
03|探索智能体世界:LangChain与RAG检索增强生成

你好,我是悦创。
上节课我们学习了如何构造提示,让 AI 大模型高效输出我们需要的内容,相信你已经迫不及待地体验过了,但是你有没有发现 AI 大模型在使用的过程中是有一些局限的,比如:
- 数据的及时性:大部分 AI 大模型都是预训练的,拿 ChatGPT 举例,3.5 引擎数据更新时间截止到 2022 年 1 月份,4.0 引擎数据更新时间截止到 2023 年 12 月份,也就是说如果我们问一些最新的信息,大模型是不知道的。
- 复杂任务处理:虽然 AI 大模型在问答方面表现出色,但它们并不总是能够处理复杂的任务,比如直接编辑或优化 Word 文档或 PDF 文件。这些任务通常需要特定的软件工具和用户界面,而大模型主要是基于文本的交互(多模态除外)。
- 代码生成与下载:我们希望大模型根据需求描述生成对应的代码,并提供下载链接,大模型也是不支持的。
- 与企业应用场景的集成:在和企业应用场景打通的时候,我们希望大模型读取关系型数据库里的数据,并根据提示进行任务处理,同样大模型也是不支持的。
这样的场景非常多,因为大模型的核心能力是意图理解与文本生成,而在我们实际应用过程中,输入数据和输出数据不仅仅是纯文本。很多时候我们需要解析用户的输入,比如把 Word 或 PDF 文件转化为纯文本,从一个关系型数据库读取数据转化为大模型的输入数据,将大模型的输出内容进行压缩打包并上传至网站供用户下载等等。那这一类任务由谁来做呢?那就是 AI 智能体,也叫 AI Agent。
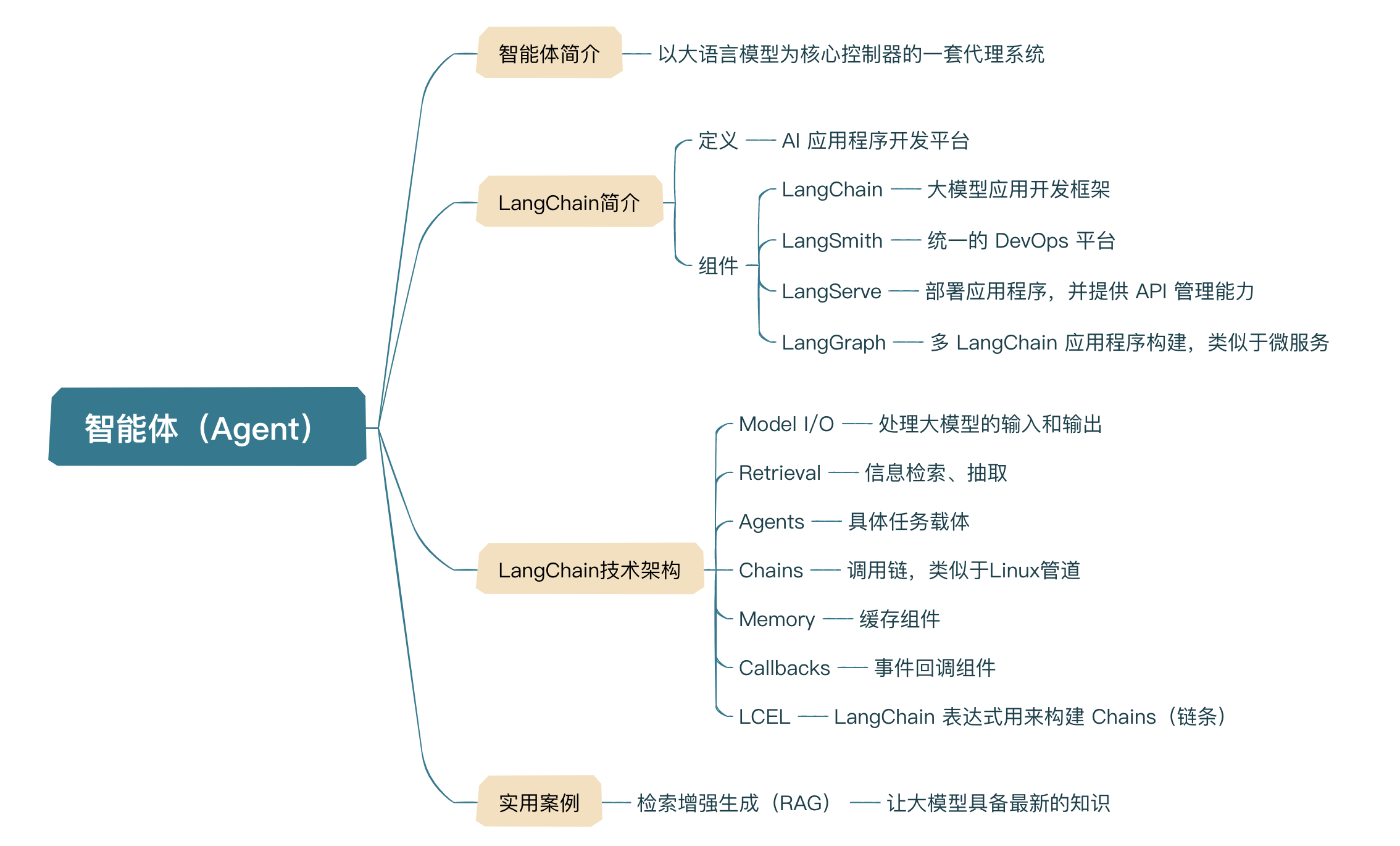
1. AI Agent
AI Agent 就是以大语言模型为核心控制器的一套代理系统。
举个形象的例子:如果把人的大脑比作大模型的话,眼睛、耳朵、鼻子、嘴巴、四肢等联合起来叫做 Agent,眼睛、耳朵、鼻子感知外界信号作为大脑的输入;嘴巴、四肢等根据大脑处理结果形成反馈进行输出,形成以大脑为核心控制器的一套系统。
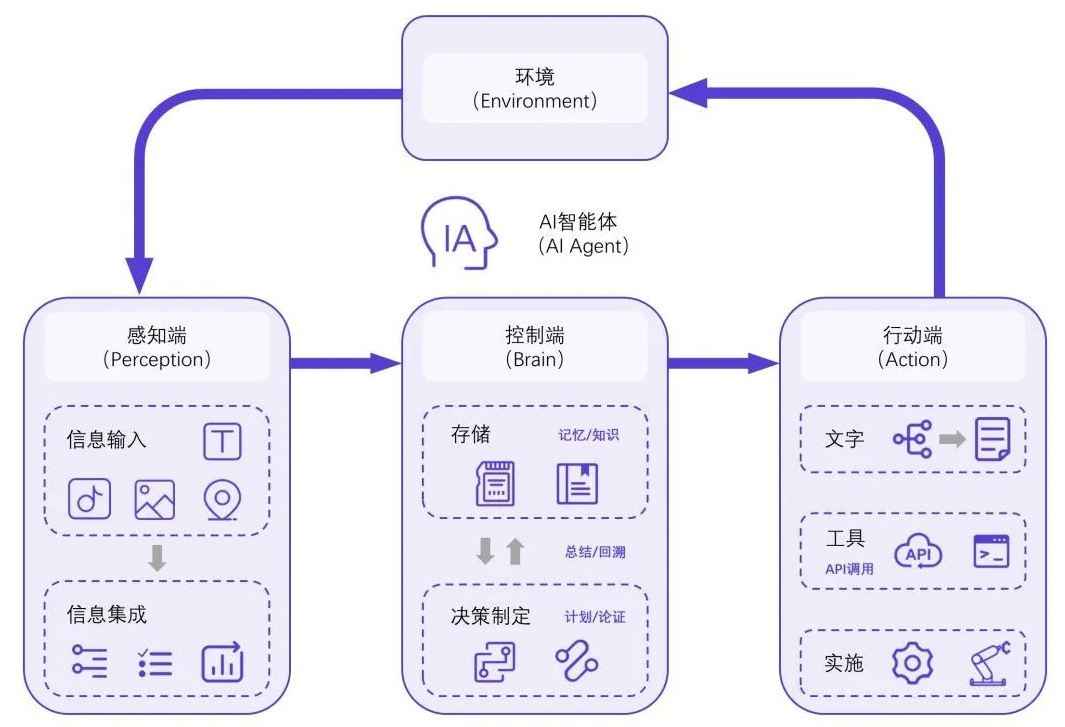
控制端处于核心地位,承担记忆、思考以及决策制定等基础工作,感知模块则负责接收和处理来自外部环境的多样化信息,如声音、文字、图像、位置等,最后行动模块通过生成文本、API 调用、使用工具等方式来执行任务以及改变环境。
相信通过这样的介绍,你就明白智能体的概念和结构了,接下来我给你介绍一些常见的智能体技术,下面我们统称为 Agent。目前比较流行的 Agent 技术有 AutoGen、LangChain 等,因为 LangChain 既是开源的,又提供了一整套围绕大模型的 Agent 工具,可以说使用起来非常方便,而且从设计到构建、部署、运维等多方面都提供支持,所以下面我们主要介绍一下 LangChain 的应用场景。
2. LangChain 介绍
起初,LangChain 只是一个技术框架,使用这个框架可以快速开发 AI 应用程序。这可能是软件开发工程师最容易和 AI 接触的一个点,因为我们不需要储备太多算法层面的知识,只需要知道如何和模型进行交互,也就是熟练掌握模型暴露的 API 接口和参数,就可以利用 LangChain 进行应用开发了。
LangChain 发展到今天,已经不再是一个纯粹的 AI 应用开发框架,而是成为了一个 AI 应用程序开发平台,它包含 4 大组件。
- LangChain:大模型应用开发框架。
- LangSmith:统一的 DevOps 平台,用于开发、协作、测试、部署和监控大模型应用程序,同时,LangSmith 是一套 Agent DevOps 规范,不仅可以用于 LangChain 应用程序,还可以用在其他框架下的应用程序中。
- LangServe:部署 LangChain 应用程序,并提供 API 管理能力,包含版本回退、升级、数据处理等。
- LangGraph:一个用于使用大模型构建有状态、多参与者应用程序的库,是 2024 年 1 月份推出的。
放到我们传统软件开发场景中,我认为 LangChain 就类似于 SpringCloud;LangSmith 类似于 Jenkins + Docker + K8s + Prometheus;LangServe 类似于 API 网关;LangGraph 类似于 Nacos;当然只是简单比拟。
LangChain 可以说是当前最火的 AI Agent 技术框架,GitHub 上拥有超过 80k stars,另外使用 MIT 开源协议,非常友好,自己研究或公司拿来商用都没有问题。
不过一切还在快速发展中,相信很快就会有更多的技术出来。为什么这么说呢?就拿软件开发举例,现在的开发流程是:开发工程师在 IDE(IDEA/Eclipse/VSCode)里编写代码,然后打包部署,测试工程师进行测试,然后发布上线。
目前看,大模型已经具备代码编写的能力,理想场景不太可能是由大模型把代码写好,我们下载到本地,用 IDE 打开,然后打包部署、测试,这说白了只是替换了目前代码编写的场景。我觉得如果 AI 颠覆软件开发行业,一定是从编码到测试,再到部署一整套流程的颠覆。到那个时候,我们的开发流程可能就变成我上节课讲的那样了。
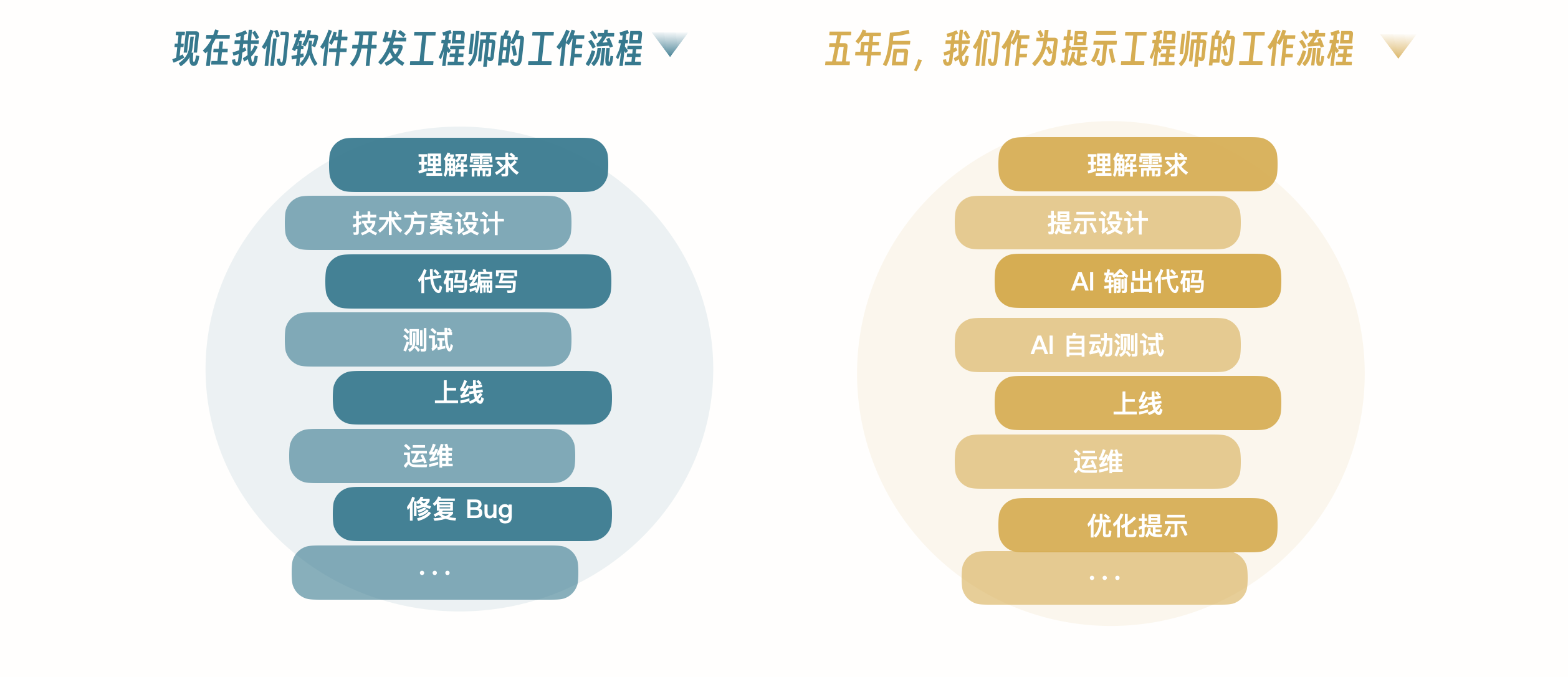
当然,也必须要配套相关的技术框架、管理工具来支撑,比如 Prompt 管理是否还会用 Git?会不会有另一套类似于 Git 用来管理 Prompt 的工具?代码还会不会存在?大模型可否直接生成可执行程序?还会有 Jenkins 吗?
你可以畅想一下,未来一整套的技术架构都有可能会被颠覆。
3. LangChain 技术架构
接下来我们看一下目前 LangChain 整个平台技术体系,不包含 LangGraph,LangChain 框架本身包含三大模块。
- LangChain-Core:基础抽象和 LangChain 表达式语言。
- LangChain-Community:第三方集成。
- LangChain:构成应用程序认知架构的链、代理和检索策略。
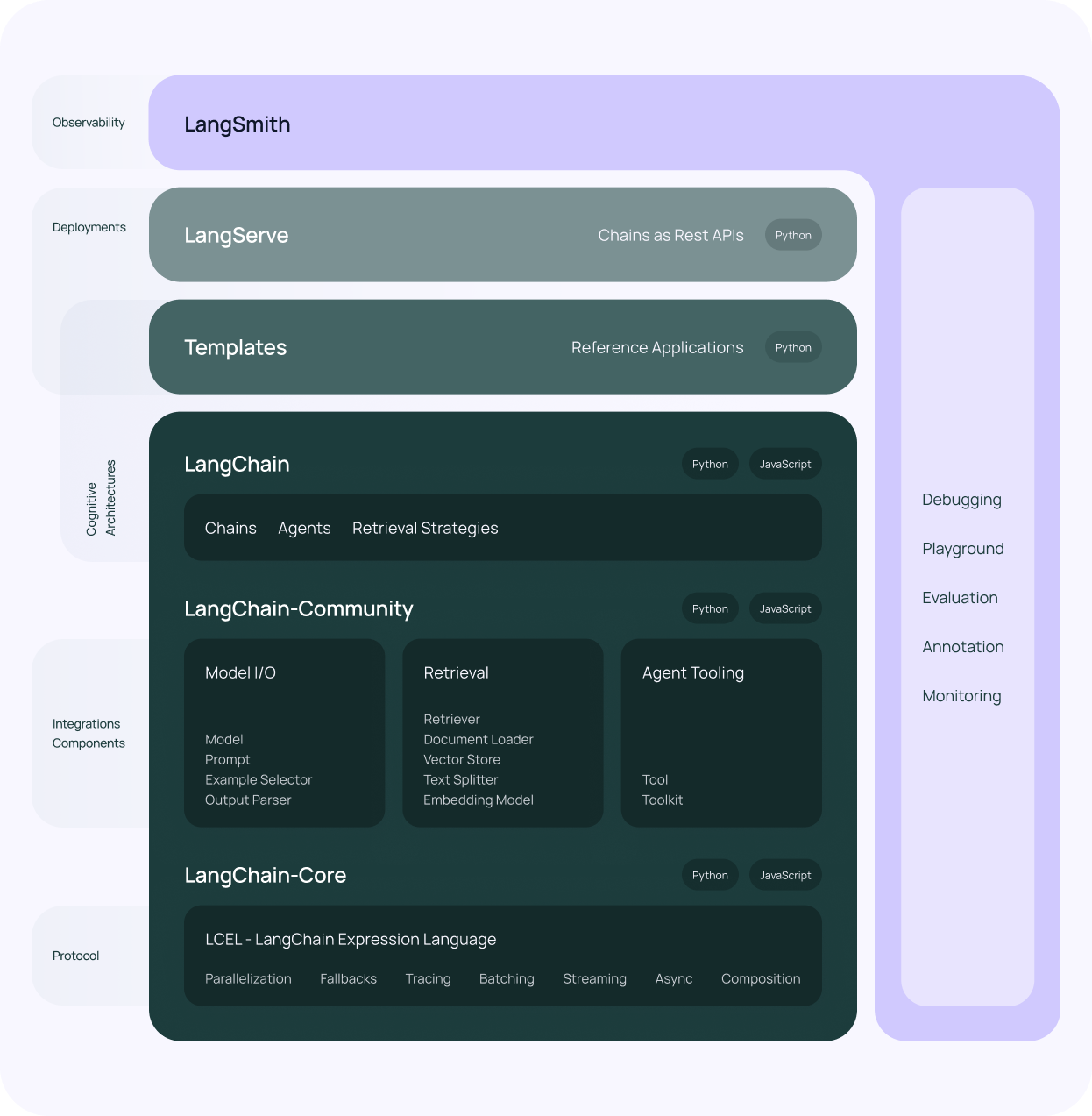
下面我们介绍一下其中的重要模块。
3.1 模型 I/O(Model I/O)
模型 I/O 模块主要由三部分组成:格式化(Format)、预测(Predict)、解析(Parse)。顾名思议,模型 I/O 主要是和大模型打交道,前面我们提到过,大模型其实可以理解为只接受文本输入和文本输出的模型。
此处注意⚠️:目前 LangChain 里的大模型是纯文本补全模型,不包含多模态模型。
在把数据输入到 AI 大模型之前,不论它来源于搜索引擎、向量数据库还是第三方系统接口,都必须先对数据进行格式化,转化成大模型能理解的格式。这就是格式化部分做的事情。
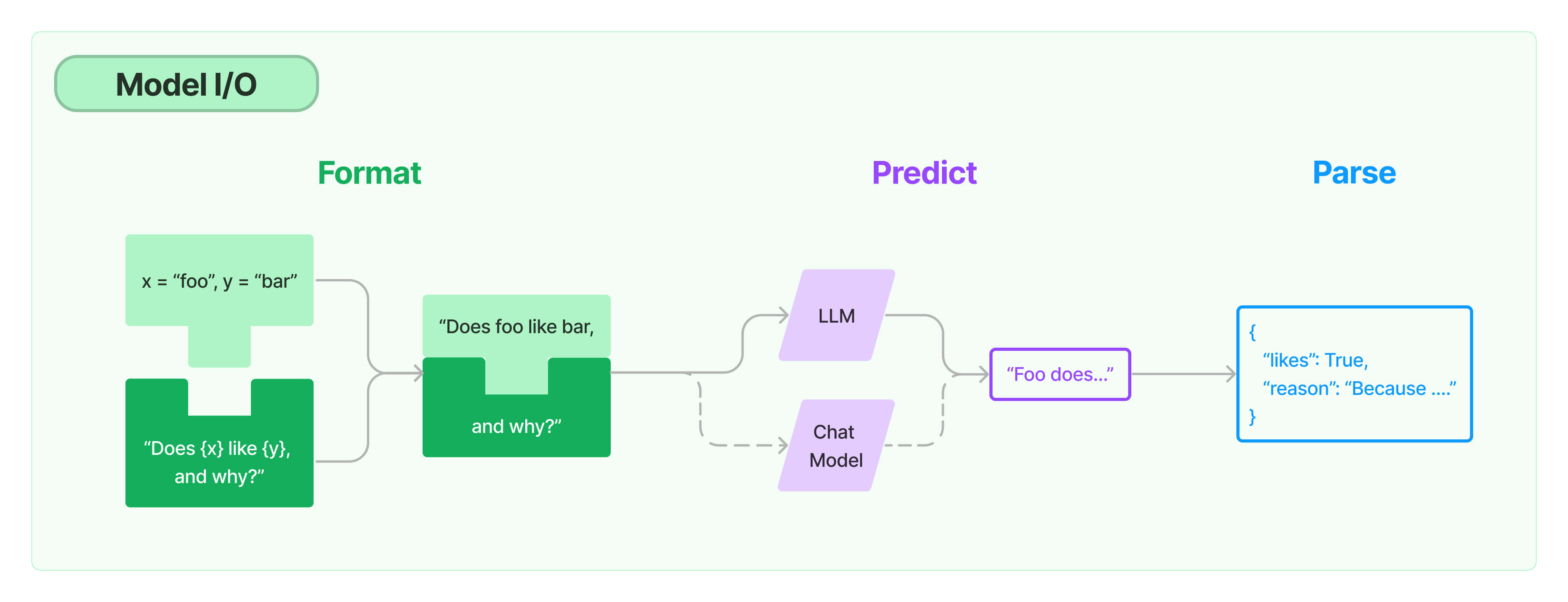
预测是指 LangChain 原生支持的丰富的 API,可以实现对各个大模型的调用。
解析主要是指对大模型返回的文本内容的解析,随着多模态模型的日益成熟,相信很快就会实现对多模态模型输出结果的解析。
3.2 Retrieval
Retrieval 可以翻译成检索、抽取,就是从各种数据源中将数据抓取过来,进行词向量化 Embedding(Word Embedding)、向量数据存储、向量数据检索的过程。你可以结合图片来理解整个过程。
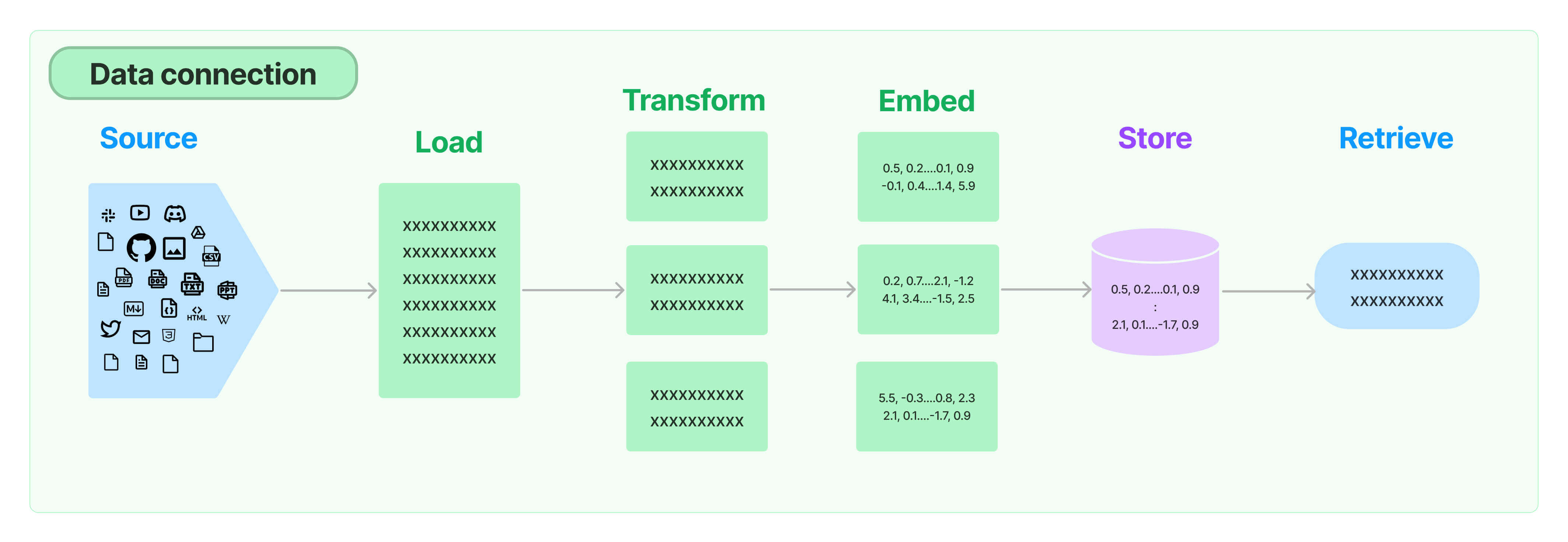
我会在后面的实战过程中,通过代码来演示各个阶段的含义。
3.2.1 Agents
Agents(代理)就是指实现具体任务的模块,比如从某个第三方接口获取数据,用来作为大模型的输入,那么获取数据这个模块就可以称为 XXX 代理,LangChain 本身支持多个类型的代理,当然也可以根据实际需要进行自定义。
3.2.2 Chains
链条就是各种各样的顺序调用,类似于 Linux 命令里的管道。可以是文件处理链条、SQL 查询链条、搜索链条等等。LangChain 技术体系里链条主要通过 LCEL(LangChain 表达式)实现。既然是主要使用 LCEL 实现,那说明还有一部分不是使用 LCEL 实现的链条,也就是 LegacyChain,一些底层的链条,没有通过 LCEL 实现。
3.2.3 Memory
内存是指模型的一些输入和输出,包含历史对话信息,可以放入缓存,提升性能,使用流程和我们软件开发里缓存的使用一样,在执行核心逻辑之前先查询缓存,如果查询到就可以直接使用,在执行完核心逻辑,返回给用户前,将内容写入缓存,方便后面使用。
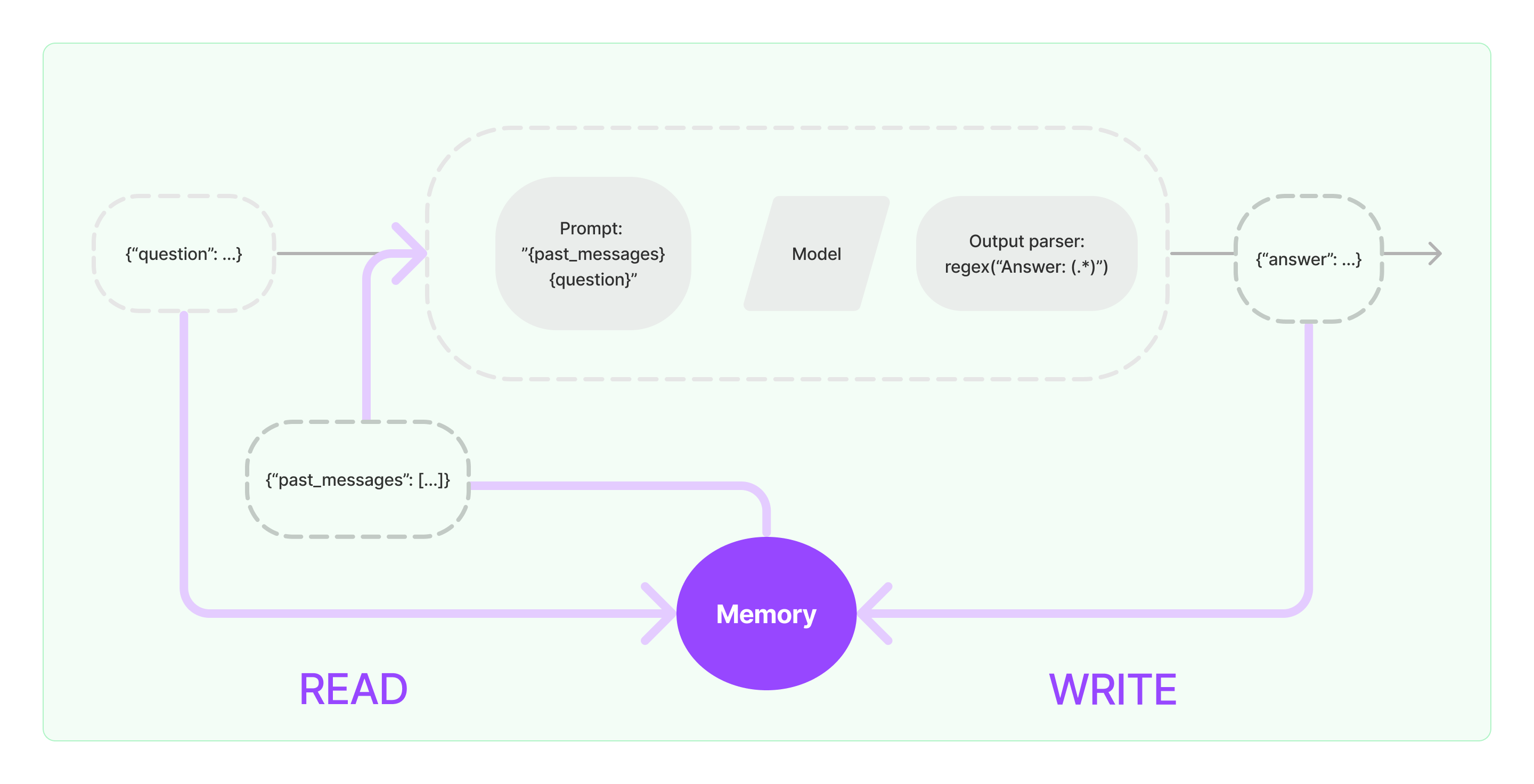
3.2.4 Callbacks
LangChain 针对各个组件提供回调机制,包括链、模型、代理、工具等。回调的原理和普通开发语言里的回调差不多,就是在某些事件执行后唤起提前设定好的调用。LangChain 回调有两种:构造函数回调和请求回调。构造函数回调只适用于对象本身,而请求回调适用于对象本身及其所有子对象。
3.2.5 LCEL
LangChain 表达式,前面我们介绍 Chains(链)的时候讲过,LCEL 是用来构建 Chains 的,我们看官方的一个例子。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI(model="gpt-4")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
chain.invoke({"topic": "ice cream"})就像我前面讲到的一样,这里的链和 Linux 里的管道很像,通过特殊字符 | 来连接不同组件,构成复杂链条,以实现特定的功能。
chain = prompt | model | output_parser每个组件的输出会作为下一个组件的输入,直到最后一个组件执行完。当然,我们也可以通过 LCEL 将多个链关联在一起。
chain1 = prompt1 | model | StrOutputParser()
chain2 = (
{"city": chain1, "language": itemgetter("language")}
| prompt2
| model
| StrOutputParser()
)
chain2.invoke({"person": "obama", "language": "spanish"})以上就是 LangChain 技术体系里比较重要的几个核心概念,整个设计思想还是比较简单的,你只要记住两个核心思想。
- 大模型是核心控制器,所有的操作都是围绕大模型的输入和输出在进行。
- 链的概念,可以将一系列组件串起来进行功能叠加,这对于逻辑的抽象和组件复用是非常关键的。
理解这两个思想,玩转 LangChain 就不难了,下面我举一个 RAG 的例子来说明 Agent 的使用流程。
4. Agent 使用案例——RAG
就像前面讲的,大模型是基于预训练的,一般大模型训练周期 1~3 个月,因为成本过高,所以大模型注定不可能频繁更新知识。正是这个训练周期的问题,导致大模型掌握的知识基本上都是滞后的,GPT-4 的知识更新时间是 2023 年 12 月份,如果我们想要大模型能够理解实时数据,或者把企业内部数据喂给大模型进行推理,我们必须进行检索增强,也就是常说的 RAG,检索增强生成。
就拿下面这个案例来说吧,我们可以通过 RAG 技术让大模型支持最新的知识索引。我们先来看一下技术流程图。
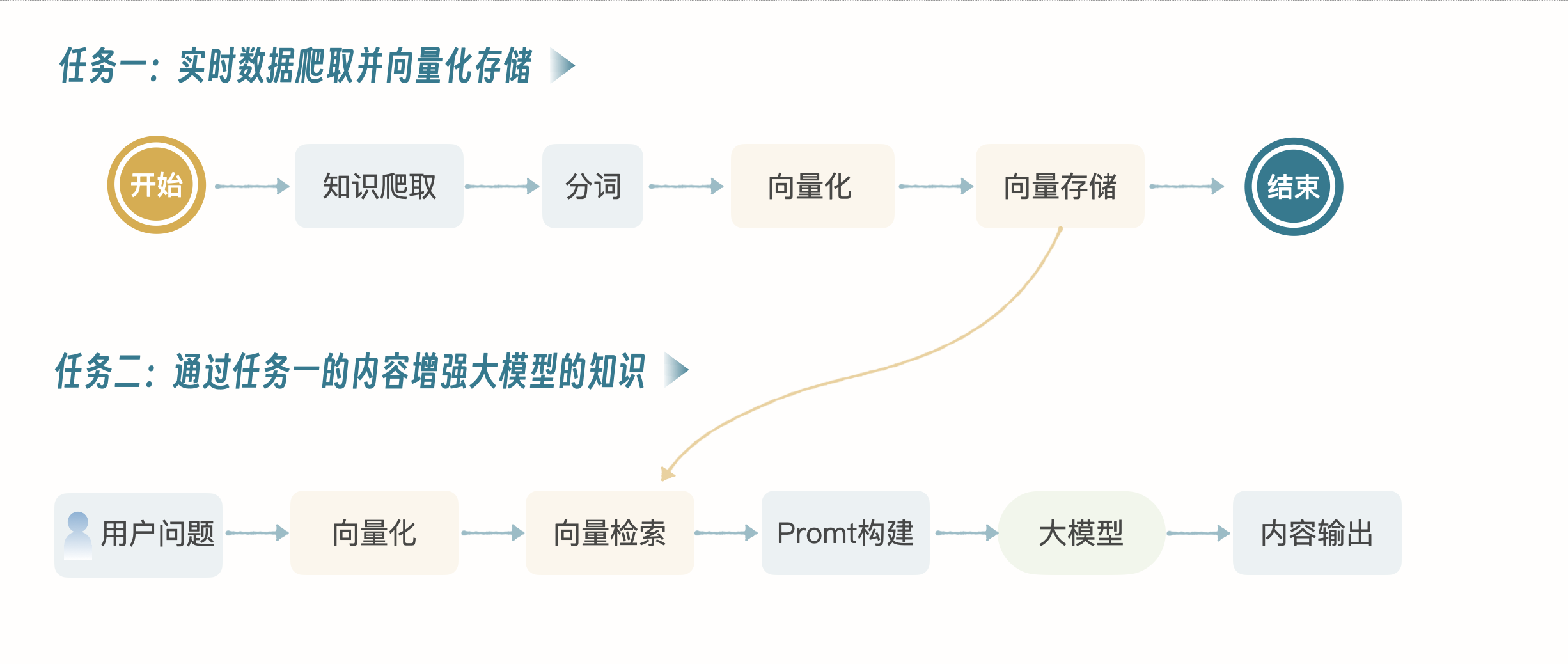
任务一:先通过网络爬虫,爬取大量的信息,这个和搜索引擎数据爬取过程一样,当然这里不涉及 PR(Page Rank),只是纯粹的知识爬取,并向量化存储,为了保障我们有最新的数据。
任务二:用户提问时,先把问题向量化,然后在向量库里检索,将检索到的信息构建成提示,喂给大模型,大模型处理完进行输出。
整个过程涉及两个新的概念,一个叫向量化,一个叫向量存储,你先简单理解下,向量化就是将语言通过数学的方式进行表达,比如男人这个词,通过某种模型向量化后就变成了类似于下面这样的向量数据:
[0.5,−1.2,0.3,−0.4,0.1,−0.8,1.7,0.6,−1.1,0.9]注意:此处只是举例,实际使用过程中男人这个词生成的向量数据取决于我们使用的 Embedding 模型,这个知识我们会在后面的内容中讲解。
向量存储就是将向量化后的数据存储在向量数据库里,常见的向量数据库有 Faiss、Milvus,我们会在后面的实战部分用到 Faiss。
通过任务一、二的结合,大模型就可以使用最新的知识进行推理了。当然不一定只有这一种思路,比如我们不采取预先爬取最新的数据的方式,而是实时调用搜索引擎的接口,获取最新数据,然后向量化后喂给大模型,同样也可以获取结果。在实际的项目中,要综合成本、性能等多方面因素去选择最合适的技术方案。
5. 小结
这节课我们详细学习了智能体以及 LangChain 技术体系。目前看来,智能体很有可能在未来一段时间内成为 AI 发展的一个重要方向。因为大模型实际上是大厂商的游戏(除非未来开发出能够低成本训练和推理的大模型),而智能体不一样,普通玩家一样可以入局,而且现在基本上是一片蓝海。
6. 思考题
从软件开发及架构的思路去看,LangChain 未来还有可能增加什么组件?你可以对比 Java 技术体系来思考一下。欢迎你把你思考后的结果分享到评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见。
老师langchain和dify的在团队实践中如何选择,dify似乎有比较友好的操作界面,langchain似乎对嵌入企业原有流程更加灵活,那么这两个老师有什么看法
作者回复: 各有优点,langchain适合代码级别的集成,dify界面做的比较好。实际生产环境中,我们最终肯定也是需要界面的,如果用langchain,我们需要自己做相关的界面,用dify的话,有些界面就不需要做了,比如模型的对接,知识库、知识的管理等等。同时,dify是国产的,这一点很重要,产品的交互方面符合国人的使用习惯。最后,dify是商业化产品,有全职人员进行开发,langchain是纯开源产品,质量和稳定性方面可能会稍微欠缺一些。
抱着了解的想法看了免费的前4节,现在看收获很大,了解到了一个很重要的概念,AI Agent。一直以来,我对AI都是持观望的态度,感觉自己只是一个普通的业务开发,没有能力参与到AI行业。感觉老师为普通开发者打开了一条新的发展道路,普通开发者也是有机会的。打算深入了解一下langchain和dify,这可能是未来5年甚至10年的工作机会
作者回复: 加油!可以优先看dify,dify是国产的,界面比较友好,另外像Prompt和大模型微调也可以慢慢尝试下,都有机会。
老师想问一下RAG的那个流程,模型没有被这些最新数据或者企业内部数据训练过,怎么能保证模型的输出一定符合预期呢
作者回复: 如果走知识库的话,其实就是检索,和传统关键字检索的区别在于,这里我们说的是向量检索,更接近真实意思。输出能否符合预期,要不断调试、调整,文本向量化要先分词,所以有一定的可能性会匹配不上。
老师,现在市场上应用最多的是langchain吗,后面课程会不会讲一点实战案例
作者回复: langchain比较火,其实归功于agent概念的火爆,实践的时候能否用得到,这是个问题,原因是即便langchain支持几百种工具调用,但是现实情况是每家企业需要的工具就几种,大部分用不到。我们公司在落地的时候用了dify,也自己手写了一部分agent。所以目前的课程里只介绍了langchain入门,后面会不会增加目前还不确定。
RAG ,文心一言似乎就是这么做的。每次键入问题,首先先去网络上查询数据,再转换成向量喂给大模型作为提示,现在理解了。
作者回复: 现在基本都是这么做的,可以解决知识更新的问题。
打卡第三课。 个人思考,我觉得langchain已经把组件的大框框给框定的差不多了,核心开发框架,运维部署监控框架,以及服务治理框架。要说可能缺少的可以单独拎出来一套自动化测试框架。而且目前的组件是一个大集成,以后可能会把组件细分。 比如retrieval模块可以单独抽出来,方便以后扩展支持多模态的内容录入以及检索。 因为每个模块发展到后来可能都会变得越来越复杂。这也正是以前传统软件框架发展的规律
作者回复: 没错,langchain的发展可以参考传统软件框架的发展
新手提问:在使用RAG模型处理特定问题时,如果我整合的知识与模型预先训练的知识发生冲突,应该如何处理?更具体地说,我们应该依赖模型原有的知识还是优先使用自建的知识库?
作者回复: 需要你自己确定,要么使用模型推理,要么使用知识库,结合使用也可以,需要你自己看效果来确定
对划分哪些是Agent 指责,哪些是大模型职责,可以用一个案例讲解一下,一个现有业务系统怎么改变成自己的Agent 吗
作者回复: 你可以发一下你的案例,我帮你梳理下,目前没有计划弄一个案例讲解,文中有提到一些通用的场景比如PDF处理这些
第3讲打卡~ 个人思考:未来LangChain是否有可能扩展数据存储模块,例如LangStore,统一封装对于不同存储引擎的存储、索引和查询相关功能,如搜索场景的ES或者向量数据库Milvus。
作者回复: 我觉得有可能,我一直把langchain的技术体系参考Java技术体系,在Java体系里有的东西,在Agent领域都会有
老师,请问模型通过理解指令并决策后输出的结果是什么形式的,比如在自动驾驶或机器人场景,路径规划,方向盘或电机转角,力矩这些action是模型直接生成的,还是agent对模型输出进行加工处理后得到的,另外这方面的知识有什么途径可以获取和学习吗?
作者回复: 一般来说,模型直接生成的都是纯文本(多模态除外),你说的路径规划这些action大概率是经过处理的,学习路径还是要放在实战中,你需要先研究场景,然后确定哪部分是需要大模型做的,哪部分可能是传统小模型,哪部分是agent来做,分析完技术方案就有了
老师有个问题咨询下,文中提到Embedding 模型,在一个RAG流程中使用不同大模型例如qwen,llama时,这个Embedding 模型是需要特定匹配qwen或llama的才行么?如果需要那如何选择Embedding 模型呢?
作者回复: Embedding模型与大模型不需要特定匹配。可以选择开放的Embedding模型,也可以自己训练。
LangChain 未来还有可能增加分布式大模型调度组件、支持集群部署、负载均衡😂
作者回复: 是的,把传统开发这一套都搬到大模型领域
目前这些ai agent的工具在多模态和端侧嵌入式场景适用吗
作者回复: 适用的,除了纯文本生成这样的场景,一般应用场景都需要Agent辅助的
公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Web、Linux」,招收学员面向国内外,国外占 80%。全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh
