
Homework 8
Homework 8
Exercise 1: Sieve of Eratosthenes
Early in the course, we saw a few naive ways to output a list of prime numbers. Although we were able to improve the speed of the search a lot by incorporating a few arithmetic insights, it still took longer than it needed to for somewhat larger numbers.
Now that we have looked at sets in Python, we are better equipped to implement a more efficient approach to collecting prime numbers: the Sieve of Eratosthenes.
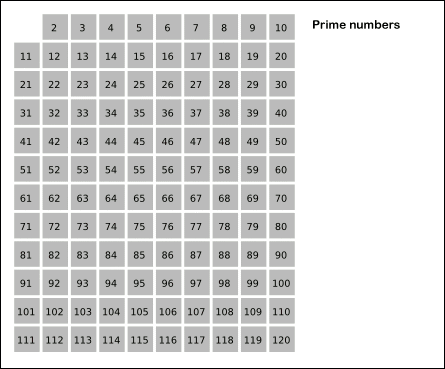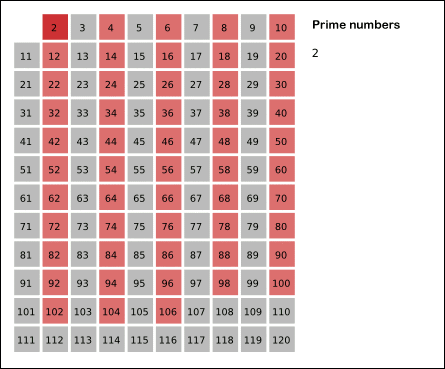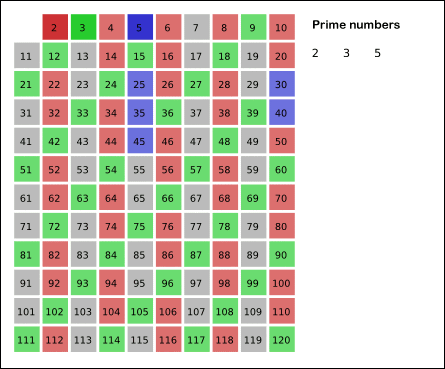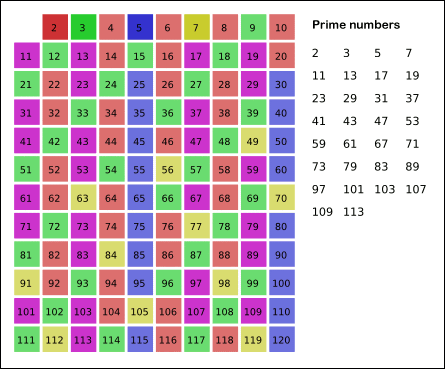
The idea behind the Sieve of Eratosthenes is that finding composite numbers (non primes) is a lot easier than finding primes, so we can follow a process of elimination where we exclude composites to quickly winnow down our collection of candidate numbers.
We do this by iteratively identifying as composite the multiples of values, starting at 2. We then exclude in our subsequent search anything that has been identified as a composite previously. Each time we hit a prime we add that to our list of primes and then mark all multiples of the prime as composites.
This graphic illustrates the algorithm in action:
https://course.ccs.neu.edu/cs5001f20-sea/images/Sieve_of_Eratosthenes_animation.gif
By SKoppLinks to an external site. at German WikipediaLinks to an external site. - Own work, Original image at Image:Animation_Sieve_of_Eratosth.gifLinks to an external site., CC BY-SA 3.0Links to an external site., LinkLinks to an external site.
Implementation
Write three files:
list_primes.pyshould import your prime generator module, and contain a main function that call a method defined in that module that returns the list of primes, and finally it should print them out.prime_generator.pywill define the classPrimeGeneratorthat contains a methodprimes_to_max()that takes an integer argument and returns a list of all primes from 2 to the argument value. It should employ the Sieve of Eratosthenes algorithm, which can be expected to compile a list for the argument 1000000 in about a second (this may vary somewhat, but you should expect to be in this ballpark).prime_generator_test.pywill be your PyTest test suite. It will import the PrimeGenerator class and define a single test function calledtest_primes_to_max(). Although it's not straightforward to test the output of our primes generator with absolute certainty, we can create a unit test that will test to ensure that some known primes are showing up in the appropriate places in the list when the method is called on smaller numbers. Use this guide: https://en.wikipedia.org/wiki/List_of_prime_numbersLinks to an external site. to write a fewassertstatements in your test to ensure that the method is (probably) working correctly.
As mentioned, use a list to collect the primes. Use a set to collect the composites as you go. Remember that the third argument of range() can be used to set the increment, which is useful in implementing this algorithm.
Exercise 2: N-gram frequencies
For this exercise you'll do some more text processing, this time taking advantage of dictionaries to collect some more useful statistics about a text.
Frequencies of words in sequence can be important features in machine learning models for natural language processing. Short sequences of word tokens are referred to as n-grams, where n is the number of tokens in each item. So,a count of unigrams is simply a count of occurrences for each word token. Bigrams refer to pairs of words in sequence (for example, "pairs_of", "of_words", "words_in", and "in_sequence") and trigrams are triples of words in sequence ("triples_of_words", "of_words_in", "words_in_sequence"). The longer the n-gram, the less frequently it will be found in a given text, so n-grams much longer than trigrams are often too sparsely distributed to be worth collecting.
For this exercise, you'll revisit corpse_bride.txtLinks to an external site. and write a program that will collect n-gram frequencies and print the top 10 of each type out, like this:
corpse_bride.txt
It's a Dead Scene, but That's a Good Thing
By MANOHLA DARGIS (New York Times)
A necro- philiac entertainment for the whole family to enjoy, "Tim Burton's Corpse Bride" marks the director's latest venture into the world of stop-motion animation, following "Tim Burton's The Nightmare Before Christmas" and "James and the Giant Peach." As in "Nightmare," kooky and spooky things go bump in the night, this time in the service of a lightly kinked romance about a melancholic boy, the girl he hopes to marry and the bodacious cadaver that accidentally comes between them.
Directed by Mr. Burton and Mike Johnson, and written by John August, Caroline Thompson and Pamela Pettler, the story hangs on a timid bachelor with matchstick legs and a pallid complexion, Victor (voiced by Johnny Depp), whose upwardly mobile parents arrange his marriage to Victoria (Emily Watson), the retiring daughter of impoverished gentry. When the wedding rehearsal goes kablooey, Victor retreats into the woods, whereupon he becomes the reluctant object of desire of the Corpse Bride, a blue-tinted beauty with gnawed-through limbs and a miraculously preserved bosom (Helena Bonham Carter, the director's very alive partner). Together, the eerie couple descends into the land of shades, inducing Victor to trade the world of the barely living for the land of the exuberantly dead.
For Victor and for his two directors, the underworld soon proves a more hospitable place than the world above, and far more entertaining. Above, the living shuffle about as somnolently as zombies amid a rainbow of gray, while down below, the walls are splashed with absinthe green, and the skeletons shake, rattle and roll. Bursting with mischief and life of a sort (think the grinning skulls of the Mexican artist JoseGuadalupe Posada), these skeletons dance themselves to pieces for a bravura musical number marred only by the composer Danny Elfman's insistence on recycling the same string of notes again and again. The notes reverberate more pleasantly when a gathering of spiders mend Victor's suit, notably because they trill a Gilbert and Sullivan pastiche as they stitch.
It all ends happily ever after, of course, though not before Mr. Burton and company have gathered the dead with the undead, and given a kick in the pants to a pinched-faced pastor even more shriveled than the bride herself. The anticlerical bit gives the story a piquant touch, while the reunion between the corpses and the ostensibly living further swells the numbers of zombies that have lately run amok in the movies. Cinema's reinvigorated fixation with the living dead suggests that we are in the grip of an impossible longing, or perhaps it's just another movie cycle running its course. Whatever the case, there is something heartening about Mr. Burton's love for bones and rot here, if only because it suggests, despite some recent evidence, that he is not yet ready to abandon his own dark kingdom.$ python ngrams.py corpse_bride.txt
Top 10 unigrams:
('the', 0.089)
('COMMA', 0.07)
('and', 0.039)
('a', 0.035)
('of', 0.031)
('to', 0.014)
('for', 0.012)
('in', 0.012)
('with', 0.012)
('by', 0.01)
Top 10 bigrams:
('COMMA_the', 0.016)
('in_the', 0.01)
('and_the', 0.008)
('COMMA_and', 0.008)
('of_the', 0.008)
('into_the', 0.006)
('the_world', 0.006)
('for_the', 0.004)
("tim_burton's", 0.004)
('corpse_bride', 0.004)
Top 10 trigrams:
('the_world_of', 0.004)
('mr_burton_and', 0.004)
('the_land_of', 0.004)
("it's_a_dead", 0.002)
('a_dead_scene', 0.002)
('dead_scene_COMMA', 0.002)
('scene_COMMA_but', 0.002)
("COMMA_but_that's", 0.002)
("but_that's_a", 0.002)
("that's_a_good", 0.002)A few points about the pre-processing:
- All alphabetical characters should be rendered in lowercase. Our n-grams will be case insensitive.
- N-grams will be collected only within sentences. Words on the end of one sentence will not form n-grams with words on the beginning of the next sentence. For this reason, we will need to split each paragraph of text into the sentences that compose it.
- In order to use periods to split sentences, we'll need to get rid of other periods first, such as those at the end of abbreviated like "Mr." and "Dr.". These words will have to be dealt with explicitly. Your pre-processor does not have to be exhaustive, but it should deal with the most common words of this nature.
- We will keep apostrophes in. We want to be able to distinguish
won'tfromwont, and without a more powerful tokenizer (with slightly deeper linguistic analysis) this means keeping the apostrophes. This means thatburtonandburton'swill be treated as two distinct tokens. - We will treat commas as tokens themselves. The way I approached this was to render each comma as the all caps token
COMMA. As you can see above, this token winds up being one of the most frequent unigrams and part of several frequent bigrams. - All other punctuation: quotes, parentheses, dashes, etc. will be stripped out.
Implementation
Write your program in a modular way and avoid re-duplicating code. Write a module with a class NgramFrequencies and create three instances of this class in your program: one for unigrams, one for bigrams, and one for trigrams. This will enable you to collect counts and frequencies for all three n-gram types independently. Each instance of NgramFrequenies should hold a dictionary of the corresponding n-grams with counts for each unique n-gram. It should also hold a total value, which contains the total counts for all of the appropriate ngrams. For example, the frequency of an individual trigram is the count of that trigram divided by the total number of trigrams in the data, so the NgramFrequencies instance for trigrams must collect this total. Your NgramFrequencies class should implement the following methods:
add_item()which takes an n-gram and increments its count in the dictionary.top_n_countswhich returns a list of items sorted on the count, with the most frequent first (see below for information about sorting dictionary items).top_n_freqswhich returns a similar list as above, but with frequencies instead of counts.frequencywhich takes an item and returns its frequency.
Write a test suite for this module called frequencies_test.py that implements tests for all of the methods listed above.
In addition to your NgramFrequencies class, write a separate module and class called TextCleaner which implements methods to carry out the text pre-processing described above (switching to lowercase, eliminating puntuation, etc.) We want to put all this ugly stuff in its own class so that it doesn't clutter up main or NgramFrequencies and so that it can be unit tested. Write a test suite called text_cleaner_test.py that tests whatever methods you've implemented in TextCleaner.
Again, put all files for this exercise together in a single directory called ngrams. You'll zip this file to upload to CodePost.
Returning a list of dictionary items sorted by values
Dictionaries themselves should be regarded as unordered. However, their items may be returned as a list of pairs (tuples) using the .items() method, and lists can be sorted using the sorted() function on lists. However, simply sorting the items won't quite do. By default, the items would be sorted according to the dictionary key, rather than the value; so we'd wind up with the n-grams in alphabetical order, rather than in order of count.
The sorted() function has several optional arguments that can help. The key argument lets us define an anonymous function that takes the item and returns a value; this value is then used as the basis for ordering the list. Since our items here are tuples and the value we want to order by is the second element of the tuple (index 1), the function we define will take x (a tuple) and return x[1] (the second value of the tuple). The syntax for this makes use of the lambda key word, which is used to define anonymous functions in place. So, all together, the code for outputing a sorted list of dictionary items by value, from high to low (i.e. in reverse) is:
sorted(my_dictionary.items(), key=lambda x: x[1], reverse=True)Style Guide
Please familiarize yourself with the PEP 8 Python Style guideLinks to an external site.. These are excellent tips for writing clear Python code and you should follow this style.
Before you submit your assignment, go through the checklist below and make sure your code conforms to the style guide.
- No unused variables or commented-out code is left in the class
- Your code is appropriately commented
- All numbers have been replaced with constants (i.e. no "magic numbers").
- Proper capitalization of any names used: snake_case for ordinary variables and functions, CapWords for class names, and ALL_CAPS for constants
- Use white space to separate different sections of your code (follow the PEP8 linter's guidance)
Using the PEP8 linter
In addition to the checklist above, use the PEP8 linter in your editor to make sure you're catching small style issues of spacing and consistency. The graders will use the PEP8 linter as a guide for enforcing PEP8 style, which should simplify the process for them and you. It's easy to track down issues with the linter and you should make sure that the linter report is completely error and warning free before submitting.
Writing testable code
Organize your code in a modular way so that functions and methods can be easily tested for correct return values. Write a test suite for each module you write, and write tests for each function or method that returns a value. Run your tests with pytest to make sure they pass.
Submitting
Upload eratosthenes.zip and ngrams.zip to Canvas.
公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Web、Linux」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh

更新日志
1c35a-于aed17-于4861b-于