
Statistics 2 Computer Practical 2
1. Instructions
- Reports should be handed in as a single PDF file using Blackboard, by noon on the due date. RMarkdown, image, word, zip files, for example, will not be marked.
- You can work alone or in a group with up to two other people.
- One person per group should hand in a report. The names and student numbers of all group members must be on the first page.
- Your answers should combine text and code snippets in R. It is recommended that you use RMarkdown to prepare your reports, since this is typically easier for students, but this is not mandatory.
- You must explain what you are doing clearly to obtain full marks on each question. You can use comments (which start with #) to annotate your code. Mathematical derivations can be written using LaTeX commands in RMarkdown or on paper, with a photo then appended to the end of the PDF being submitted.
- This practical counts for 10% of your assessment for Statistics 2.
2. Populations of world cities
The data is population sizes of the world's cities and towns, according to the World Cities Database.
To load the raw data and remove missing (NA) entries, we run the following commands.
raw.data <- read.csv("worldcities.csv")
raw.populations <- raw.data$population
populations <- raw.populations[!is.na(raw.populations)]
sum(populations)
## [1] 5076372338There are around 5.076 billion people counted, which is off by about 3 billion since there are about 8 billion people in the world. In any case we can try to understand the distribution of population sizes for the data we do have. Now we remove populations under 10000.
populations <- populations[populations>=10000]
length(populations)
## [1] 38615sum(populations)
## [1] 5030436026We can see that removing the smaller towns still leaves us considering around 5.03 billion people, and we have observations of population sizes from 38615 cities.
To finish cleaning the data, we now divide populations by 10000 and subtract 1 so that the values start from 0 and we essentially counting population sizes in units of 10000.
populations <- populations/10000-13. Visualizing the data
The data have a large range, and so visualizing a density estimate on the original scale is not very informative. Instead, and purely for the purpose of visualization, we can plot the density of the logarithms of the observations.
plot(density(log(populations)))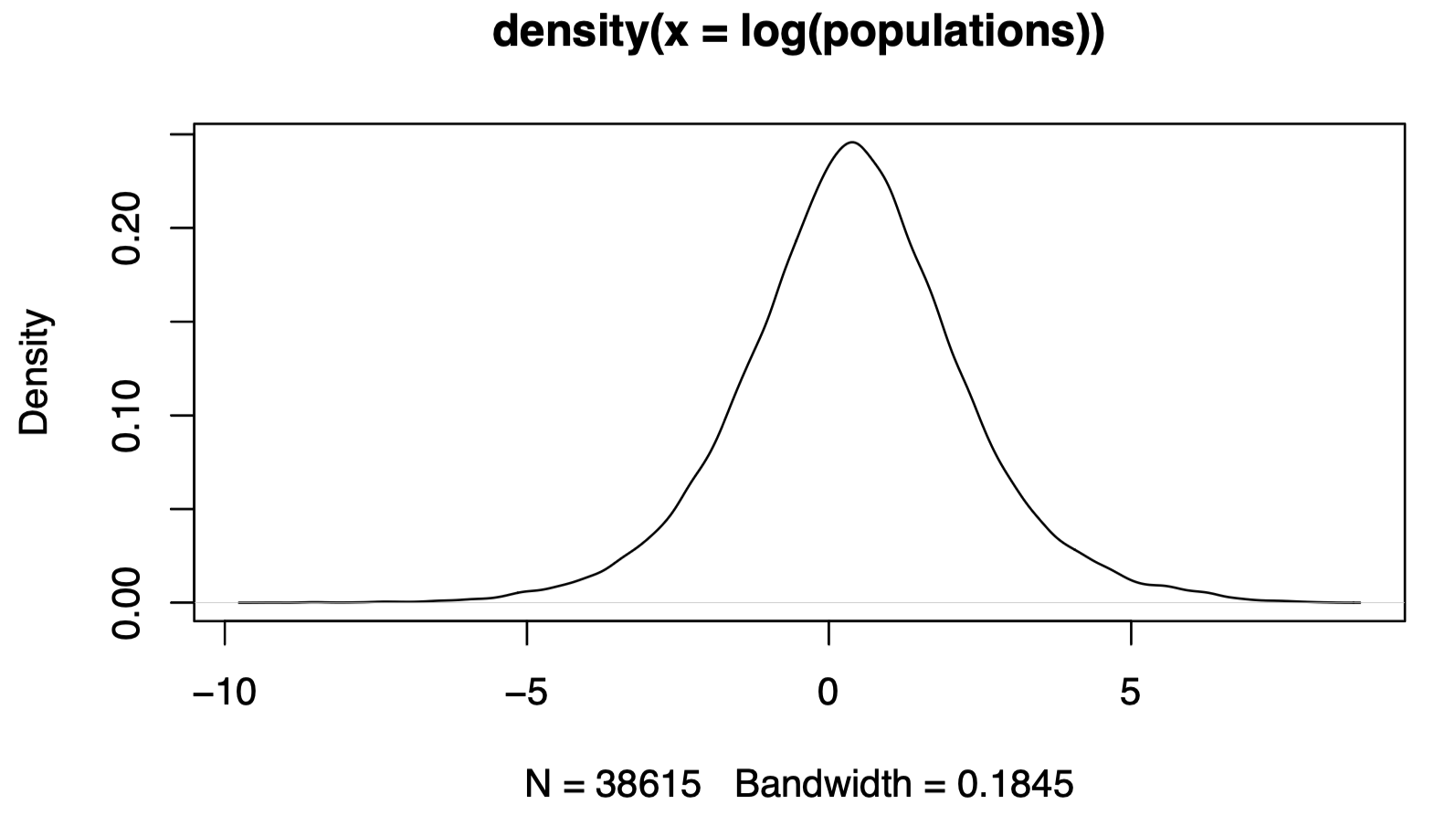
4. Model
We will model populations as realizations of independent and identically distributed random variables from a member of the family of distributions with density
with two-dimensional statistical parameter . This is a regular statistical model.
This PDF is non-negative and integrates to because for any and, we have
We shall write to mean that is a random variable with density (1). To simulate a vector of realizations of independent random variables, we canuse the following code. If you are interested, this is an application of inverse transform sampling.
rdist <- function(n, a, b) {
u <- runif(n)
(u^(-1/a)-1)*b
}To evaluate the PDF at each point in a vector, we can use the following code. If the log argument is true then the log density is returned rather than the density, as is usual in R code.
ddist <- function(xs,a,b,log=FALSE) {
if (log) {
log(a) + a*log(b) - (a+1)*log(xs+b)
} else {
a*b^a/(xs+b)^(a+1)
}
}5. Estimation
Using (2) it is quite easy to show that the first and second moments of are
and
Question 1. [2 marks] Derive the method of moments estimators of and . Report the estimates for this dataset.
I suggest that you write a function mom.estimate that takes as input some data and returns a vector containing the estimated values of and . For example, something like this:
mom.estimate <- function(xs) {
## your code here
a.hat <- 0 # obviously wrong
b.hat <- 0 # obviously wrong
c(a.hat, b.hat)
}--- Solution ---
Your solution here.
--- End of Solution ---
You can check if your estimate makes sense by considering a large dataset with known parameters.
fake.data <- rdist(100000, 10, 20)
fake.theta.hat <- mom.estimate(fake.data)
fake.theta.hat
## [1] 0 0Having computed the method of moments estimate for the populations data, we can visualize the fitted density on the log scale. Even if you have computed the estimates properly, the fit should not look great. As you go through the rest of the practical, you may be able to guess why this is.
On the logarithmic scale, we can plot the fitted density by using the transformed PDF suggested by Exercise 2.1 of the lecture notes, i.e. if and is the PDF for then the PDF for is
theta.mom <- mom.estimate(populations)
plot(density(log(populations)),ylim=c(0,0.3))
zs <- seq(-10,10,0.01)
lines(zs,ddist(exp(zs),theta.mom[1],theta.mom[2])*exp(zs),col="red")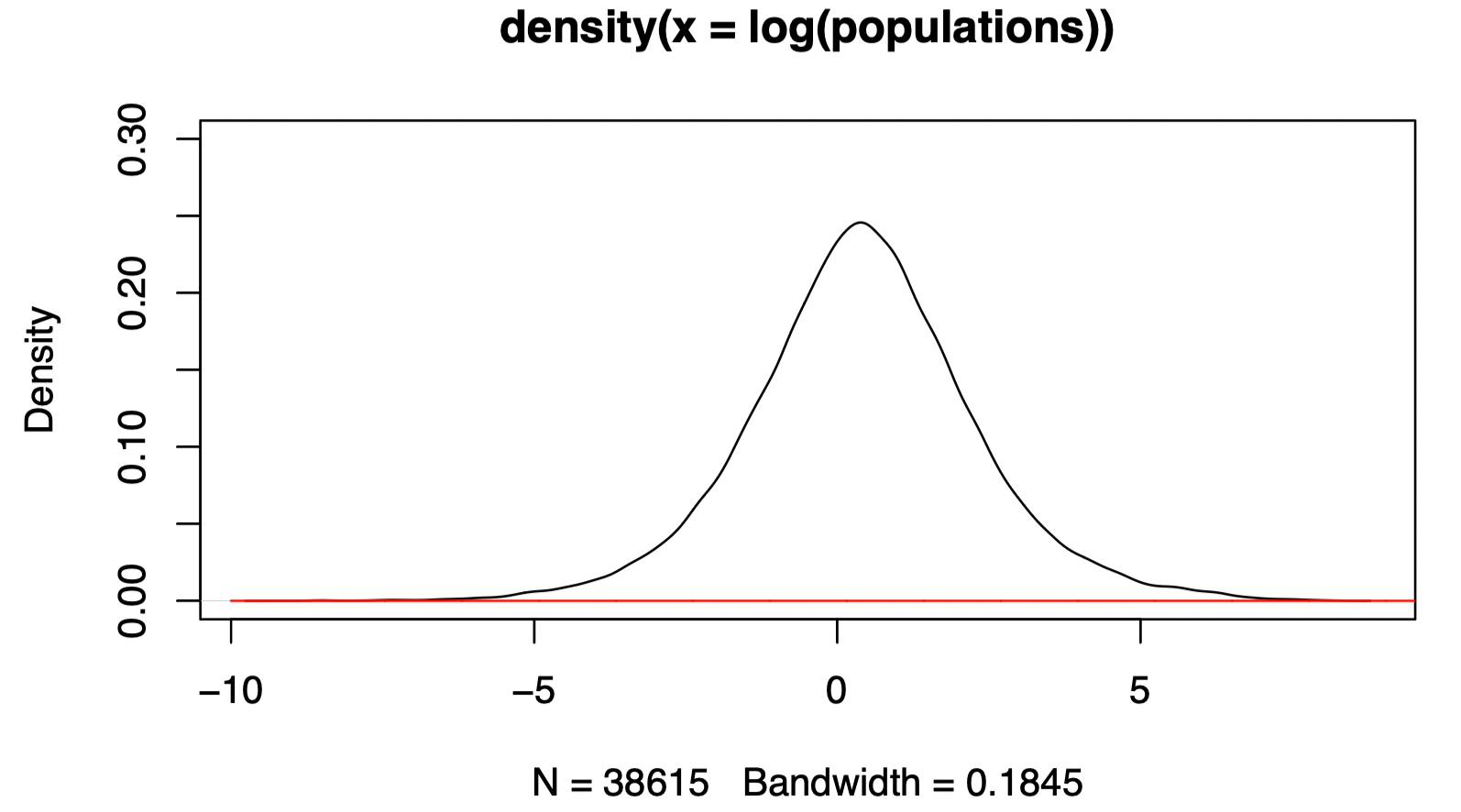
Question 2. [2 marks] Show that for fixed , the log-likelihood is maximized by taking
--- Solution ---
Your solution here.
--- End of Solution ---
The log-likelihood cannot be maximized analytically, so we will use a numerical optimization procedure. In particular, we will make use of thefact that we can maximize a function of only since we know that for any the maximizing is given by .
ml.estimate <- function(xs) {
n <- length(xs)
get.a <- function(b) {
n/(sum(log(xs+b))-n*log(b))
}
ell <- function(b) {
lb <- log(b)
a <- get.a(b)
la <- log(a)
n*la+a*n*lb-(a+1)*sum(log(xs+b))
}
out <- optim(1, ell, control = list(fnscale=-1), method="Brent", lower=0, upper=100)
c(get.a(out$par),out$par)
}Now we can visualize the fitted density using the ML estimate. It looks pretty good!
theta.ml <- ml.estimate(populations)
plot(density(log(populations)))
zs <- seq(-10,10,0.01)
lines(zs,ddist(exp(zs),theta.ml[1],theta.ml[2])*exp(zs),col="red")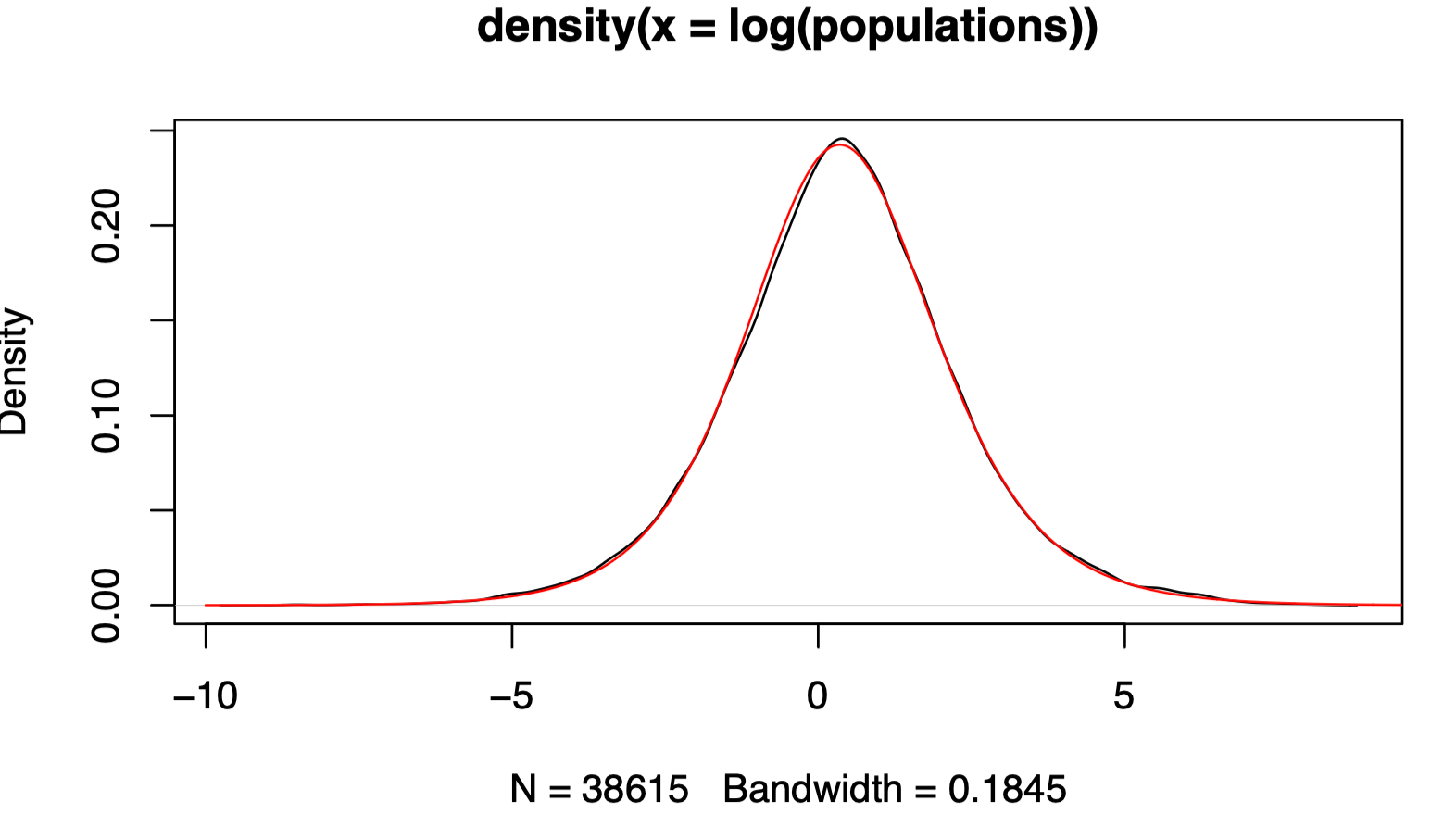
6. Confidence Intervals
In lectures we have seen that for regular statistical models with a one-dimensional parameter , the ML estimator is asymptotically normal with
This convergence in distribution justifies the construction of Wald confidence intervals for .
In this computer practical, the statistical model has a -dimensional parameter. Under appropriate regularity assumptions, the ML estimator is asymptotically (multivariate) normal in the sense that
where is the Fisher information matrix
and the expectation is taken element-wise. That is, the th entry of is the negative expectation of the corresponding th second order partial derivative of the log-likelihood associated with 1 observation. Notice that is a two-dimensional normal random vector with mean and variance-covariance matrix .
One can deduce from this multivariate asymptotic normality that for ,
which we can rewrite as
where denotes the th component of and denotes the th component of .
Notice that is the th diagonal entry of the inverse of the Fisher information matrix, and is not in general equal to , the inverse of the th diagonal entry of the Fisher information .In R you can compute numerically the inverse of a matrix using the solve command.
As in the one-dimensional parameter case, one can replace with if is a consistent sequence of estimators of to obtain
Question 3. [2 marks] Show that the Fisher information for one observation is
and compute the Fisher information for .
I recommend that you write a function to compute the Fisher information for any value of , structured like this:
info <- function(theta) {
a <- theta[1]
b <- theta[2]
# your code
i11 <- 1 # obviously wrong
i12 <- 0 # obviously wrong
i21 <- 0 # obviously wrong
i22 <- 1 # obviously wrong
mtx <- matrix(c(i11,i21,i12,i22),2,2)
return(mtx)
}--- Solution ---
Your solution here.
--- End of Solution ---
Question 4. [2 marks] Compute and report the endpoints of the observed 98% Wald confidence intervals for and individually.
I recommend that you write a function that computes the observed confidence intervals' end points, which should call the info function.
compute.CI.endpoints <- function(xs,alpha) {
# your code
L.a <- 0 # obviously wrong
U.a <- 1 # obviously wrong
L.b <- 0 # obviously wrong
U.b <- 1 # obviously wrong
list(a=c(L.a,U.a),b=c(L.b,U.b))
}You may find it helpful to know that you can use the solve function to compute the inverse of a matrix.
--- Solution ---
Your solution here.
--- End of Solution ---
Question 5. [2 marks] Using many simulations, approximate the coverage of the asymptotically exact confidence intervals corresponding to your answer to Question 3, when and , for . Comment on the coverageof the confidence intervals and explain in words why the approximate coverage you report is approximate.
I recommend that you write a function
approximate.coverage <- function(n,a,b,alpha,trials) {
# your code
coverage.a <- 0 # hopefully wrong
coverage.b <- 0 # hopefully wrong
c(coverage.a,coverage.b)
}--- Solution ---
Your solution here.
--- End of Solution ---
7. Epilogue
This computer practical involves a slightly more complicated distribution for the data than the standard distributions withone-dimensional statistical parameters typically used for communicating the basic ideas. The use of more sophisticated models is important when applying statistical ideas to real world data. As in this case, it is not uncommon that the ML estimate has to be computed numerically.Similarly, most real-world models have several statistical parameters,and the use of two parameters here is therefore a gentle introduction to what you would do in more realistic statistical analyses.
# 最大似然估计函数
# 此函数通过优化过程估计参数a和b的值
ml.estimate <- function(xs) {
n <- length(xs) # 获取样本大小
get.a <- function(b) n / (sum(log(xs + b)) - n * log(b)) # 用于计算a的内部函数,根据公式(3)
ell <- function(b) { # 计算给定b时的对数似然函数
lb <- log(b)
a <- get.a(b) # 计算a的值
la <- log(a)
n * la + a * n * lb - (a + 1) * sum(log(xs + b)) # 返回对数似然值
}
# 优化函数,寻找最大化对数似然的b值
out <- optim(1, ell, control = list(fnscale = -1), method = "Brent", lower = 0, upper = 100)
c(get.a(out$par), out$par) # 返回a和b的估计值
}
# Fisher信息矩阵函数
# 此函数计算并返回Fisher信息矩阵,用于后续的置信区间计算
info <- function(theta) {
a <- theta[1] # 参数a
b <- theta[2] # 参数b
# 根据提供的公式计算Fisher信息矩阵的元素
i11 <- 1 / a^2
i12 <- -1 / (b * (a + 1))
i21 <- i12 # 对称性质,i12和i21相同
i22 <- a / (b^2 * (a + 2))
# 构建并返回Fisher信息矩阵
matrix(c(i11, i12, i21, i22), 2, 2)
}
# 计算置信区间端点的函数
# 此函数用于计算参数a和b的置信区间端点
compute.CI.endpoints <- function(xs, alpha) {
theta.hat <- ml.estimate(xs) # 调用ML估计函数获取参数估计值
info.mat <- info(theta.hat) # 计算Fisher信息矩阵
info.mat.inv <- solve(info.mat) # 求Fisher信息矩阵的逆
n <- length(xs) # 样本大小
z <- qnorm(1 - alpha / 2) # 计算正态分布的分位数,用于置信区间的计算
# 计算标准误差
se.a <- sqrt(info.mat.inv[1, 1] / n)
se.b <- sqrt(info.mat.inv[2, 2] / n)
# 计算置信区间的端点
L.a <- theta.hat[1] - z * se.a
U.a <- theta.hat[1] + z * se.a
L.b <- theta.hat[2] - z * se.b
U.b <- theta.hat[2] + z * se.b
# 返回置信区间的端点
list(a = c(L.a, U.a), b = c(L.b, U.b))
}
# 模拟数据生成函数
# 此函数用于根据指定的参数a和b生成模拟数据
rdist <- function(n, a, b) {
u <- runif(n) # 生成均匀分布的随机数
(u^(-1 / a) - 1) * b # 应用反变换采样方法生成数据
}
# 置信区间覆盖率的模拟估计函数
# 此函数用于估计置信区间的覆盖率
approximate.coverage <- function(n, a, b, alpha, trials) {
coverage.a <- 0 # 记录参数a的置信区间覆盖次数
coverage.b <- 0 # 记录参数b的置信区间覆盖次数
for (i in 1:trials) {
simulated.data <- rdist(n, a, b) # 生成模拟数据
CI.endpoints <- compute.CI.endpoints(simulated.data, alpha) # 计算置信区间的端点
# 检查真实参数值是否在置信区间内
if (CI.endpoints$a[1] <= a && a <= CI.endpoints$a[2]) coverage.a <- coverage.a + 1
if (CI.endpoints$b[1] <= b && b <= CI.endpoints$b[2]) coverage.b <- coverage.b + 1
}
# 计算并返回覆盖率
c(coverage.a / trials, coverage.b / trials)
}
# 使用示例
n <- 100 # 设置样本大小
a.true <- 0.9 # 设置真实参数a的值
b.true <- 1.28 # 设置真实参数b的值
alpha <- 0.02 # 设置显著性水平
trials <- 1000 # 设置模拟次数
# 计算置信区间覆盖率
coverage <- approximate.coverage(n, a.true, b.true, alpha, trials)
print(coverage) # 输出覆盖率结果要进行 Fisher 信息矩阵的详细数学证明,我们需要从分布的定义开始,即:
对于给定的密度函数 ,我们需要找到对数似然函数,然后计算其关于参数 和 的一阶和二阶导数。接着,计算这些导数的期望值,以得到 Fisher 信息矩阵的各个元素。
以下是详细的步骤:
步骤 1: 对数似然函数
对数似然函数为单个观察值的 对数:
步骤 2: 一阶导数(偏导数)
对 的偏导数为:
对 的偏导数为:
步骤 3: 二阶导数
对 的二阶导数为:
对 ( b ) 的二阶导数为:
对 和 的交叉二阶导数为:
步骤 4: 二阶导数的期望值
我们需要找到上述二阶导数的期望值。对于 Fisher 信息矩阵,我们需要负的期望值。
对 的期望二阶导数:
对 的期望二阶导数(因为第二项中的 在 上的期望并不容易计算,我们只能使用 的积分来近似):
对 和 的期望交叉二阶导数:
由于 的分布是未知的,上述期望值的精确计算可能需要更复杂的积分和概率计算。
步骤 5: 构造Fisher信息矩阵
最后,Fisher 信息矩阵 可以表示为:
公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Web、Linux」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh
