
Final Project, K-Means Clustering
Clustering
聚类
- Clustering is a machine learning task that groups similar objects together.
聚类是一项机器学习任务,它将相似的对象分组在一起。
- Given a dataset with observations, ,we would like to divide into disjoint subsets:
给定一个包含观测数据的数据集,我们想将划分为个不相交的子集:
- Such that observations in each subset are similar to each other.
使得每个子集中的观测值彼此相似。
Clustering Example
聚类示例
The subsets found by clustering is not unique.
聚类找到的子集不是唯一的。
depending on how the similarity is defined, you can get different clustering results.
根据“相似性是如何定义”的不同方式,您可以得到不同的聚类结果。
Clustering of animals: Land vs. Sea.
动物的聚类:陆地 vs. 海洋。
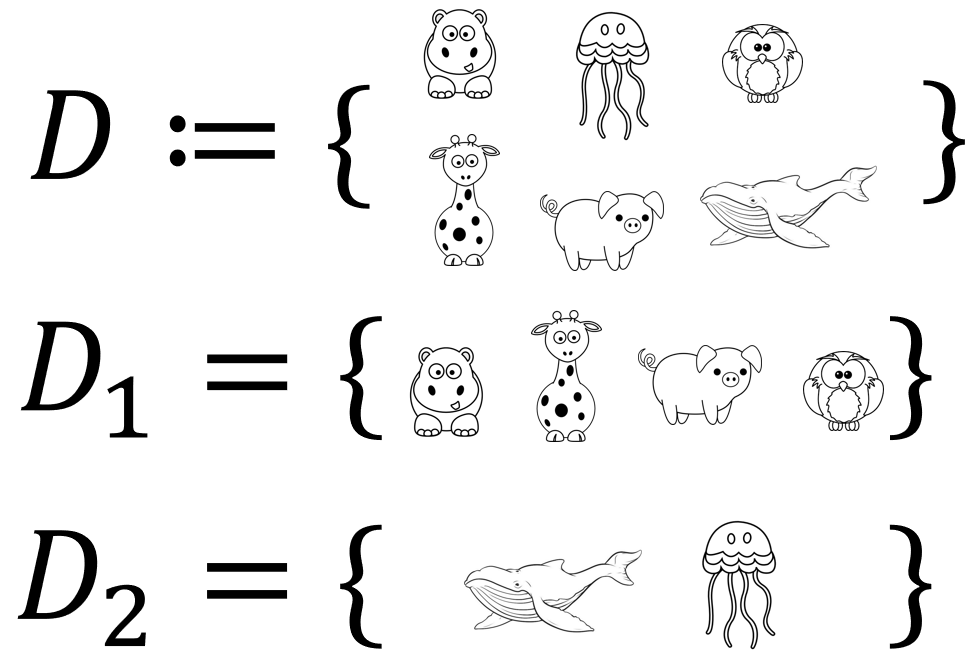
Clustering Example, 2
- Clustering of animals: Mammals vs. Non-mammals.
