小悦预约" # ---output--- --------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-15-e3106f9fd4f3> in <cell line: 3>() 1 room_reservation = [] 2 ----> 3 room_reservation[3] = "📅14:00 小悦预约" IndexError: list assignment index out of range提前创建则可以指定下标修改
创建时间表
room_reservation = [] for time in range(25): room_reservation.append(f"{time:02}:00") # 格式化字符串,02表示补足两位 room_reservationf"{time:02}":02表示将数字格式化为两位数,前面不足时用0补足。
如果只为某些指定的时间(比如 0~9)在前面补
0,可以结合条件语句来实现。例如:room_reservation = [] for time in range(25): if 0 <= time <= 9: room_reservation.append(f"0{time}:00") # 为 0~9 前面加上 0 else: room_reservation.append(f"{time}:00") # 其他时间正常格式 room_reservation解释:
if 0 <= time <= 9:检查是否在指定范围内(0~9)。f"0{time}:00":为指定范围的时间前补0。
room_reservation = ["00:00", "01:00", "02:00", "03:00", "04:00", "05:00"]酒店房间预约是要存放在具体的时间点的位置,例如:小悦要预约该房间的
14:00这个时间,那就是如下代码:room_reservation[12] = "📅14:00 小悦预约"这样不管是谁预约,我们我可以很有调理的查看和管理预约数据。
format 杂谈
format方法中默认用0补位。如果你需要用其他字符补位,可以结合字符串的方法进行自定义处理。例如:
欢迎关注我公众号:AI悦创,有更多更好玩的等你发现!
公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh
