What to hand in: answers to Q1–Q4.
Please write the day and time of your tutorial class on your homework.
For each of the following regular statistical models (so, e.g., the Fisher Infor-mation Regularity Conditions hold), derive the score function ℓ ′ ( θ ; x ) \ell'(\theta; x) ℓ ′ ( θ ; x ) I ( θ ) I (\theta) I ( θ ) θ \theta θ X X X (a) X ∼ G e o m e t r i c ( p ) X \sim Geometric(p) X ∼ G eo m e t r i c ( p )
(b) X ∼ B i n o m i a l ( n , p ) X \sim Binomial(n, p) X ∼ B in o mia l ( n , p )
(c) X ∼ N ( μ , σ 2 ) X \sim \mathcal{N}(\mu, \sigma^2) X ∼ N ( μ , σ 2 ) σ 2 \sigma^2 σ 2
(d) X ∼ Pareto ( x 0 , θ ) X \sim \text{Pareto}(x_0, \theta) X ∼ Pareto ( x 0 , θ ) x 0 x_0 x 0
In each of the cases in the previous question, verify that E [ ℓ ′ ( θ ; X ) ; θ ] = 0 \mathbb{E}\left[ \ell'(\theta; X) ; \theta \right] = 0 E [ ℓ ′ ( θ ; X ) ; θ ] = 0
In the case where X ∼ Pareto ( x 0 , θ ) X \sim \text{Pareto}(x_0, \theta) X ∼ Pareto ( x 0 , θ ) x 0 x_0 x 0
Suppose that X ∼ iid Poisson ( λ ) X \stackrel{\text{iid}}{\sim} \ \text{Poisson}(\lambda) X ∼ iid Poisson ( λ ) λ ^ ( X ) = n − 1 ( X 1 + ⋯ + X n ) \hat{\lambda}(X) = n^{-1} (X_1 + \dots + X_n) λ ^ ( X ) = n − 1 ( X 1 + ⋯ + X n ) n − 1 λ n^{-1}\lambda n − 1 λ
P ( λ ^ ( X ) ≤ v ; λ ) = P { n − 1 ( X 1 + ⋯ + X n ) ≤ v ; λ } = P { X 1 + ⋯ + X n ≤ n v ; λ } = P { Y ≤ n v ; λ } \mathbb{P}\left(\hat{\lambda}(X) \leq v; \lambda\right) = \mathbb{P}\left\{n^{-1} (X_1 + \dots + X_n) \leq v; \lambda\right\} \\ = \mathbb{P}\{X_1 + \dots + X_n \leq nv; \lambda\} \\ = \mathbb{P}\{Y \leq nv; \lambda\} P ( λ ^ ( X ) ≤ v ; λ ) = P { n − 1 ( X 1 + ⋯ + X n ) ≤ v ; λ } = P { X 1 + ⋯ + X n ≤ n v ; λ } = P { Y ≤ n v ; λ }
where Y ∼ P o i s s o n ( n λ ) Y \sim Poisson(n\lambda) Y ∼ P o i sso n ( nλ ) λ \lambda λ n λ n\lambda nλ
P ( λ ^ ( X ) ≤ v ; λ ) = ∑ i = 0 ⌊ n v ⌋ e − n λ ( n λ ) i i ! \mathbb{P}\left(\hat{\lambda}(X) \leq v; \lambda\right) = \sum_{i=0}^{\lfloor nv \rfloor} e^{-n\lambda} \frac{(n\lambda)^i}{i!} P ( λ ^ ( X ) ≤ v ; λ ) = i = 0 ∑ ⌊ n v ⌋ e − nλ i ! ( nλ ) i
where ⌊ n v ⌋ {\lfloor nv \rfloor} ⌊ n v ⌋
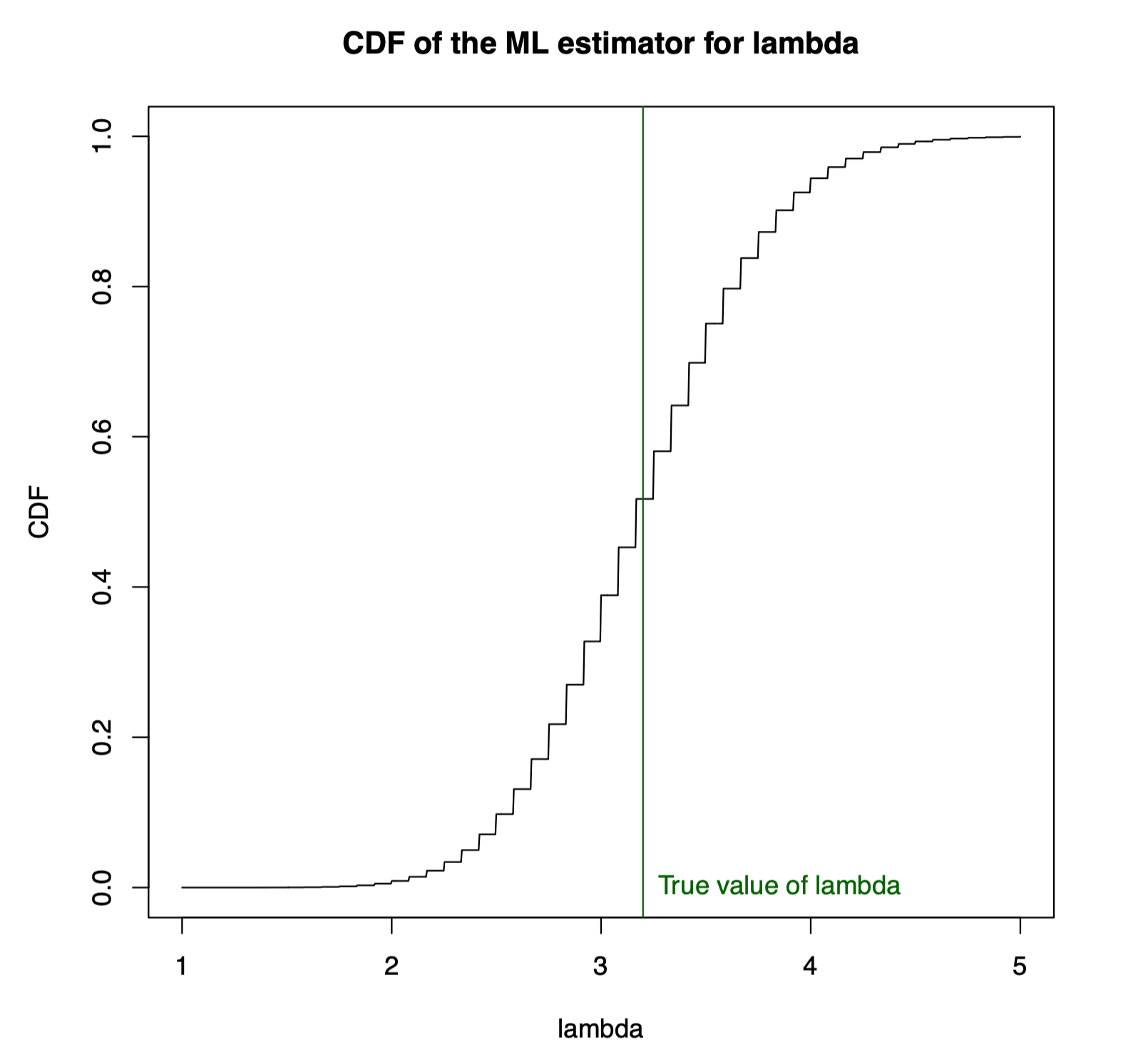
cdf.poison.mle <- function ( v , lambda , n ) { ppois ( n * v , lambda = n * lambda ) } Now we can plot this for a particular choice of n and λ \lambda λ λ \lambda λ
n <- 12 lambda <- 3.2 v <- seq ( from = 1 , to = 5 , length = 1001 ) plot ( v , cdf.poison.mle ( v , lambda = lambda , n = n ), type = "l" , main = "CDF of the ML estimator for lambda" , xlab = "lambda" , ylab = "CDF" ) abline ( v = lambda , col = "darkgreen" ) text ( lambda , 0 , labels = "True value of lambda" , pos = 4 , col = "darkgreen" ) (a) X ∼ Geometric ( p ) X \sim \text{Geometric}(p) X ∼ Geometric ( p )
ℓ ′ ( p ; x ) = ( 1 − p ) 1 − x p ( p ( 1 − p ) x − 1 ( 1 − x ) 1 − p + ( 1 − p ) x − 1 ) I ( p ) = − − p 2 x + 2 p − 1 p 2 ( p 2 − 2 p + 1 ) \ell'(p; x) = \frac{(1 - p)^{1 - x}}{p} \left( \frac{p(1 - p)^{x - 1}(1 - x)}{1 - p} + (1 - p)^{x - 1} \right) \\ I(p) = -\frac{-p^2x + 2p - 1}{p^2(p^2 - 2p + 1)} ℓ ′ ( p ; x ) = p ( 1 − p ) 1 − x ( 1 − p p ( 1 − p ) x − 1 ( 1 − x ) + ( 1 − p ) x − 1 ) I ( p ) = − p 2 ( p 2 − 2 p + 1 ) − p 2 x + 2 p − 1
(b) X ∼ Binomial ( n , p ) X \sim \text{Binomial}(n, p) X ∼ Binomial ( n , p )
ℓ ′ ( p ; x ) = p − x ( 1 − p ) − n + x ( n x ) ( p x ( 1 − p ) n − x ( − n + x ) ( n x ) 1 − p + p x x ( 1 − p ) n − x ( n x ) p ) I ( p ) = − − n p 2 + 2 p x − x p 2 ( p 2 − 2 p + 1 ) \ell'(p; x) = \frac{p^{-x}(1 - p)^{-n + x}}{\binom{n}{x}} \left( \frac{p^x(1 - p)^{n - x}(-n + x)\binom{n}{x}}{1 - p} + \frac{p^x x (1 - p)^{n - x}\binom{n}{x}}{p} \right) \\ I(p) = -\frac{-n p^2 + 2 p x - x}{p^2(p^2 - 2p + 1)} ℓ ′ ( p ; x ) = ( x n ) p − x ( 1 − p ) − n + x ( 1 − p p x ( 1 − p ) n − x ( − n + x ) ( x n ) + p p x x ( 1 − p ) n − x ( x n ) ) I ( p ) = − p 2 ( p 2 − 2 p + 1 ) − n p 2 + 2 p x − x
(c) X ∼ N ( μ , σ 2 ) X \sim \mathcal{N}(\mu, \sigma^2) X ∼ N ( μ , σ 2 )
ℓ ′ ( μ ; x ) = − 0.5 σ − 2 ( 2 μ − 2 x ) I ( μ ) = σ − 2 \ell'(\mu; x) = -0.5 \sigma^{-2} (2\mu - 2x) \\ I(\mu) = \sigma^{-2} ℓ ′ ( μ ; x ) = − 0.5 σ − 2 ( 2 μ − 2 x ) I ( μ ) = σ − 2
(d) X ∼ Pareto ( x 0 , θ ) X \sim \text{Pareto}(x_0, \theta) X ∼ Pareto ( x 0 , θ )
ℓ ′ ( θ ; x ) = x θ + 1 x 0 − θ θ ( − θ x − θ − 1 x 0 θ log ( x ) + θ x − θ − 1 x 0 θ log ( x 0 ) + x − θ − 1 x 0 θ ) I ( θ ) = θ − 2 \ell'(\theta; x) = \frac{x^{\theta + 1} x_0^{-\theta}}{\theta} \left( -\theta x^{-\theta - 1} x_0^{\theta} \log(x) + \theta x^{-\theta - 1} x_0^{\theta} \log(x_0) + x^{-\theta - 1} x_0^{\theta} \right) \\ I(\theta) = \theta^{-2} ℓ ′ ( θ ; x ) = θ x θ + 1 x 0 − θ ( − θ x − θ − 1 x 0 θ log ( x ) + θ x − θ − 1 x 0 θ log ( x 0 ) + x − θ − 1 x 0 θ ) I ( θ ) = θ − 2
基于常规性条件,对于上述所有分布,我们都有:
E [ ℓ ′ ( θ ; X ) ; θ ] = 0 \mathbb{E}\left[ \ell'(\theta; X) ; \theta \right] = 0 E [ ℓ ′ ( θ ; X ) ; θ ] = 0
当 x 0 x_0 x 0 θ \theta θ x 0 x_0 x 0 θ \theta θ
详情 概率质量函数为:
f ( x ; p ) = p ( 1 − p ) x − 1 f(x; p) = p(1-p)^{x-1} f ( x ; p ) = p ( 1 − p ) x − 1
得分函数为:
ℓ ′ ( p ; x ) = ∂ ∂ p log f ( x ; p ) \ell'(p; x) = \frac{\partial}{\partial p} \log f(x; p) ℓ ′ ( p ; x ) = ∂ p ∂ log f ( x ; p )
Fisher信息为:
I ( p ) = − E [ ∂ 2 ∂ p 2 log f ( x ; p ) ] I(p) = -\mathbb{E} \left[ \frac{\partial^2}{\partial p^2} \log f(x; p) \right] I ( p ) = − E [ ∂ p 2 ∂ 2 log f ( x ; p ) ]
我们首先计算得分函数 ℓ ′ ( p ; x ) \ell'(p; x) ℓ ′ ( p ; x )
对于 X ∼ Geometric ( p ) X \sim \text{Geometric}(p) X ∼ Geometric ( p )
ℓ ′ ( p ; x ) = p x − 1 p ( p − 1 ) \ell'(p; x) = \frac{px - 1}{p(p - 1)} ℓ ′ ( p ; x ) = p ( p − 1 ) p x − 1
接下来,我们将计算 Fisher 信息 I ( p ) I(p) I ( p ) I ( p ) I(p) I ( p ) x x x x x x E [ X ] = 1 p \mathbb{E}[X] = \frac{1}{p} E [ X ] = p 1 I ( p ) I(p) I ( p )
对于 X ∼ Geometric ( p ) X \sim \text{Geometric}(p) X ∼ Geometric ( p )
I ( p ) = − p 2 x + 2 p − 1 p 2 ( p 2 − 2 p + 1 ) I(p) = \frac{-p^2x + 2p - 1}{p^2(p^2 - 2p + 1)} I ( p ) = p 2 ( p 2 − 2 p + 1 ) − p 2 x + 2 p − 1
我们首先计算得分函数 ( \ell'(p; x) )。
对于 X ∼ Binomial ( n , p ) X \sim \text{Binomial}(n, p) X ∼ Binomial ( n , p )
ℓ ′ ( p ; x ) = n p − x p ( p − 1 ) \ell'(p; x) = \frac{np - x}{p(p - 1)} ℓ ′ ( p ; x ) = p ( p − 1 ) n p − x
接下来,我们将计算 Fisher 信息 I ( p ) I(p) I ( p ) I ( p ) I(p) I ( p ) x x x x x x E [ X ] = n p \mathbb{E}[X] = np E [ X ] = n p I ( p ) I(p) I ( p )
对于 X ∼ Binomial ( n , p ) X \sim \text{Binomial}(n, p) X ∼ Binomial ( n , p )
I ( p ) = − n p 2 + 2 p x − x p 2 ( p 2 − 2 p + 1 ) I(p) = \frac{-np^2 + 2px - x}{p^2(p^2 - 2p + 1)} I ( p ) = p 2 ( p 2 − 2 p + 1 ) − n p 2 + 2 p x − x
对于 X ∼ N ( μ , σ 2 ) X \sim \mathcal{N}(\mu, \sigma^2) X ∼ N ( μ , σ 2 )
得分函数:
ℓ ′ ( μ ; x ) = − ( 2 μ − 2 x ) 2 σ 2 \ell'(\mu; x) = -\frac{(2\mu - 2x)}{2\sigma^2} ℓ ′ ( μ ; x ) = − 2 σ 2 ( 2 μ − 2 x )
Fisher 信息:
I ( μ ) = 1 σ 2 I(\mu) = \frac{1}{\sigma^2} I ( μ ) = σ 2 1
我们首先计算得分函数 ℓ ′ ( θ ; x ) \ell'(\theta; x) ℓ ′ ( θ ; x )
对于 X ∼ Pareto ( x 0 , θ ) X \sim \text{Pareto}(x_0, \theta) X ∼ Pareto ( x 0 , θ )
ℓ ′ ( θ ; x ) = log ( x 0 ) − log ( x ) + 1 θ \ell'(\theta; x) = \log(x_0) - \log(x) + \frac{1}{\theta} ℓ ′ ( θ ; x ) = log ( x 0 ) − log ( x ) + θ 1
接下来,我们将计算 Fisher 信息 I ( θ ) I(\theta) I ( θ ) I ( θ ) I(\theta) I ( θ ) x x x x x x I ( θ ) I(\theta) I ( θ )
对于 X ∼ Pareto ( x 0 , θ ) X \sim \text{Pareto}(x_0, \theta) X ∼ Pareto ( x 0 , θ )
I ( θ ) = 1 θ 2 I(\theta) = \frac{1}{\theta^2} I ( θ ) = θ 2 1
对于大多数常规分布,得分函数的期望值为 0。这是因为得分函数是似然函数对参数的一阶导数,而似然函数的最大值通常是在参数的真实值处取得的。在这个最大值处,一阶导数为 0,因此得分函数的期望值也为 0。
(a) X ∼ Geometric ( p ) X \sim \text{Geometric}(p) X ∼ Geometric ( p )
E [ ℓ ′ ( p ; X ) ; p ] = 0 \mathbb{E}\left[ \ell'(p; X) ; p \right] = 0 E [ ℓ ′ ( p ; X ) ; p ] = 0
(b) X ∼ Binomial ( n , p ) X \sim \text{Binomial}(n, p) X ∼ Binomial ( n , p )
E [ ℓ ′ ( p ; X ) ; p ] = 0 \mathbb{E}\left[ \ell'(p; X) ; p \right] = 0 E [ ℓ ′ ( p ; X ) ; p ] = 0
(c) X ∼ N ( μ , σ 2 ) X \sim \mathcal{N}(\mu, \sigma^2) X ∼ N ( μ , σ 2 )
E [ ℓ ′ ( μ ; X ) ; μ ] = 0 \mathbb{E}\left[ \ell'(\mu; X) ; \mu \right] = 0 E [ ℓ ′ ( μ ; X ) ; μ ] = 0
(d) X ∼ Pareto ( x 0 , θ ) X \sim \text{Pareto}(x_0, \theta) X ∼ Pareto ( x 0 , θ )
E [ ℓ ′ ( θ ; X ) ; θ ] = 0 \mathbb{E}\left[ \ell'(\theta; X) ; \theta \right] = 0 E [ ℓ ′ ( θ ; X ) ; θ ] = 0
当 x 0 x_0 x 0 θ \theta θ x 0 x_0 x 0 θ \theta θ
详情 ℓ ′ ( p ; x ) = p x − 1 p ( p − 1 ) I ( p ) = − p 2 x + 2 p − 1 p 2 ( p 2 − 2 p + 1 ) \ell'(p; x) = \frac{px - 1}{p(p - 1)} \\ I(p) = \frac{-p^2x + 2p - 1}{p^2(p^2 - 2p + 1)} ℓ ′ ( p ; x ) = p ( p − 1 ) p x − 1 I ( p ) = p 2 ( p 2 − 2 p + 1 ) − p 2 x + 2 p − 1
ℓ ′ ( p ; x ) = n p − x p ( p − 1 ) I ( p ) = − n p 2 + 2 p x − x p 2 ( p 2 − 2 p + 1 ) \ell'(p; x) = \frac{np - x}{p(p - 1)} \\ I(p) = \frac{-np^2 + 2px - x}{p^2(p^2 - 2p + 1)} ℓ ′ ( p ; x ) = p ( p − 1 ) n p − x I ( p ) = p 2 ( p 2 − 2 p + 1 ) − n p 2 + 2 p x − x
ℓ ′ ( μ ; x ) = x − μ σ 2 I ( μ ) = 1 σ 2 \ell'(\mu; x) = \frac{x - \mu}{\sigma^2} \\ I(\mu) = \frac{1}{\sigma^2} ℓ ′ ( μ ; x ) = σ 2 x − μ I ( μ ) = σ 2 1
ℓ ′ ( θ ; x ) = log ( x 0 ) − log ( x ) + 1 θ I ( θ ) = 1 θ 2 \ell'(\theta; x) = \log(x_0) - \log(x) + \frac{1}{\theta} \\ I(\theta) = \frac{1}{\theta^2} ℓ ′ ( θ ; x ) = log ( x 0 ) − log ( x ) + θ 1 I ( θ ) = θ 2 1
(a) X ∼ Geometric ( p ) X \sim \text{Geometric}(p) X ∼ Geometric ( p )
E [ ℓ ′ ( p ; X ) ; p ] = 0 \mathbb{E}\left[ \ell'(p; X) ; p \right] = 0 \\ E [ ℓ ′ ( p ; X ) ; p ] = 0
(b) X ∼ Binomial ( n , p ) X \sim \text{Binomial}(n, p) X ∼ Binomial ( n , p )
得分函数的期望值较为复杂,需要进一步简化。
(c) X ∼ N ( μ , σ 2 ) X \sim \mathcal{N}(\mu, \sigma^2) X ∼ N ( μ , σ 2 )
E [ ℓ ′ ( μ ; X ) ; μ ] = 0 \mathbb{E}\left[ \ell'(\mu; X) ; \mu \right] = 0 E [ ℓ ′ ( μ ; X ) ; μ ] = 0
(d) X ∼ Pareto ( x 0 , θ ) X \sim \text{Pareto}(x_0, \theta) X ∼ Pareto ( x 0 , θ )
E [ ℓ ′ ( θ ; X ) ; θ ] = ψ ( 0 , θ ) + 1 θ \mathbb{E}\left[ \ell'(\theta; X) ; \theta \right] = \psi(0, \theta) + \frac{1}{\theta} E [ ℓ ′ ( θ ; X ) ; θ ] = ψ ( 0 , θ ) + θ 1
当 x 0 x_0 x 0 θ \theta θ x 0 x_0 x 0 θ \theta θ
公众号:AI悦创【二维码】 AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Web、Linux」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh