

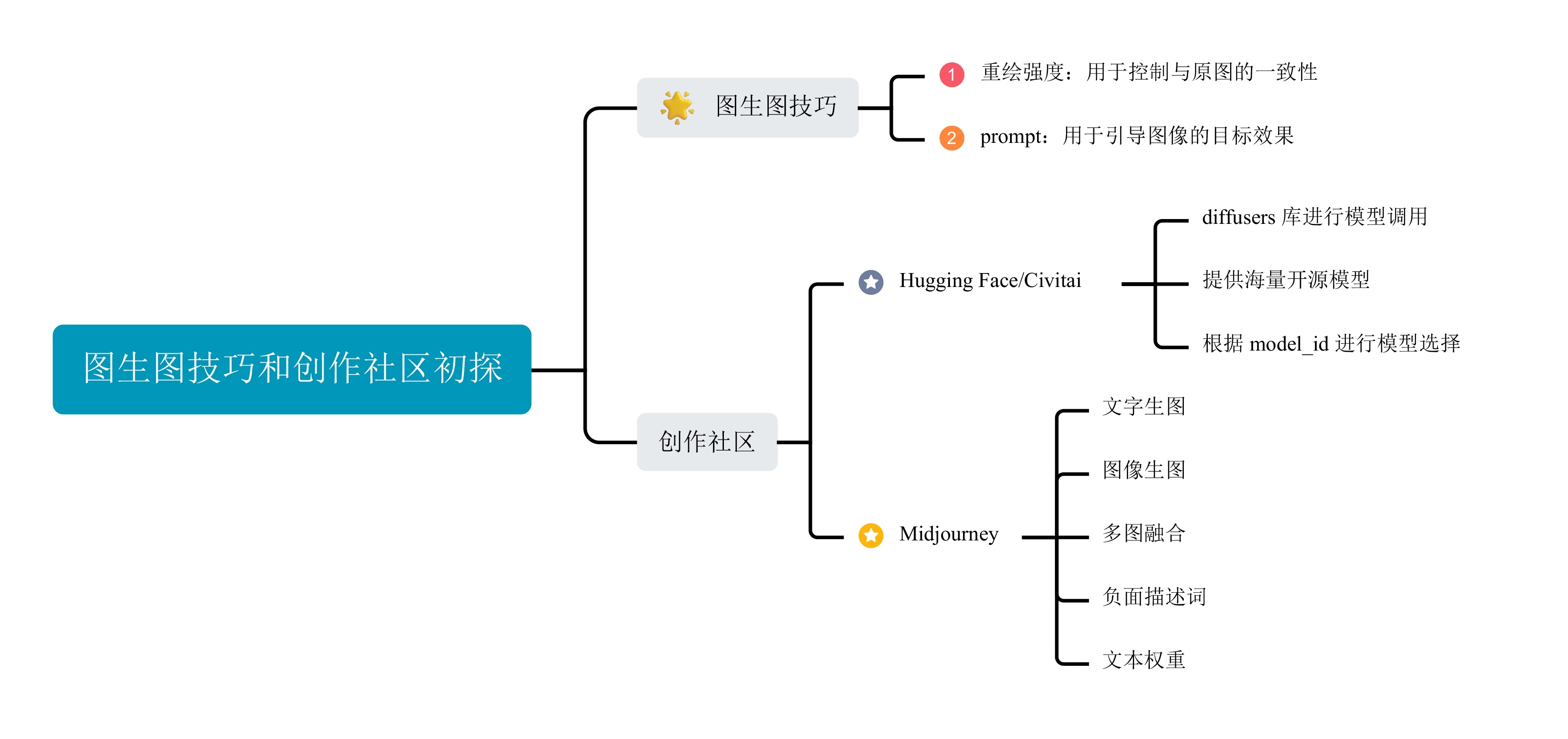
03-进阶应用:图生图技巧与创作社区初探


你好,我是悦创。
上一讲我们学习了很多文生图的 AI 绘画技巧。如果说文本生图是一种无中生有的绘画形式,那么图像生图无疑是锦上添花的绘画技巧。
今天这一讲,我会带你探索图生图的功能,了解图生图能力能够帮我们完成哪些任务,并通过控制重绘强度影响图生图的绘画效果。另外,我还会带你了解 Civitai 和 Hugging Face 这两个开源社区,用不同风格的模型帮我们进行 AI 绘画。学完这一讲,你就可以使用开源社区丰富的模型宝库,对自己手中的照片进行魔改了!
1. 图生图可以做哪些事情?
图生图,顾名思义,算法的输入是一张图片,输出也是一张图片。AI 绘画给出的图片需要和用户输入的图片之间存在某种关联。这种关联包括后面这些情况。
- 输入一张真实拍摄的照片,保持图像构图输出一张风格化的绘画结果。
- 输入一张低分辨率的照片,输出一张高分辨率的清晰照片。
- 输入一件衣服,输出一个模特穿着这件衣服。
- 输入一张局部涂抹的照片,输出一张 AI 算法补全后的照片。
- 输入一张图片,输出这种图片向外延展之后的效果等等。


你可以翻看前面的先导篇,了解更多文生图的效果。那么,如何通过 WebUI 实现这些神奇的图生图能力呢?
2. 通过重绘强度控制图生图效果
我们选择 img2img 这个标签,prompt 和 negative prompt 的操作与之前相同(详见第二讲),在下方 drop image here 区域内,可以点击选择需要修改的图像,或者拖拽一张新图像进来。
与文生成图不同,图生成图需要输入 prompt 和原始图像。首先,原始图像会经过加噪处理,转变为 Stable Diffusion 模型可以处理的“噪声图像”。然后,再根据 prompt 的引导生成图像。
因此,只要我们仔细控制参数,生成的图像就能同时包含原始图像的特征和 prompt 语句相关的内容。这种机制的本质其实就是用 prompt 引导原始图像产生新的图像。
光说理论太过抽象,我们结合一个具体例子来看看。我们输入一张小女孩的照片,然后在 prompt 写上“一张女孩的照片,迪士尼风格,卡通”,输出效果就是后面图里这样。

通过观察你可以发现,这种方式生成的图像与原图相似,但风格变成了迪斯尼风格。同时,一个新变量——即 Denoising strength(重绘强度)出现了。
重绘强度仅在图生成图(img2img)或高清修复过程中被应用,这个变量表示图像加噪的程度。它代表了生成的图像相对于原始输入图像内容的变化程度,数值越高,AI 对原图的参考程度就越低,生成的图像和原图的区别就越大。
我们以之前的生成图像为例,对应 prompt 语句为 “a dog, cartoon style”,其它参数不变。
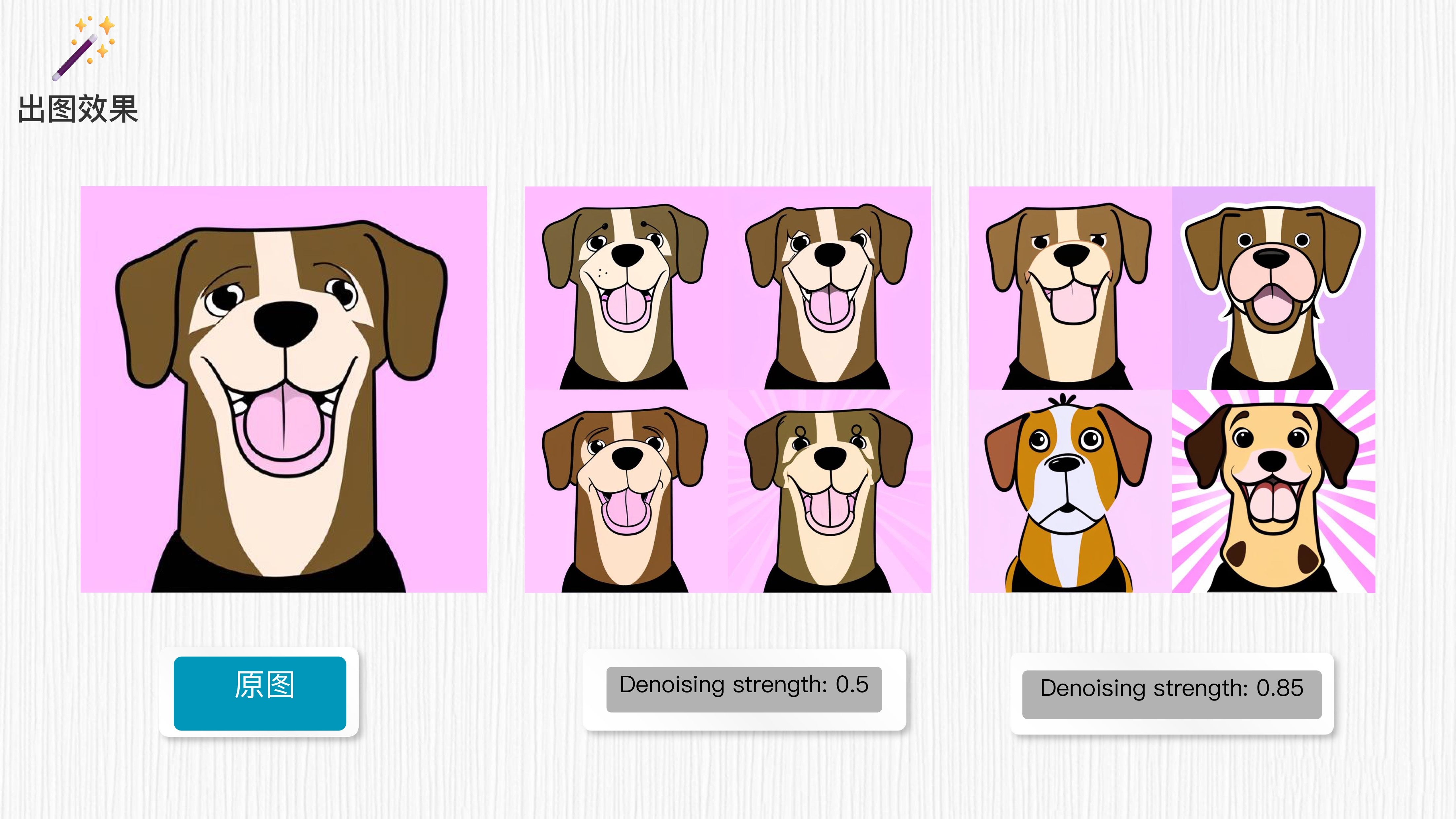
我们可以观察到,生成的图像在一定程度上保留了原始图像的特征。当重绘强度的值较高时,生成的图像变化较大,但整体轮廓仍然与原始图像相似。
那如果我们希望在图生图的过程中,对内容做出更大的调整,又该怎么做呢?针对上面这个例子,我们不妨修改 prompt 语句为:“a cat, cartoon style”。生成结果是后面这样。
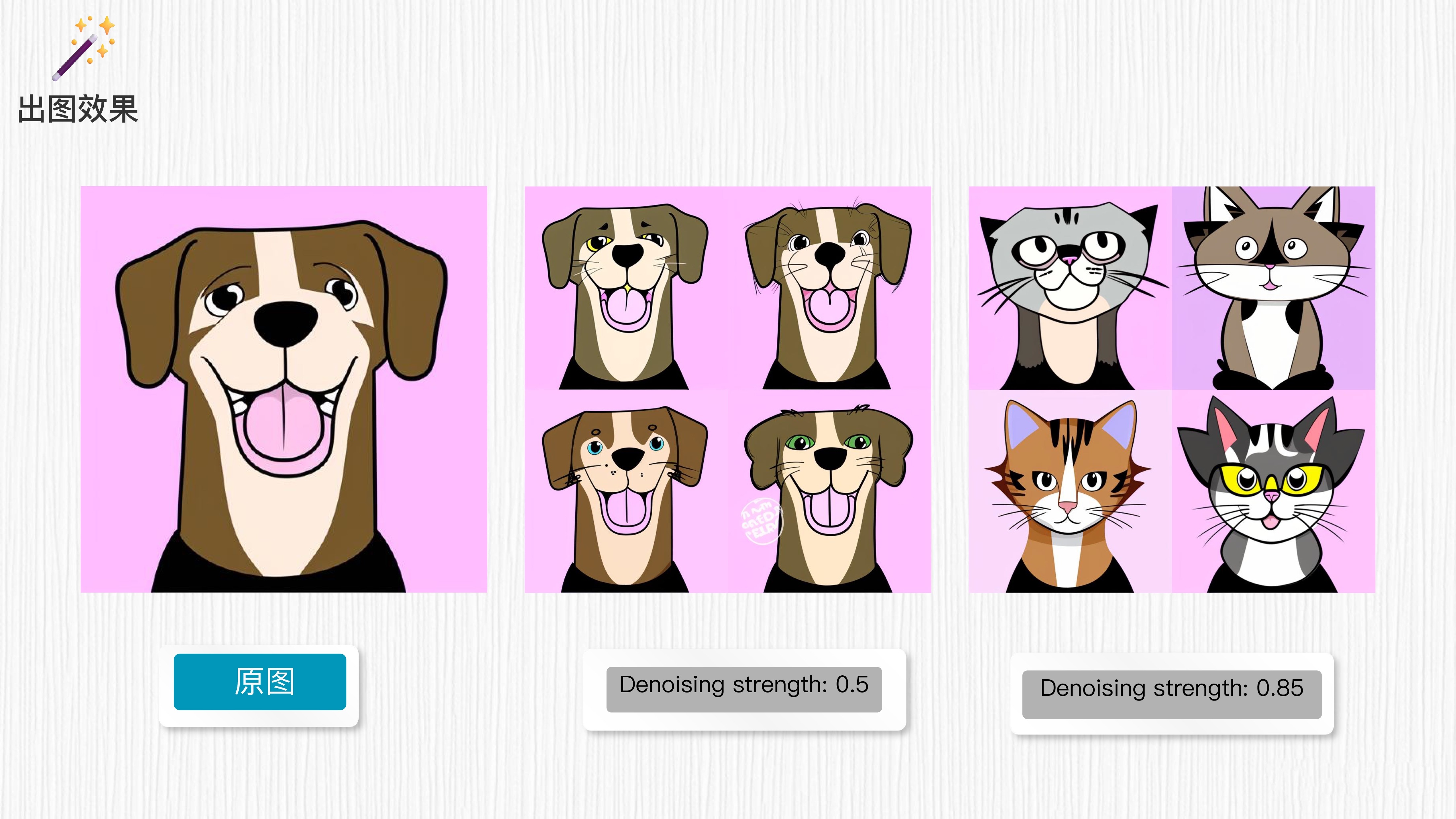
你有没有感觉非常有趣?当重绘强度为 0.5 时,生成的图像没有明显的变化,并且与新修改的“cat”没有太多相关性。然而,当重绘强度为 0.85 时,图像基本上都转变成了猫的图像,靠近了 prompt 语句,并且保留了原始图像的结构。
这个观察结果表明,重绘强度参数对图像生成的影响非常显著。较高的重绘强度可以帮助模型更好地理解并生成与 prompt 相关的内容,同时保留原始图像的整体结构。 这进一步证明了参数对图生图的关键作用。
我们回到最初的任务,尝试使用不同的重绘强度和 prompt 变化,将一位可爱的姑娘转变为卡通或迪士尼风格。

看到了么?目标达成!只要灵活应用 prompt 和重绘强度,我们就能随心所欲地进行图像生图。你可以课后自己亲自动手练习一下,这样体会更深。
我再给你稍微总结一下重点。重绘强度在图生成图过程中起到重要的作用,它表示生成图像相对于原始输入图像内容的变化程度。较高的重绘强度会导致生成的图像更大程度地与 prompt 相关,同时有些偏离原始图像的特征。效果就是生成的图像更加创新、有趣,但与原始图像之间的相似性较低。
相反,较低的重绘强度会更倾向保留原始图像的整体特征和结构,让生成的图像更接近原始图像,但可能在与 prompt 相关性方面稍显不足,说白了就是只能针对原始图像做小修小补。
因此,适当调整重绘强度可以控制生成图像的变化程度和与原始图像的相似性。我们根据具体需求,可以选择合适的重绘强度,来达到所期望的图像生成效果。比如,采样步数为 30,重绘强度取 0.6 便是不错的选择。更多的参数组合,你可以课后做更多探索。
3. 开源社区的魅力:Civitai 和 Hugging Face
掌握了 WebUI 这个有用的工具,如何获取到各种风格的 AI 绘画模型就非常关键了。事实上,除了我们经常听到的 Stable Diffusion 1.4、1.5、2.0 这样的模型,我们在开源社区中还能找到成千上万的有趣模型,为我们所用。
Civitai 和 Hugging Face 是 AI 绘画领域两个非常重要的开源社区。它们吸引了来自全球各地的网友们参与其中。这些社区成为了一个宝藏般的资源库,提供了大量且多样的风格模型。通过这些社区,人们可以相互交流、分享和发现新的 AI 绘画技巧,不断推动 AI 绘画领域的发展。

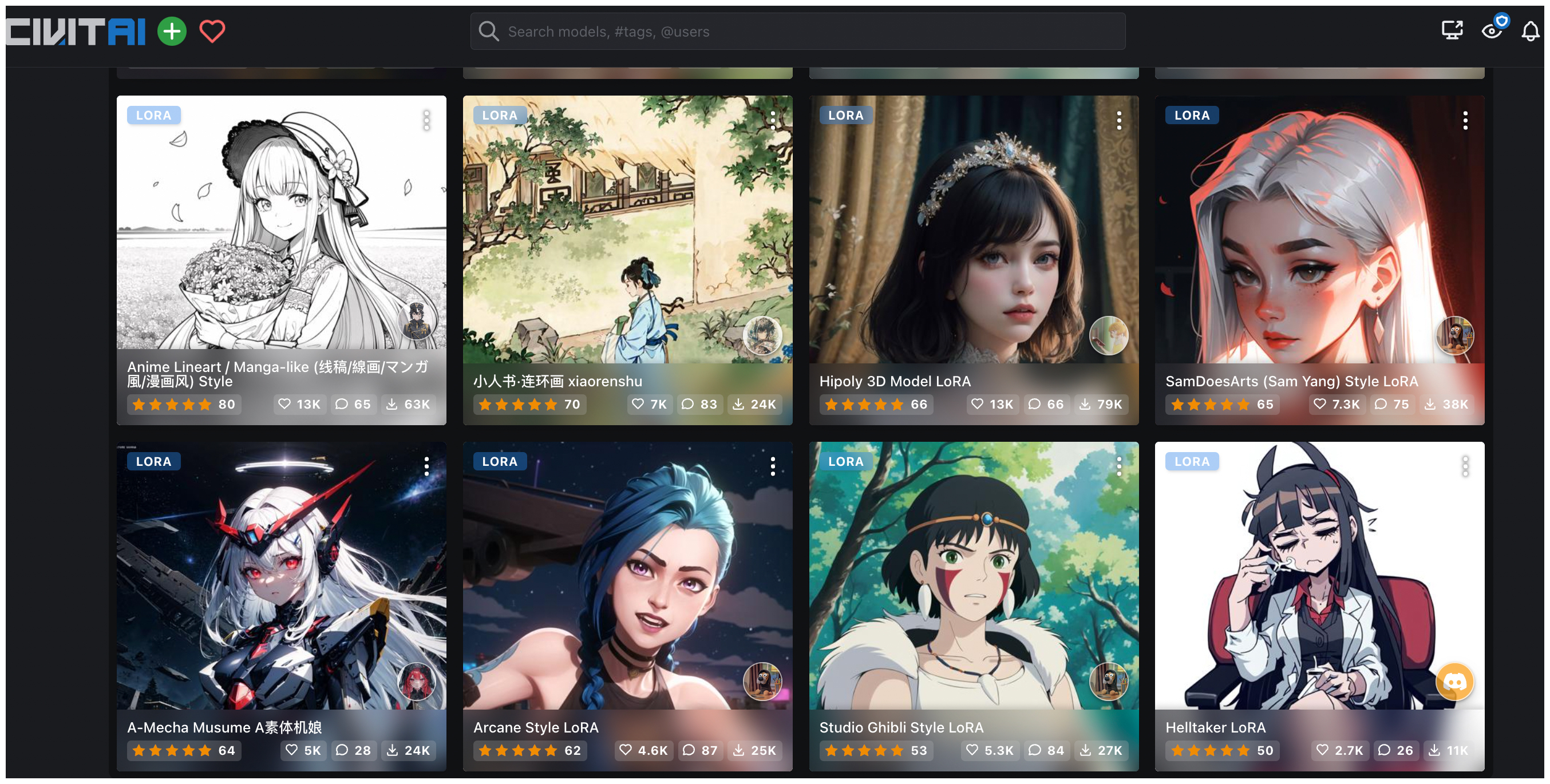
在使用上,这两个社区却有点区别。对于 Hugging Face,你需要先注册官方账号并安装 diffusers 库,这样你就可以使用社区中提供的各种模型。以 SD1.5 模型为例,你调用相关的 API 即可用它完成图像生成任务,脚本如下。
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")大多数情况下,模型的更换就是更换 “model_id”。但如果我们希望有良好的界面管理,而且希望联合使用多种能力的话,WebUI 配合 Civitai 或许是你最佳的选择。通过界面上的选项,就能选择不同的模型和参数设置,实现定制化的 AI 绘图。
在使用 Civitai 网站时,很重要的一步是找到并且选择适合自己的模型。你需要仔细查看模型的类型和使用方式,以确保正确地安装和配置模型,这样 WebUI 才能顺利调用它。
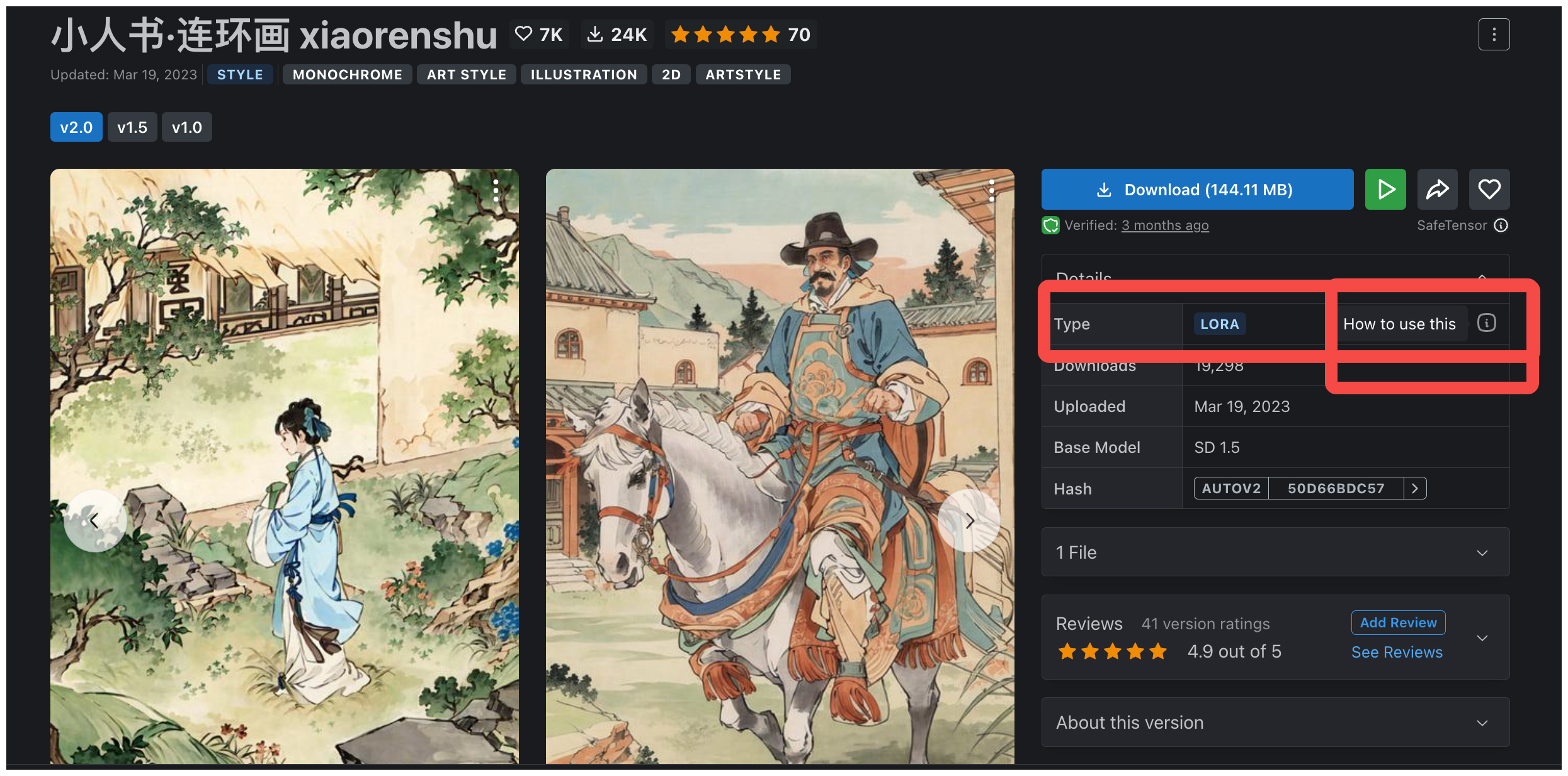
尝试不同的风格化模型,可以让我们探索多样的创作风格和特征。每个模型都有其独特的艺术表达方式,选到合适的模型有助于我们精准去控制图像风格。最后,在大量风格化模型,巧妙设计 prompt 以及合理调整参数的配合下,相信你的 AI 绘画能力将会得到显著提升。

4. Midjourney:风头无两的画师
除了上面提到的 Civitai 和 Hugging Face 两个开源社区,Midjourney 也是 AI 绘画的一大杀器。不同于 WebUI,我们可以在聊天应用程序 Discord 中使用 Midjourney,不需要本地 GPU 资源,也不需要安装任务 WebUI 类的工具。相比前面的两个开源社区,Midjourney 模型 AI 绘画的效果在精致度、图像文本关联性上都有更显著的优势。
这里我们一起看看 Midjourney 的三种常见用法。
首先是文字生图,在 Midjourney 的 Discord 论坛中,使用 /imagine 可以触发文生图功能。

比如,我们可以通过简单的描述,让 Midjourney 帮我们生成各种美观有趣的卡通头像、可口诱人的美食、靓丽的风景、可爱的小动物,或者是有特色的艺术作品,再或者是现实生活中完全不存在的事物。我放了一些自己用 Midjourney 生成图片的效果示例,你可以点开图片感受一下。



然后是图生图。在 Midjourney 的 Discord 论坛中,首先将图像发送给 Midjourney 获得图像的链接,图片链接粘贴完成后,必须空一格,再输入描述语,按下回车键,最终新生成的图片就会参考原图。
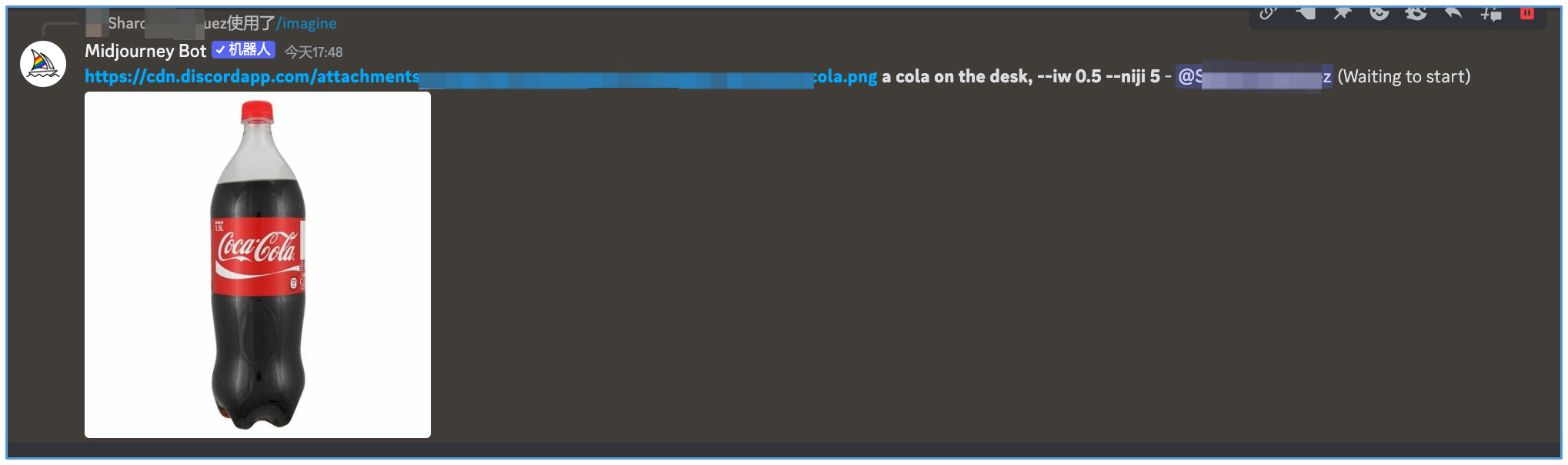
比如我们输入一张可乐的无背景图,希望将可以放到一张桌子上。我们便可以得到下面的效果。

prompt 语句中使用 --iw 命令可以控制新图片与参考图的相似程度,Midjourney V5.2 版本这个数值的范围为 0 ~ 2, 默认值为 0.25。数值越大,参考原图的比重越高。
认真观察上面的图片你会发现,可乐的瓶身似乎有一些变化。你可以试试将 --iw 参数再调整大一些。你也许也听过 Nijijourney 这个模型,它是在 Midjourney 原始模型的基础上,使用大量动漫图像进行模型微调后得到的二次元风格专属模型。如果我们使用 Nijijourney 模型进行上述图生图人物,--iw 设置 0.2,你会得到下面的结果。

最后是多图融合。Midjourney 支持将 N 张图进行图像融合,N 最大支持 5 张。比如下面这个例子中,我们将一张女生照片和一张水墨画进行融合,得到的效果你可以点开图片查看。
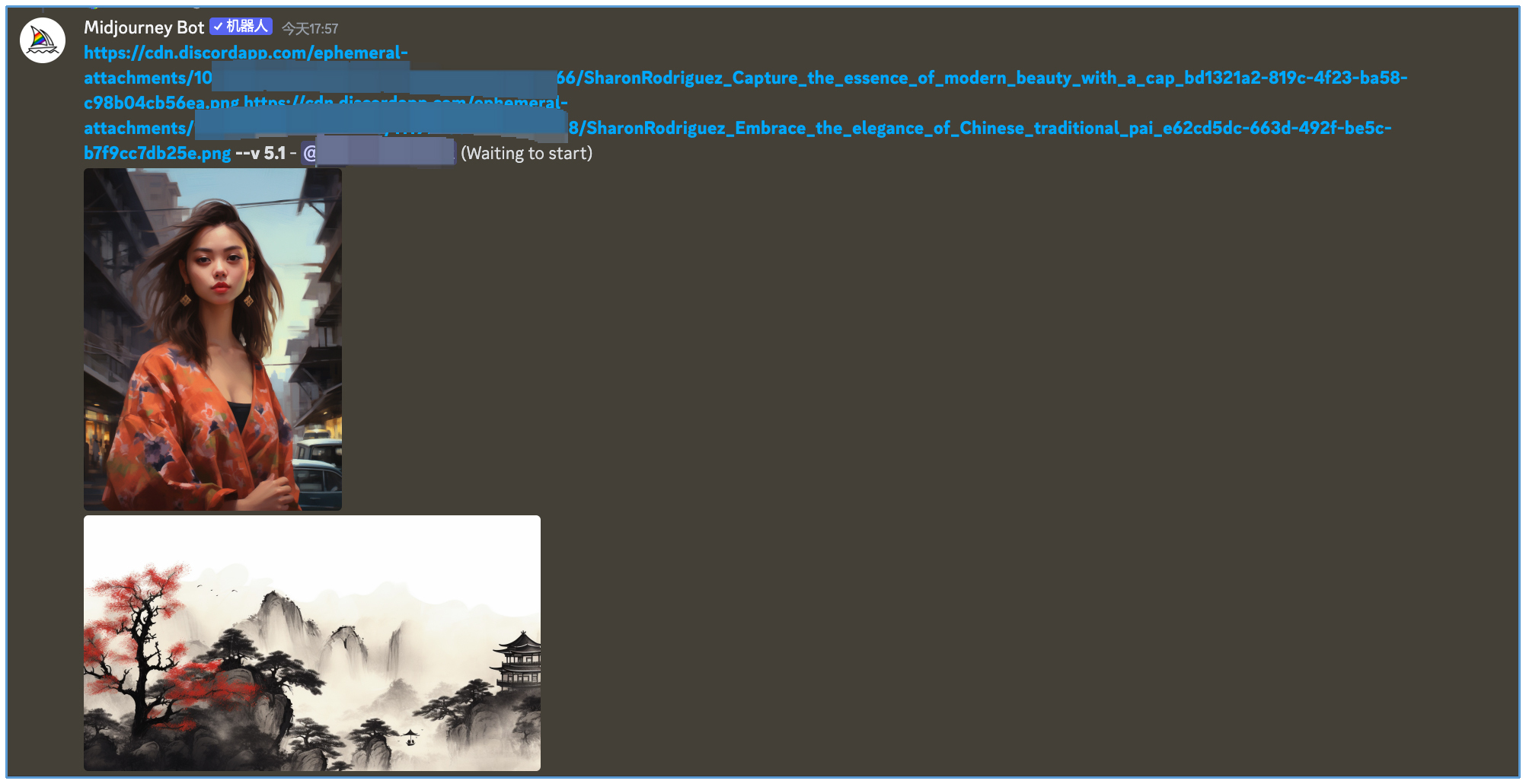

Midjourney 当前并不支持 LoRA 用法,但类似 WebUI 的部分功能还是可以实现的,比如使用负面描述词、文本权重调整的技巧,不过在具体用法上和 WebUI 略有不同。比如负面描述词,可以通过 --no 来指定;文本权重调整,可以通过 :: 数值来指定。
为了帮你加深理解,我们结合后面这两个例子对比一下。
Midjourney 描述词 1,创作一幅温馨真挚微笑的年轻亚洲女孩的写实肖像画。
Create a realistic portrait of a young asian girl with a warm, genuine smile --ar 2:3Midjourney 描述词 2,我们要求图像里避免出现眼镜和卷发,而且对写实、年轻和微笑都设置了不同的文本权重。
Create a realistic::-1.0 portrait of a young::1.5 asian girl with a warm, genuine smile::1.4 --no glasses curly hair --ar 2:3你可以看一下这两个描述得到的图像,负面描述词和文本权重都发挥了各自的作用。

不得不说,当前 Midjourney 在 AI 绘画文字生图的效果上要领先于开源社区的模型。遗憾的是 Midjourney 的模型并没有开源,我们只能通过账号付费的形式来使用。如果你想使用 Midjourney,可以访问这个链接,如何用较低的成本使用 Midjourney 提供的服务,也欢迎同学们在评论区留下自己的小技巧。
5. 总结
这一讲我们从文生图过渡到图生图,探索了重绘强度和 prompt 咒语的巧妙使用。不同于文生图这种无中生有的用法,图生图能够针对我们提供的图片实现各种趣味编辑,比如图像风格化、老照片修复、图像内容补全等。
重绘强度是图生成图模型中的一个关键参数,它表示图像的重绘程度。较高的重绘强度可以使生成图像更多样化,但仍保持原始图像的整体轮廓。通过调整重绘强度,你可以控制生成图像与原始输入图像内容的变化程度,实现图生图的风格化、编辑等过程。
另外,我们一起探索了 Hugging Face 和 Civitai 这两大重要的开源模型社区,通过这些社区,你可以发掘大量的开源模型和资源,实现多样化的图像生成,大幅提升自己的 AI 绘画能力。Civitai 可以直接在 WebUI 中进行管理和使用,而 Hugging Face 社区中的模型,我们也可以直接注册 HuggingFace 账号,通过 diffusers 库来调用。
最后我们还了解了 Midjourney 这个专业的 AI 绘画工具,介绍了 Midjourney 的三种常见用法:文字生图、图像生图和多图融合。未开源的 Midjourney 模型在生成效果、图文一致性上都有不俗的表现,本地无需 GPU 资源即可体验 Midjourney 的生成效果。
6. 思考题
假设你使用图生图模式生成了一张卡通风格的猫的图片,你调整了重绘强度和 prompt,尝试了不同的参数组合,但始终无法获得满意的结果。你观察到生成的图像要么失去了猫的特征,要么与原始图像过于相似。请思考可能的原因,并提出解决方案。
欢迎你在留言区和我交流互动,也推荐你把这一讲分享给更多朋友,和他一起交流开源 AI 绘画工具的乐趣。
7. 补充
peter 请教老师几个问题:
Q1:对于上传的图片为什么要加噪声?
Q2:webUI 可以用于手机端吗?比如安卓。
Q3:模型的训练时间长,但训练完成后,模型确定了,类似于有了一个确定的函数,所以运算就很快,是这样吗?
作者回复: 你好,针对 Q1,因为图生图的本质是对原始图像的二次编辑,背后的原理是扩散模型(第6讲会详细介绍这个过程及原理)。向图像中添加噪声得到模糊的图像(加到我们用重绘强度指定的某一步),再利用文本信息引导模型去除噪声,便可以得到我们要编辑的效果。针对 Q2,据我了解,当前WebUI还不能用在手机端,但未来随着算法加速和硬件优化,手机端AI绘画还是有可能的,这也是当前 AI 绘画的研究热点之一。针对Q3,你的理解基本是正确的。模型训练的过程是在训练 UNet 去噪结构(我们第6-8讲会详细讲),这个学习的过程需要海量的数据来驱动,需要很多 GPU、很长时间;训练完成后,我们只需要使用训练好的 UNet 模型来帮忙计算,经过 20~30 step 便可以出图,因此速度就会快一些。
奇怪,本身 sd 就是一个预训练模型了,还需要加载其他模型和 lora
作者回复: 你好,其他模型,比如 Textual Inversion 和 LoRA,都是在原有 SD 模型基础上,新衍生的绘画能力。比如我们基于 SD1.5,希望能够进行微调得到善于生成“漩涡鸣人”的模型,又不希望调整 SD1.5 的原有参数影响其本身的生成能力,便会引入 Textual Inversion 或者 LoRA。我们只需要几张到几十张“漩涡鸣人”的图片就能优化我们自己的模型,使用的时候加载新增的参数即可。有两个好处:一是参数少、数据少,普通人手中的资源也能训练的动;二是使用的时候即插即用,即得到了想要的新功能、又不影响模型的原有能力。 关于这类技巧,在实战篇我们会深入探讨其技术原理,敬请期待。希望能帮助到你。
电脑配置太低用不了SD...我这课是不是白听了呜呜
作者回复: 你好。网上有很多平替工具,可以用于体验 SD 效果,甚至可以用于训练模型。不妨搜一搜“AI绘画工具”。除了实战1需要使用 WebUI,后续的实战课我们都是基于 Google Colab 完成的,自身的电脑配置不会是问题,大可放心。另外,我们的课程除了工具使用,更多希望探讨AI绘画背后的技术原理。希望能帮助到你。
欢迎关注我公众号:AI悦创,有更多更好玩的等你发现!
公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh
