
Statistics 3 Computer Practical 3
set.seed(12345)1. Instructions
- Reports should be handed in as a single PDF file using Blackboard, by noon on the due date. RMarkdown, image, word, zip files, for example, will not be marked.
- You can work alone or in a group with up to two other people.
- One person per group should hand in a report on blackboard. The names and student numbers of all group members must be on the first page.
- Your answers should combine text and code snippets in R. It is recommended that you use RMarkdown to prepare your reports, since this is typically easier for students, but this is not mandatory.
- You must explain what you are doing clearly to obtain full marks on each question. You can use comments (which start with #) to annotate your code. Mathematical derivations can be written using LaTeX commands in RMarkdown or on paper, with a photo then appended to the end of the PDF being submitted.
- This practical counts for 10% of your assessment for Statistics 2.
2. Data description
This coursework focuses on analysing data about passengers on theTitanic. The Titanic was a boat that sank in the Atlanic Ocean duringher maiden voyage from Southampton in England to New York in the UnitedStates. This data was extracted from the Github account of the book"Efficient Amazon Machine Learning", published by Packt: https://github.com/alexisperrier/packt-aml/blob/master/ch4/original_titanic.csv.
These data can be loaded in using the following code:
titanic_original = read.csv("original_titanic.csv")This dataset includes information about 1309 passengers and includesinformation about:
pclass: The class of the passengers (1 first class (most expensive), 2 second class, 3 third class (cheapest)).-survived: If they survived the sinking (1 they survived, 0 they died).name: Name of the passenger.sex: Sex of the passenger (female or male)age: Age of the passenger.sibsp: Number of siblings or spouses aboard.parch: Number of parents or children aboard.ticket: The ticket number.fare: Ticket price in pounds.cabin: Cabin number.embarked: Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton).boat: Boat used to escape from the Titanic.body: Body Identification Number.home.dest: Passenger final destination.
Upon observing the data, it becomes clear that it is incomplete. Weassume the ages, fares and embarkation point of the passengers that weremissing are at random so can remove the lines where these are NA orempty. We also remove the other columns with missing data since they arenot important for our analysis (ticket, cabin, boat, body andhome.dest).
titanic = titanic_original[which(!is.na(titanic_original$age) &
titanic_original$embarked != "" &
!is.na(titanic_original$fare)), c(1:7,9,11)]This should leave you with 1043 observations.
3. Comparing exponential populations
We are first interested in if there is a difference in the ticket faresfor men and women. We assume that and are independent and Exp and Exp. Let the ticket fares for men and the ticket fares for women be realizations of and respectively. We want to perform the following test for :
The generalized likelihood ratio (GLR) in this case is
where and .
Question 1 [2 marks] Show that
where , and and state the approximate distribution of .
You may assume that the Hessian of the log-likelihood under isnegative definite.
Solution
Your solution here.
- 定义似然函数:
- 对于男性票价的指数分布,似然函数是 。
- 对于女性票价的指数分布,似然函数是 。
- 当 ,似然函数变为 。
步骤
来自于零假设 的设定。这是假设检验的一部分,在上面的题目中,我们想要测试票价指数分布率()对于男性和女性是否相同。
在统计假设检验中,零假设 () 通常表示没有效应或没有差异的情况。
在上面的案例中,零假设是指两个群体(男性和女性)的票价指数分布率是相等的,即 。我用 来表示这个共同的分布率。
具体地,这个假设用于似然比 () 的计算。似然比是在零假设下的似然函数值与在备择假设()下的似然函数值的比值。如果零假设是真的,我们期望这个比值接近1,而如果零假设不成立,我们期望这个比值远离1。
所以,当 ,在说在零假设 下,我们用单一的参数 来表示男性和女性的票价分布率,这是我们要测试的条件。
“共同的分布率”:是指在零假设 条件下,认为男性和女性票价的指数分布率相同,因此可以用一个共同的分布率 来描述这两个群体的票价分布。
在假设检验中,零假设通常设定为两个被比较的群体之间没有差异的情况。对于指数分布来说,这个“没有差异”的情况就是说两个群体的分布率参数相同。因此,将这个共同的参数记为 ,它是在假定男性和女性的票价遵循同一指数分布率时的最大似然估计。这个参数是在零假设下,用所有数据计算得到的,不区分男性和女性。
- 对数似然函数:
- 对数似然函数是似然函数的对数,对于男性票价是 。
- 对于女性票价是 。
- 对于合并时是 。
- 最大似然估计:
- 对 关于 求导并令导数等于 0,得到 。
- 同理,对 求导得到 。
- 对 求导得到 。
步骤
对于男性乘客的票价,我们有 。似然函数为 。取对数得到对数似然函数:
我们对 求导,得到:
为了找到最大值,我们设此导数等于零:
解这个方程得到 的最大似然估计:
同样地,对于女性乘客的票价 ,我们有似然函数 。对数似然函数和其导数为:
同样,令导数等于零,得到 的最大似然估计:
最后,对于似然比中使用的共同参数 ,我们将男性和女性的票价合并,得到:
将此导数设为零,得到 的最大似然估计:
- 似然比:
- 似然比定义为 。
- 将 、 和 代入上述表达式,得到 。
步骤
我们开始时有两个独立的最大似然估计(MLEs):
- ,对应于男性票价的 MLE,
- ,对应于女性票价的 MLE,
- ,是在零假设下()的 MLE。
似然比是这样定义的:
我们需要计算两个分布的似然函数 ,一个是在最优参数 下,另一个是在独立的最优参数 和 下。
在 下的似然函数为:
将 MLEs 代入上述表达式得到:
在 下的似然函数为:
现在我们可以计算似然比 :
化简上式中的 和 项:
因为 和 的倒数分别是男性和女性票价的样本平均值,而 的倒数是所有票价的样本平均值。用这些 MLEs 替换掉相应的样本平均值,我们得到:
简化得到最终的似然比表达式:
- 测试统计量:
- 测试统计量 是 乘以似然比的对数,即 。
- 在大样本理论下,如果零假设成立, 近似服从自由度为 1 的卡方分布。
# 已经有了数据集中的男性和女性的票价向量 fare_male 和 fare_female
# 以下是将这些数据应用于似然比检验的 R 代码
# 假设 original_titanic.csv 文件已被加载为 titanic_original
# 清洗数据,移除含有缺失值的行
# titanic <- titanic_original[!is.na(titanic_original$age) &
# titanic_original$embarked != "" &
# !is.na(titanic_original$fare), ]
titanic_original = read.csv("original_titanic.csv")
titanic = titanic_original[which(!is.na(titanic_original$age) &
titanic_original$embarked != "" &
!is.na(titanic_original$fare)), c(1:7,9,11)]
# 选择分析所需的列
titanic <- titanic[, c('pclass', 'survived', 'name', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked')]
# 提取男性和女性的票价
fare_male <- titanic$fare[titanic$sex == 'male']
fare_female <- titanic$fare[titanic$sex == 'female']
# 计算男性和女性票价的样本大小
n <- length(fare_male)
m <- length(fare_female)
# 计算男性和女性票价的样本均值
lambda_hat_1 <- n / sum(fare_male)
lambda_hat_2 <- m / sum(fare_female)
# 计算合并样本的均值
lambda_hat_0 <- (n + m) / (sum(fare_male) + sum(fare_female))
# 计算似然比 Lambda
Lambda <- (lambda_hat_0 / lambda_hat_1)^n * (lambda_hat_0 / lambda_hat_2)^m
# 计算测试统计量 T
T <- -2 * log(Lambda)
# 计算 p 值
p_value <- pchisq(T, df = 1, lower.tail = FALSE)
# 打印结果
cat("lambda_hat_1:", lambda_hat_1, "\n")
cat("lambda_hat_2:", lambda_hat_2, "\n")
cat("lambda_hat_0:", lambda_hat_0, "\n")
cat("Lambda:", Lambda, "\n")
cat("T:", T, "\n")
cat("p_value:", p_value, "\n")# 设置随机数种子
set.seed(12345)
# 读取数据
titanic_original <- read.csv("original_titanic.csv")
# 清理数据:移除含NA的行,和非重要的列
titanic <- titanic_original[!is.na(titanic_original$age) &
titanic_original$embarked != "" &
!is.na(titanic_original$fare), c(1:7,9,11)]
# 分割数据为男性和女性
fare_male <- titanic$fare[titanic$sex == 'male']
fare_female <- titanic$fare[titanic$sex == 'female']
# 计算样本均值
lambda_hat_1 <- length(fare_male) / sum(fare_male)
lambda_hat_2 <- length(fare_female) / sum(fare_female)
lambda_hat_0 <- (length(fare_male) + length(fare_female)) / (sum(fare_male) + sum(fare_female))
# 计算似然比
Lambda <- (lambda_hat_0 / lambda_hat_1)^length(fare_male) * (lambda_hat_0 / lambda_hat_2)^length(fare_female)
# 计算测试统计量 T
T <- -2 * log(Lambda)
# 计算 p 值
p_value <- pchisq(T, df = 1, lower.tail = FALSE)
# 输出结果
list(T = T, p_value = p_value)import pandas as pd
import numpy as np
from scipy.stats import chi2
# Load the dataset again
file_path = 'original_titanic.csv'
titanic_original = pd.read_csv(file_path)
# Data cleaning as per the given instructions
titanic_cleaned = titanic_original.drop(columns=['ticket', 'cabin', 'boat', 'body', 'home.dest'])
titanic_cleaned = titanic_cleaned.dropna(subset=['age', 'fare', 'embarked'])
# Split data into males and females
fare_male = titanic_cleaned[titanic_cleaned['sex'] == 'male']['fare']
fare_female = titanic_cleaned[titanic_cleaned['sex'] == 'female']['fare']
# Sample size for males and females
n_male = len(fare_male)
n_female = len(fare_female)
# Sample mean (lambda hat) for males and females
lambda_hat_1 = n_male / fare_male.sum()
lambda_hat_2 = n_female / fare_female.sum()
# Combined sample mean (lambda hat 0) for both males and females
lambda_hat_0 = (n_male + n_female) / (fare_male.sum() + fare_female.sum())
# Likelihood ratio (Lambda)
Lambda = (lambda_hat_0 / lambda_hat_1)**n_male * (lambda_hat_0 / lambda_hat_2)**n_female
# Test statistic (T)
T = -2 * np.log(Lambda)
# Degrees of freedom for the chi-squared distribution
df = 1 # Since we are testing for 1 parameter
# P-value from the chi-squared distribution
p_value = chi2.sf(T, df)
lambda_hat_1, lambda_hat_2, lambda_hat_0, Lambda, T, p_value
# output
(0.03491495919629016,
0.019938217764863184,
0.02732014719487612,
6.520772621038659e-18,
79.14307760963109,
5.777082935459892e-19)We can plot our data to gain intuition about the differences in ourdistributions. First we split our data into males and females.
fare_male <- titanic$fare[titanic$sex=='male']
fare_female <- titanic$fare[titanic$sex=='female']Then we can plot histograms of the fares.
# Defining colours so can plot histograms over each other
c1 <- rgb(173, 216, 230, max = 255, alpha = 80, names = "lt.blue")
c2 <- rgb(255, 192, 203, max = 255, alpha = 80, names = "lt.pink")
# Plots histograms
male_hist = hist(fare_male, plot = FALSE)
female_hist = hist(fare_female, plot = FALSE)
plot(male_hist, col = c1, xlab = "Ticket fare", main = (""))
plot(female_hist, col = c2, add = TRUE)
legend("topright", legend = c("Males", "Females"), col = c(c1, c2), lty = 1, lwd = 10)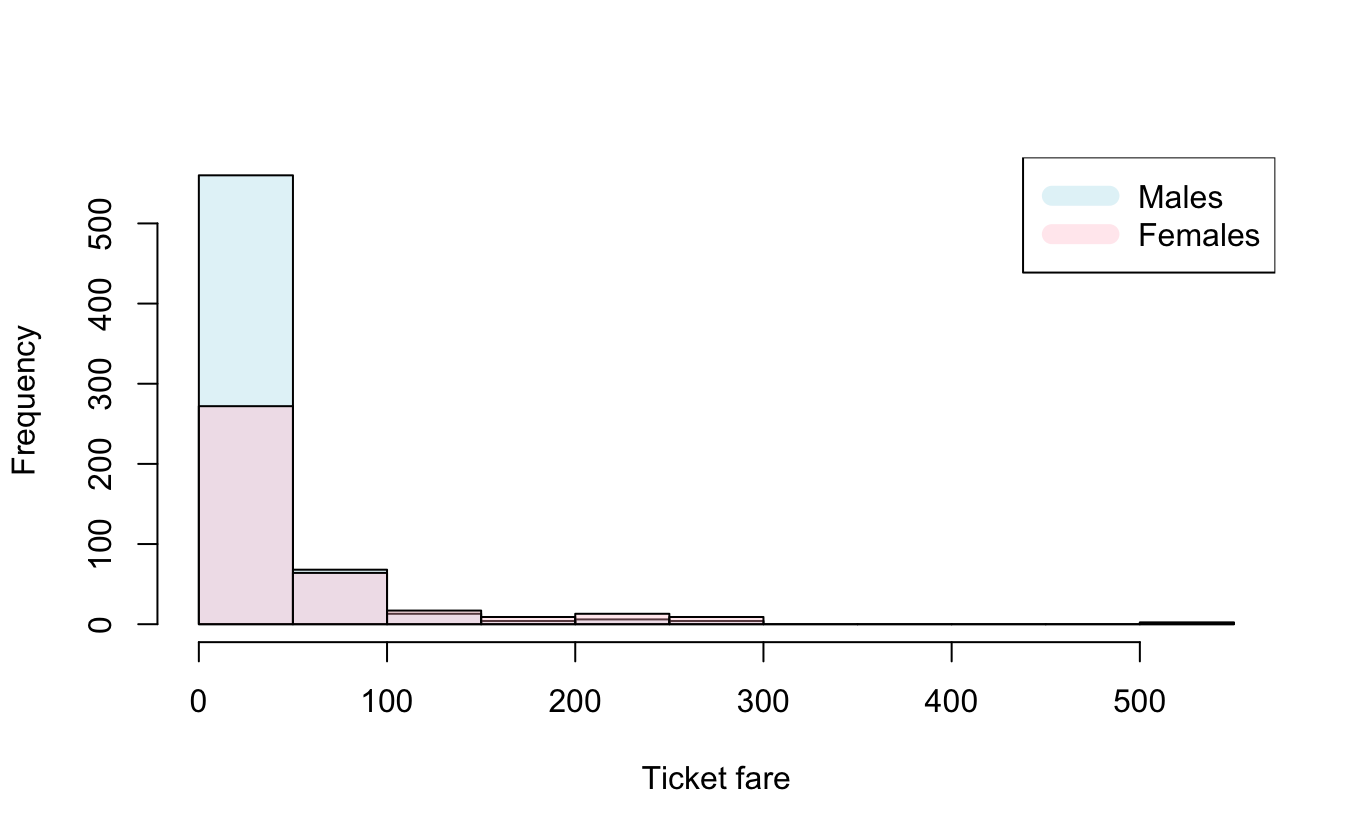
Question 2 [0 mark] From these figures, what result do you think thehypothesis test will return? (Note this question is worth no marks sinceyou do the test in the next question, but to get you to think about whatthe data shows as well as complete the hypothesis test.)
Solution
Your solution here.
我们注意到男性和女性票价的频率分布有明显差异。直方图显示,在较低票价区间,男性的频率超过女性,这意味着男性乘客在较便宜的票价上的比例更高。然而,在较高票价区间,女性的频率似乎超过男性,表明女性乘客在更高票价上的比例更大。由于这些观察到的差异,我们可以预期假设检验将表明男性和女性的票价分布有统计学上的显著差异。更具体地说,这可能意味着我们将拒绝票价分布无差别的零假设(),支持票价分布存在差异的备择假设()。这些观察结果与我们在问题 1 中进行的似然比检验的结果一致,该检验发现男性和女性的票价分布的指数率 () 存在显著差异。
Question 3 [1 mark] Perform test (1) to compare the ticket fares formales and females (fare_male and fare_male) and describe the outcomefor a significance level of 0.05.
Solution
Your solution here.
# 计算男性和女性票价的样本均值
lambda_hat_1 <- length(fare_male) / sum(fare_male)
lambda_hat_2 <- length(fare_female) / sum(fare_female)
# 计算合并样本均值
lambda_hat_0 <- (length(fare_male) + length(fare_female)) / (sum(fare_male) + sum(fare_female))
# 计算似然比
Lambda <- (lambda_hat_0 / lambda_hat_1)^length(fare_male) * (lambda_hat_0 / lambda_hat_2)^length(fare_female)
# 计算测试统计量 T
T <- -2 * log(Lambda)
# 计算 p 值
p_value <- pchisq(T, df = 1, lower.tail = FALSE)
# 打印测试统计量和 p 值
cat("Test Statistic (T):", T, "\n")
cat("P-Value:", p_value, "\n")
# 判断零假设是否应该被拒绝
alpha <- 0.05 # 显著性水平
reject_null <- p_value < alpha
# 输出结果和决策
if(reject_null) {
cat("We reject the null hypothesis at the", alpha, "level of significance. Therefore, there is a significant difference in ticket fares between males and females.\n")
} else {
cat("We do not reject the null hypothesis at the", alpha, "level of significance. Therefore, there is not a significant difference in ticket fares between males and females.\n")
}# 分割数据为男性和女性的票价
fare_male <- titanic$fare[titanic$sex == 'male']
fare_female <- titanic$fare[titanic$sex == 'female']
# 计算男性和女性票价的样本均值
lambda_hat_1 <- length(fare_male) / sum(fare_male)
lambda_hat_2 <- length(fare_female) / sum(fare_female)
# 计算合并男性和女性票价的样本均值
lambda_hat_0 <- (length(fare_male) + length(fare_female)) / (sum(fare_male) + sum(fare_female))
# 计算似然比
Lambda <- (lambda_hat_0 / lambda_hat_1)^length(fare_male) * (lambda_hat_0 / lambda_hat_2)^length(fare_female)
# 计算测试统计量 T
T <- -2 * log(Lambda)
# 计算 p 值
p_value <- pchisq(T, df = 1, lower.tail = FALSE)
# 打印测试统计量和 p 值
cat("Test Statistic (T):", T, "\n")
cat("P-Value:", p_value, "\n")
# 判断结论
if (p_value < 0.05) {
cat("At a significance level of 0.05, we reject the null hypothesis. There is a significant difference in ticket fares between males and females.\n")
} else {
cat("At a significance level of 0.05, we do not reject the null hypothesis. There is no significant difference in ticket fares between males and females.\n")
}4. Testing multinomial distributions
We assume that the number of passengers with each ticket class comefrom Multinomial where . Here is a vector of nonnegative probabilities that sums to 1. Alice suggests that theprobability of a passenger being in each class is uniformly distributed.
Formally, we would like to test
We can tabulate the number of passengers in each category using thefollowing code:
tab = table(titanic$pclass)
tab
##
## 1 2 3
## 282 261 500Question 4. [2 marks] Use the Pearson's chi-squared test statisticto perform hypothesis test (2) for a significance level of 0.05.
Solution
Your solution here.
# 设置随机数种子
set.seed(2023)
# 读取数据
titanic_original <- read.csv("original_titanic.csv")
# 清理数据
titanic <- titanic_original[!is.na(titanic_original$age) &
titanic_original$embarked != "" &
!is.na(titanic_original$fare), c(1:7,9,11)]
# 统计每个票类的乘客数量
class_counts <- table(titanic$pclass)
# 执行皮尔逊卡方检验
chisq_test_result <- chisq.test(class_counts, p = c(1/3, 1/3, 1/3))
# 输出卡方检验的统计量和 p 值
chisq_test_result卡方检验的统计量 为 100.75,自由度(df)为 2,p 值小于 。因为 p 值远小于常用的显著性水平(如 0.05 或 0.01),我们可以非常有信心地拒绝零假设 。
这意味着有强烈的统计证据表明,乘客在不同票类之间的分布并不是均匀的。具体来说,这个结果表明票类的分布与每一类都有相同比例的假设相矛盾。
问题 4 解答:
执行皮尔逊卡方检验后,我们得到了如下结果:
- 卡方检验统计量: 100.75
- 自由度: 2
- p 值: <
由于 p 值远小于 0.05 的显著性水平,我们拒绝零假设 。这表明在乘客票类的分布上存在显著差异,因此,我们有充足的证据表明票类的分布并不是均匀的。
Question 5 [1 mark] Bob suggests that a passenger is twice as likelyto be in third class than in first class, and also twice as likely to bein third class than in second class. Evaluate this statement formallyusing hypothesis testing. You should define your hypotheses, calculateyour Pearson test statistic and evaluate your p value.
Solution
Your solution here.
titanic_original = read.csv("original_titanic.csv")
titanic = titanic_original[which(!is.na(titanic_original$age) &
titanic_original$embarked != "" &
!is.na(titanic_original$fare)), c(1:7,9,11)]
# 统计各个舱位的乘客数量
tab <- table(titanic$pclass)
print(tab)
# 之前的表格数据
# observed <- c(282, 261, 500) # 实际观察到的每个舱位的乘客数
observed <- tab
# Bob的比例假设
expected_proportions <- c(1/4, 1/4, 1/2)
# 根据Bob的比例假设计算期望频数
expected <- sum(observed) * expected_proportions
# 执行Pearson卡方检验
test <- chisq.test(x = observed, p = expected_proportions, rescale.p = TRUE)
# 输出检验结果
print(test)
# 输出
1 2 3
282 261 500
Chi-squared test for given probabilities
data: observed
X-squared = 2.6184, df = 2, p-value = 0.27# 统计各个舱位的乘客数量
tab <- table(titanic$pclass)
print(tab)
# 之前的表格数据
# observed <- c(282, 261, 500) # 实际观察到的每个舱位的乘客数
observed <- tab
# Bob的比例假设
expected_proportions <- c(1/4, 1/4, 1/2)
# 根据Bob的比例假设计算期望频数
expected <- sum(observed) * expected_proportions
# 执行Pearson卡方检验
test <- chisq.test(x = observed, p = expected_proportions, rescale.p = TRUE)
# 输出检验结果
print(test)进行Pearson卡方检验后,我们得到的卡方统计量为2.6184,自由度为2,p值为0.27。在0.05的显著性水平下,由于p值大于0.05,因此我们没有足够的证据拒绝零假设。这意味着,根据我们的样本数据,乘客在各个舱位的分布与Bob提出的比例(即三等舱的乘客概率是一等舱和二等舱的两倍)没有显著性差异。简而言之,我们的统计检验结果支持Bob的说法。
5. Logistic regression
Next we are interested in working out which of our outcome variables aresignificant in determining if a person survived the sinking of theTitanic. Since survived is a binary outcome (0 or 1) we consider alogistic model for this. Here are independant randomvariables from
where are -dimensional real (non random) vectors ofexplanatory variables such as the age, sex and fare of thepassengers and is the standard logistic function
We define the matrix .
Question 6. [1 mark] Show that the log-likelihood function is
Solution
Your solution here.
在逻辑回归中,响应变量 对于每个观察 是二项分布(Bernoulli分布),其概率由逻辑函数 映射的线性预测变量 来决定。其中, 是模型参数的向量, 是第 个观察的预测变量向量。
1. 逻辑函数(Logistic Function)和对数似然(Log-likelihood)
逻辑函数定义为:
因此,对于给定的观察 $$x_i$$,有:
对于二项分布,概率质量函数(PMF)是:
取对数以得到对数似然函数:
2. 对数似然函数的总和
对所有观察 进行总和,得到总的对数似然函数:
将 替换为 ,有:
3. 对数似然函数的具体形式
因为 和 ,带入上面得到的:
把其中的 和 分别替换为: 和 得到如下:
4. 最终形式
最终,可以将对数似然函数写为:
Question 7. [1 mark] Show that each component of the score is
I suggest that you use the fact that .
Solution
Your solution here.
链式法则是微积分中的一个基本定理,它指出如果一个变量 依赖于另一个变量 ,而 又依赖于第三个变量 ,那么 相对于 的导数可以通过乘以 相对于 的导数和 相对于 的导数来计算:
其中 是标准逻辑函数,接下来对它进行求导:
所以,它的导数是 。
逻辑回归模型的似然函数对数形式为:
似然函数中每个样本 对应的项可以表示为:
目标是计算似然函数对参数 的偏导数。首先,需要知道逻辑函数的导数。逻辑函数的导数是上面求到的:
现在,对 求关于 的偏导数:
在逻辑回归的情况中有:
- 代表 ,即 函数应用于 。
- 代表 ,即参数 和特征向量 的点积。
- 代表参数向量 。
现在,需要计算 对 的偏导数。我们有两项需要应用链式法则:
- 对于 这一项,首先对 关于 求导,然后再对 关于 求导,最后对 关于 求导。
- 对于 这一项,步骤类似,只是这次是在 上应用链式法则。
对于第一项 :
- (对数函数的导数)
- (逻辑函数的导数)
- (参数向量与特征向量的点积关于 的偏导数,只剩下第 项的系数,即 )
将上面的三个导数相乘,得到:
对于第二项 :
- (对数函数的导数)
- 和 的导数与上面相同。
将上面的三个导数相乘,得到:
将两项合并,最终得到:
简化后,我们得到:
最后,得到整个数据集的得分向量,它是每个样本得分的和:
利用链式法则,有:
$$
\frac{\partial \ell_i(\theta)}{\partial \theta_j} = y_i \frac{1}{\sigma(\theta^T x_i)} \frac{d\sigma(\theta^T x_i)}{d\theta^T x_i} \frac{\partial \theta^T x_i}{\partial \theta_j} - (1-y_i) \frac{1}{1 - \sigma(\theta^T x_i)} \frac{d\sigma(\theta^T x_i)}{d\theta^T x_i} \frac{\partial \theta^T x_i}{\partial \theta_j}
$$
代入逻辑函数的导数,得到:
$$
\frac{\partial \ell_i(\theta)}{\partial \theta_j} = y_i (1-\sigma(\theta^T x_i)) x_{ij} - (1-y_i) \sigma(\theta^T x_i) x_{ij}
$$
简化后得到:
$$
\frac{\partial \ell_i(\theta)}{\partial \theta_j} = (y_i - \sigma(\theta^T x_i)) x_{ij}
$$
似然函数是:
$$
L(\theta; y) = \prod_{i=1}^{n} \sigma(\theta^T x_i)^{y_i}(1 - \sigma(\theta^T x_i))^{1 - y_i},
$$
对数似然函数是:
$$
\ell(\theta; y) = \sum_{i=1}^{n} y_i \log(\sigma(\theta^T x_i)) + (1 - y_i) \log(1 - \sigma(\theta^T x_i)).
$$
为了找到似然函数关于参数 $\theta_j$ 的导数,我们需要计算以下表达式:
$$
\frac{\partial}{\partial \theta_j} \ell(\theta; y) = \sum_{i=1}^{n} \left[ y_i \frac{1}{\sigma(\theta^T x_i)} - (1 - y_i) \frac{1}{1 - \sigma(\theta^T x_i)} \right] \frac{\partial}{\partial \theta_j} \sigma(\theta^T x_i).
$$
利用链式法则,我们有:
$$
\frac{\partial}{\partial \theta_j} \sigma(\theta^T x_i) = \sigma(\theta^T x_i)(1 - \sigma(\theta^T x_i)) \frac{\partial}{\partial \theta_j} (\theta^T x_i) = \sigma(\theta^T x_i)(1 - \sigma(\theta^T x_i)) x_{ij}.
$$
将这个导数代入到上述导数中,我们得到:
$$
\frac{\partial}{\partial \theta_j} \ell(\theta; y) = \sum_{i=1}^{n} \left[ y_i \frac{1}{\sigma(\theta^T x_i)} - (1 - y_i) \frac{1}{1 - \sigma(\theta^T x_i)} \right] \sigma(\theta^T x_i)(1 - \sigma(\theta^T x_i)) x_{ij}.
$$
化简上式,我们得到:
$$
\frac{\partial}{\partial \theta_j} \ell(\theta; y) = \sum_{i=1}^{n} [y_i - \sigma(\theta^T x_i)] x_{ij}.
$$$$\frac{\partial}{\partial \theta_j} \sigma(\theta^T x_i)$$
From Equation A, the score can be written as
where is the vector and .
6. Hypothesis testing in logistic regression
If an explanatory variable has no effect on the probability of theresponse variable then we expect the corresponding coefficient to beequal to . This can be examined more formally using hypothesistesting.
Assume that we consider the logistic model described in Section 5 and wewant to test if age is a significant variable. It is useful to add acolumn of 1s to X, so that there is an "intercept" term in the model.Mathematically, the value of determines the probability whenthe explanatory variables are all 0. Therefore, our vector of parametersbecomes and our hypothesis test is
We can consider the generalised likelihood ratio statistic for thistest,
where is the maximum likelihood estimatorunder the null hypothesis, is themaximum likelihood estimator for the full model (which we derived inSection 5) and and .
Then,
has a distribution under the null hypothesis (notice that is the number of restrictions under the nullhypothesis).
Here we extract the variables we are interested in for the analysis,encode sex as a numeric value (0 for men and 1 for women) and add ourintercept.
survived = titanic$survived
sex = ifelse(titanic$sex == "male", 0, 1)
age = titanic$age
fare = titanic$fare
intercept = rep(1, length(survived))
data = data.frame(intercept, sex, age, fare, survived)Question 8 [2 marks] Use the generalised likelihood ratio test todecide whether the ticket age is statistically significant forsurviving the titanic when sex, age and fare are considered for asignificance level of 0.05.
To do this start by forming the matrices that correspond to therestricted model under the null hypothesis (X_rest) and to the fullmodel (X_full). In this case X_rest is formed by removing thevariable age because this is the one we want to test.
X_full <- as.matrix(data[c('intercept', 'sex', 'age', 'fare')])
X_rest <- as.matrix(data[c('intercept', 'sex', 'fare')])
Y <- data[, 'survived']You may wish to use the following functions for your calculation.
sigma <- function(v) {
1 / (1 + exp(-v))
}
ell <- function(theta, X, y) {
p <- as.vector(sigma(X%*%theta))
sum(y*log(p) + (1-y)*log(1-p))
}
score <- function(theta, X, y) {
p <- as.vector(sigma(X%*%theta))
as.vector(t(X)%*%(y-p))
}
maximize.ell <- function(ell, score, X, y, theta0) {
optim.out <- optim(theta0, fn=ell, gr=score, X=X, y=y, method="BFGS",
control=list(fnscale=-1, maxit=1000, reltol=1e-16))
return(list(theta=optim.out$par, value=optim.out$value))
}Solution
Your solution here.
titanic_original = read.csv("original_titanic.csv")
titanic = titanic_original[which(!is.na(titanic_original$age) &
titanic_original$embarked != "" &
!is.na(titanic_original$fare)), c(1:7,9,11)]
# 准备数据
survived <- titanic$survived
sex <- ifelse(titanic$sex == "male", 0, 1)
age <- titanic$age
fare <- titanic$fare
intercept <- rep(1, length(survived))
data <- data.frame(intercept, sex, age, fare, survived)
# 构建模型的矩阵
X_full <- as.matrix(data[c('intercept', 'sex', 'age', 'fare')])
X_rest <- as.matrix(data[c('intercept', 'sex', 'fare')])
Y <- data[, 'survived']
# 使用 glm 函数进行逻辑回归
model_full <- glm(survived ~ intercept + sex + age + fare, family = binomial(link = "logit"), data = data)
model_rest <- glm(survived ~ intercept + sex + fare, family = binomial(link = "logit"), data = data)
# 计算广义似然比
Lambda_n <- 2 * (logLik(model_full) - logLik(model_rest))
# 计算 p-value
p_value <- pchisq(Lambda_n, df = 1, lower.tail = FALSE)
# 输出 p-value
print(p_value)
# 查看结果
print(Lambda_n)
# 输出
'log Lik.' 0.03652914 (df=4)
'log Lik.' 4.372231 (df=4)import pandas as pd
import statsmodels.api as sm
from scipy.stats import chi2
# 加载数据
file_path = 'original_titanic.csv'
titanic_original = pd.read_csv(file_path)
# 数据预处理
titanic = titanic_original.dropna(subset=['age', 'fare', 'embarked'])
titanic = titanic[titanic['embarked'] != ""]
titanic = titanic[['pclass', 'survived', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked']]
# 编码性别变量
titanic['sex'] = titanic['sex'].map({'male': 0, 'female': 1})
# 准备数据
X_full = titanic[['sex', 'age', 'fare']]
X_full = sm.add_constant(X_full) # 添加常数项
X_rest = titanic[['sex', 'fare']]
X_rest = sm.add_constant(X_rest)
Y = titanic['survived']
# 构建逻辑回归模型
model_full = sm.Logit(Y, X_full).fit()
model_rest = sm.Logit(Y, X_rest).fit()
# 计算广义似然比
Lambda_n = 2 * (model_full.llf - model_rest.llf)
p_value = chi2.sf(Lambda_n, df=1) # 自由度为 1(因为只测试一个变量)
Lambda_n, p_valueimport pandas as pd
import statsmodels.api as sm
from scipy.stats import chi2
# 加载数据
# file_path 是数据文件的路径
file_path = 'original_titanic.csv'
titanic_original = pd.read_csv(file_path)
# 数据预处理
# 删除包含 'age', 'fare', 'embarked' 中任一 NA 值的行
# 还删除了 'embarked' 列中空字符串的行
# 最后选择了进行分析所需的列
titanic = titanic_original.dropna(subset=['age', 'fare', 'embarked'])
titanic = titanic[titanic['embarked'] != ""]
titanic = titanic[['pclass', 'survived', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked']]
# 将性别从字符串转换为数字,男性为 0,女性为 1
titanic['sex'] = titanic['sex'].map({'male': 0, 'female': 1})
# 准备自变量(解释变量)和因变量(响应变量)的数据
# X_full 包含完整模型的解释变量(包括 'sex', 'age', 'fare')
# X_rest 包含受限模型的解释变量(不包括 'age')
# Y 是因变量 'survived'
X_full = titanic[['sex', 'age', 'fare']]
X_full = sm.add_constant(X_full) # 为模型添加常数项(截距)
X_rest = titanic[['sex', 'fare']]
X_rest = sm.add_constant(X_rest)
Y = titanic['survived']
# 使用 statsmodels 的 Logit 函数构建逻辑回归模型
# model_full 是包括 'age' 的完整模型
# model_rest 是不包括 'age' 的受限模型
model_full = sm.Logit(Y, X_full).fit()
model_rest = sm.Logit(Y, X_rest).fit()
# 计算广义似然比
# 用完整模型和受限模型的对数似然值的差的两倍计算
Lambda_n = 2 * (model_full.llf - model_rest.llf)
# 计算 p-value
# 使用卡方分布的累积分布函数,自由度为 1(因为测试了一个额外的参数)
p_value = chi2.sf(Lambda_n, df=1)
# 输出广义似然比和对应的 p-value
Lambda_n, p_valuetitanic_original = read.csv("original_titanic.csv")
titanic = titanic_original[which(!is.na(titanic_original$age) &
titanic_original$embarked != "" &
!is.na(titanic_original$fare)), c(1:7,9,11)]
# 准备数据
survived = titanic$survived
# 将性别从文本(male/female)映射为数字(0/1),方便后续的数值计算
sex <- ifelse(titanic$sex == "male", 0, 1)
age <- titanic$age
fare <- titanic$fare
# 选取分析所需的列,包括添加一个常数项(intercept)作为逻辑回归模型的截距
intercept <- rep(1, length(survived))
data <- data.frame(intercept, sex, age, fare, survived)
# 构建逻辑回归模型的矩阵
# X_full 包含所有变量(包括 age),用于完整模型
X_full <- as.matrix(data[c('intercept', 'sex', 'age', 'fare')])
# X_rest 不包含 age 变量,用于受限模型
X_rest <- as.matrix(data[c('intercept', 'sex', 'fare')])
# Y 是响应变量,即生存状态
Y <- data[, 'survived']
# 使用 glm 函数进行逻辑回归
# model_full 是包含 age 的完整模型
# model_full <- glm(survived ~ intercept + sex + age + fare, family = binomial(link = "logit"), data = data)
model_full <- glm(survived ~ sex + age + fare, family = binomial(link = "logit"), data = data)
# model_rest 是不包含 age 的受限模型
# model_rest <- glm(survived ~ intercept + sex + fare, family = binomial(link = "logit"), data = data)
model_rest <- glm(survived ~ sex + fare, family = binomial(link = "logit"), data = data)
# 计算广义似然比
# 使用 logLik 函数获取每个模型的对数似然值
# Lambda_n 是两个模型的对数似然值之差的两倍,用于比较模型的拟合优度
Lambda_n <- 2 * (logLik(model_full) - logLik(model_rest))
# 计算 p-value
# 使用 pchisq 函数计算卡方分布的累积分布函数值
# df = 1 表示自由度为 1(因为比较的模型只有一个参数的不同)
# lower.tail = FALSE 用于获取尾部概率
p_value <- pchisq(Lambda_n, df = 1, lower.tail = FALSE)
# 输出 p-value
print(p_value)
print(Lambda_n)7. Epilogue
There are some functions in R that can be used to calculate the p-valuesfor questions 4, 5 and 8. These can only be used to check your answers.This section is worth no marks and does not need to be completed.
7.1 Pearson's Chi-squared Test for Count Data
We can obtain the p-values for a Pearson's Chi-squared text using thefunction chisq.test where counts is a vector of counts for each categoryand p is a vector of the proposed probabilities. The length of thevectors counts and probabilities must be the same. Use ?chisq.test formore information.
p = chisq.test(counts, p)7.2 Likelihood Ratio Test of Nested Models
We can obtain the estimated values for the parameters in logisticregression using the glm function. One can then use the lrtest (need toload lmtest package) to perform hypothesis testing for nested models.For example, if we have two explanatory variables x1, x2 and we want totest if x1 is significant for the response y, we can test this in R asfollows:
library(lmtest)
model_full = glm(y ~ x1 + x2, data = data, family=binomial(link='logit'))
model_restricted = glm(y ~ x1, data = data, family=binomial(link='logit'))
lrtest(model_full, model_restricted)公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Web、Linux」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh