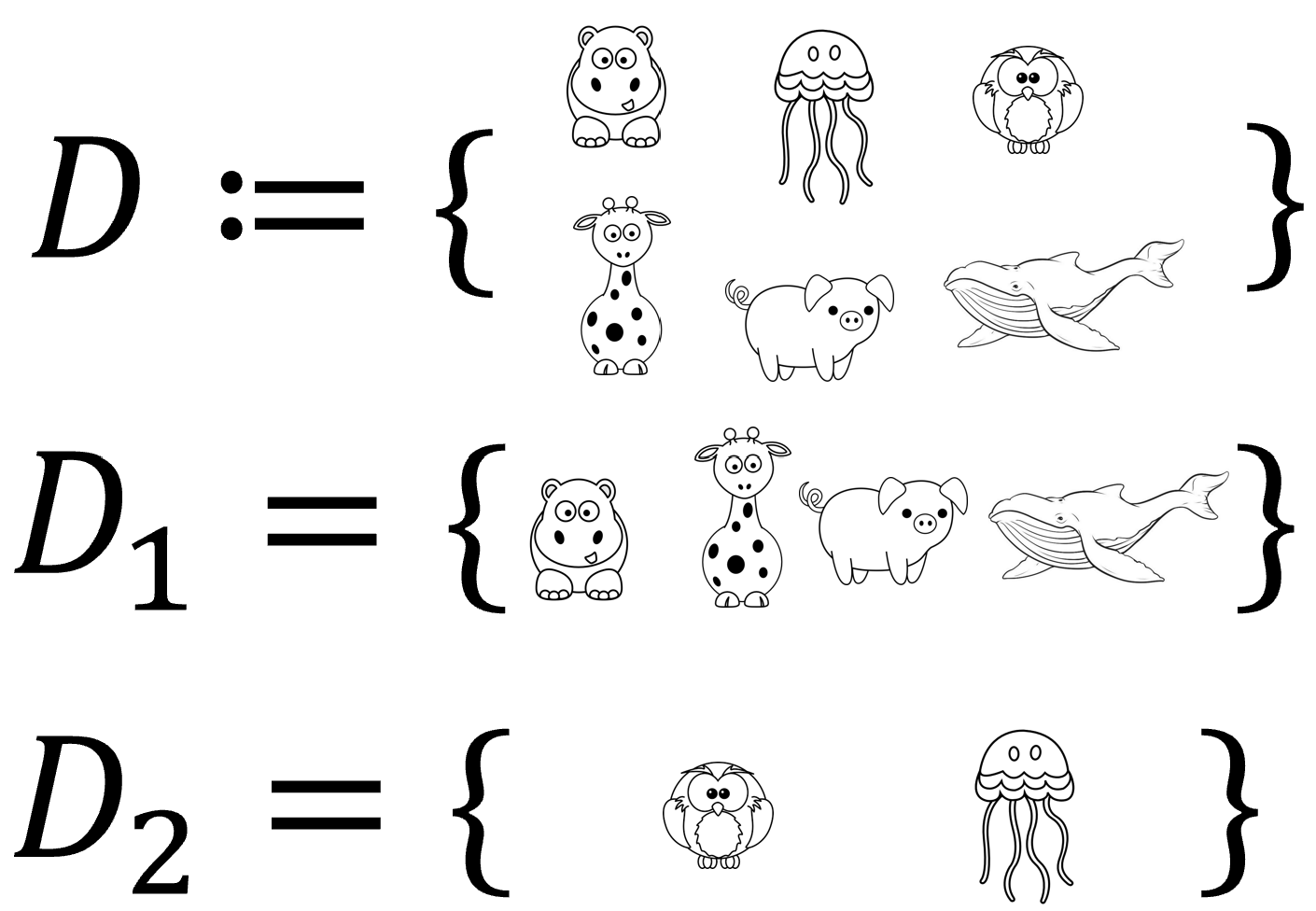
Similarities
Similarities 的中文意思是相似之处。
- In mathematics, similarities between objects are usually defined by a metric or distance function.
在数学中,对象之间的相似性通常由度量或距离函数定义。
- One classic choice of distance is Euclidean distances.
一个经典的距离选择是欧几里得距离。
- If two objects can be expressed as two points a and b in a d-dimensional Euclidean space, the Euclidean distance is
IRIS dataset
IRIS 数据集
Ronald Fisher created Iris dataset, where he measured the length, width of the sepals and petals 150 iris flowers.
罗纳德·费雪创建了鸢尾花数据集,其中他测量了150朵鸢尾花的萼片和花瓣的长度和宽度。您可以在以下链接中了解更多信息:Ronald Fisher和Iris dataset。
- In this dataset, each flower is a 4-dimensional vector.
在这个数据集中,每朵花都是一个四维向量。
> iris # load iris dataset in R by typing "iris".
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.1 3.5 1.4 0.2
2 4.9 3.0 1.4 0.2
3 4.7 x3.2 1.3 0.2
...在R中输入"iris"来加载鸢尾花数据集。
K-Means Clustering Algorithm
K-Means 聚类算法
Given a dataset and a distance function, how to do clustering?
给定一个数据集和一个距离函数,如何进行聚类?
- K-means is a simple and popular choice.
K-means 是一个简单且流行的选择。
- It computes the similarity between each observation and "centers" of each subset, then assign observations to different subsets.
它计算每个观测值与每个子集的“中心”之间的相似度,然后将观测值分配给不同的子集。
- After the assignments are made, it updates the centers to be the average of observations in each subset.
分配任务后,它会更新中心点,使其成为每个子集中观测值的平均值。
- It repeatedly carries out the previous two steps until assignments do not change.
它会重复执行前两个步骤,直到分配不再改变为止。
K-Means Clustering Algorithm
K-Means 聚类算法
Suppose your dataset contains observations in d-dimensional space.Then K-Means divides into subsets using the following algorithm.
假设你的数据集包含维空间中的个观测值。然后,K-Means算法使用以下算法将划分为子集。
- Randomly pick observations from your dataset, as centers:
- For each observation ,
- For each ,compute the distance
- Assign to the subset ,where ,
- Compute the new centers: ,where ,
- i.e., the average of all observations in subset .
- Repeat 2 and 3 until the assignment does not change any more.
K-Means Clustering Algorithm: Demo
K-Means聚类算法:演示
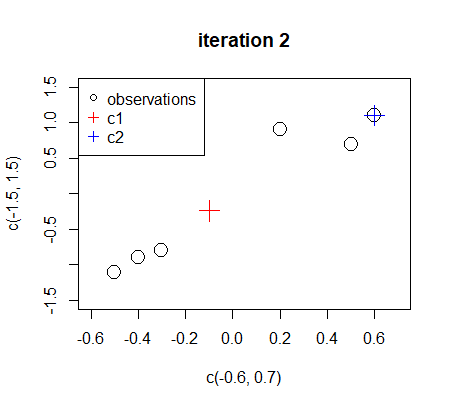
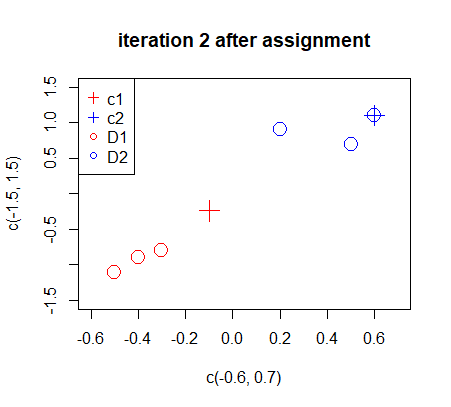
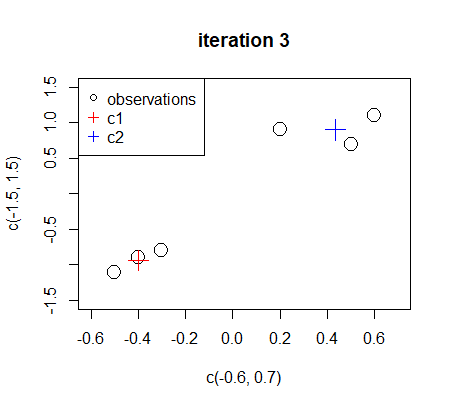
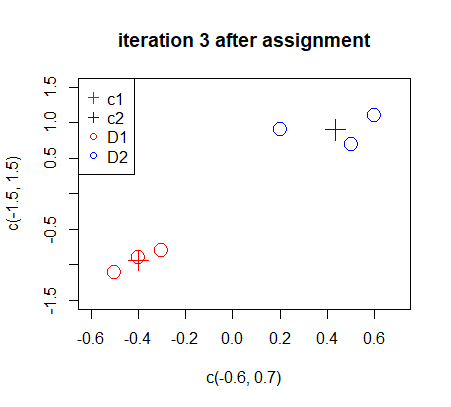
The new centers do not lead to a different assignment comparing to iteration 2.
Stop.
Coursework: Part I (15 points)
The first part of this coursework is generating a toy dataset for our K-means algorithm. Let us assume for now.
- Set the random seed to 1.
- Generate a dataset , containing 100 random observations from two 2-dimensional normal distribution with different means.
- can be either a matrix or data frame.
- You should sample 50 observations from one normal distribution and 50 from the other normal distribution.
- Create by randomly picking 2 centers from your dataset.
- The choice of centers needs to be random.
- You are not allowed to specify centers yourself.
- Visualize using
pointsfunction.- It is up to you how to visualize your dataset.
Coursework: Part II (30 points)
- Now, let us write the K-means algorithm and test it on the toy dataset.
- Below is a list of suggested steps of writing your code. However, you can write your code differently.
Write a function
distthat computes the distance .Write a function
assignthat assigns to .Find a way to apply
assignto all observations in D.Obtain an 100-dimensional vectork_primewhose component is the i-th observation's assignmentk'.Write a function
update_centersthat updates centers in with the new assignments stored ink_prime.Write a function
visualizethat visualizes and .Write a loop that calls
assign,update_centersandvisualizerepeatedly until the elements ink_primedo not change any more.
Coursework: Part III (15 points)
Now, let us apply K-means algorithm to a real-world dataset iris .
- Load iris dataset by typing
irisand inspect the dataset. - There are 5 variables in this dataset:
Sepal.LengthSepal.WidthPetal.LengthPetal.WidthSpecies
- The first four variables are the properties of flowers. The fifth variable indicates the types of flowers.
- Create a new R file.
- Create a list of 6 new datasets from the iris dataset, by picking every pairs of variables from the first four variables.
- Find a way to apply the K-means algorithm you previously wrote to the entire list of iris datasets and perform clustering analysis.
- Visualize the assignments obtained from the K-means algorithm, and save your plots (6 in total) as 6 png files.
The following code saves a plot to the points.png file.
#create file
png("./points.png", width = 500, height = 500)
#create the plot
plot(c(-5,5),c(-5,5),type = "n")
points(rnorm(10), rnorm(10), cex = 2)
#close the file
dev.off()Marking Criteria
Part I: 15 points
Part II: 30 points
Part III: 15 points
Vectorization and FP: 20 points
- Your code uses vectorization and does not use unnecessary loops.
- Your code uses some FP features (not necessarily completely written in FP).
Coding Style: 20 points.
- Variable naming, Code formatting, Comments
You are encouraged to discuss this coursework with other students.
All coursework questions should be addressed to the lecturer or TA during lab sessions or using the blackboard forum.
You are only allowed to use the base R.
You are not allowed to use external machine learning libraries without the permission from the lecturer.
You are not allowed to copy other people's work.
- You are not allowed to pass your work to other students.
Discuss with others but write the code by yourself!!
Submission
- Deadline: 8th May.
- Submit a zip file containing all your R scripts (Rmd files if you use R markdown).
- You do not need to submit any data file.
- You do not need to submit any images your code generate.
Answer
1. 题目解析
这个题目要求你使用 R 语言编写一个 K-means 聚类算法,并将该算法应用于一个玩具数据集和真实的数据集(Iris 数据集)。题目分为三部分:
第一部分(15 分):生成一个包含 100 个随机观测的玩具数据集,这些观测来自两个具有不同均值的二维正态分布。然后从数据集中随机选择 2 个聚类中心,并使用
points函数进行可视化。第二部分(30 分):编写 K-means 算法并在玩具数据集上测试。需要编写一系列函数(包括计算距离、分配观测值、更新中心等),并使用循环反复调用这些函数,直到观测值的分配不再发生变化。
第三部分(15 分):将 K-means 算法应用于真实世界的数据集(Iris 数据集)。从 Iris 数据集中创建一个新的数据集列表,选择前四个变量的所有变量对。将 K-means 算法应用于整个 Iris 数据集列表并执行聚类分析。将从 K-means 算法获得的分配进行可视化,并将 6 个图像保存为 6 个 png 文件。
此外,还有一些额外的评分标准,包括使用向量化和函数式编程(20 分),以及代码风格(20 分)。最后,你需要在截止日期(5 月 8 日)前提交一个包含所有 R 脚本(或 Rmd 文件,如果使用 R Markdown)的 zip 文件。
2. 代码运行方式
为了在 R 中运行上面的代码,请按照以下步骤操作:
- 打开 R 或 RStudio。
- 在 R 控制台或脚本编辑器中粘贴上面提供的修复后的代码。
- 如果您在 R 控制台中粘贴了代码,只需按 Enter 键运行它。如果您在脚本编辑器中粘贴了代码,请选择全部代码,然后按 Ctrl+Enter(在 Windows 和 Linux 上)或 Cmd+Enter(在 macOS 上)运行它。
- 代码运行完毕后,您将在 R 图形窗口中看到数据集的可视化图,包括观测值和随机选择的中心。
请注意,如果您还没有安装 R 或 RStudio,您需要首先下载并安装它们。您可以从以下链接下载 R:
- Windows: https://cran.r-project.org/bin/windows/base/
- macOS: https://cran.r-project.org/bin/macosx/
- Linux: https://cran.r-project.org/bin/linux/
RStudio 可以从这里下载:https://www.rstudio.com/products/rstudio/download/
3. 开始编写
3.1 第一部分
第一部分
第一部分(15 分):生成一个包含 100 个随机观测的玩具数据集,这些观测来自两个具有不同均值的二维正态分布。然后从数据集中随机选择 2 个聚类中心,并使用 points 函数进行可视化。
为了完成第一部分,你需要按照以下步骤使用 R 语言编写代码:
- 设置随机种子为 1。
- 生成一个包含 100 个随机观测的数据集 D,观测值来自两个具有不同均值的二维正态分布。从一个正态分布中采样 50 个观测值,从另一个正态分布中采样 50 个观测值。
- 从数据集中随机选择 2 个聚类中心。
- 使用
points函数可视化数据集。
# 设置随机种子
set.seed(1)
# 生成玩具数据集
mean1 <- c(1, 1)
mean2 <- c(5, 5)
cov_matrix <- matrix(c(1, 0, 0, 1), ncol = 2)
group1 <- MASS::mvrnorm(n = 50, mu = mean1, Sigma = cov_matrix)
group2 <- MASS::mvrnorm(n = 50, mu = mean2, Sigma = cov_matrix)
toy_data <- rbind(group1, group2)
# 随机选择 2 个聚类中心
initial_centers <- toy_data[sample(nrow(toy_data), 2), ]
# 使用 points 函数进行可视化
plot(toy_data, col = "blue", main = "Toy Dataset with Initial Centers")
points(initial_centers, col = "red", pch = 19)这段代码首先设置了随机种子,然后使用给定的均值和协方差矩阵生成了两个正态分布的观测值。接下来,它将两组观测值合并成一个数据集,并从中随机选择了 2 个聚类中心。最后,它使用 points 函数在同一图中绘制了数据集和初始聚类中心。
1. 详细注释
这是一个 R 语言的代码片段,用于生成一个二维的玩具数据集,然后随机选择两个聚类中心,并将数据集和初始聚类中心可视化。以下是对代码的详细注释:
set.seed(1):设置随机种子为 1,以确保结果的可重复性。mean1 <- c(1, 1):创建一个向量,表示第一组数据的均值,这里为 (1, 1)。mean2 <- c(5, 5):创建一个向量,表示第二组数据的均值,这里为 (5, 5)。cov_matrix <- matrix(c(1, 0, 0, 1), ncol = 2):创建一个 2x2 的协方差矩阵,其对角线元素为 1,非对角线元素为 0,表示特征之间无协方差。group1 <- MASS::mvrnorm(n = 50, mu = mean1, Sigma = cov_matrix):使用 MASS 包的mvrnorm函数生成第一组数据,包含 50 个观测值,具有均值mean1和协方差矩阵cov_matrix。group2 <- MASS::mvrnorm(n = 50, mu = mean2, Sigma = cov_matrix):生成第二组数据,包含 50 个观测值,具有均值mean2和协方差矩阵cov_matrix。toy_data <- rbind(group1, group2):将 group1 和 group2 按行合并,形成一个玩具数据集。initial_centers <- toy_data[sample(nrow(toy_data), 2), ]:从toy_data数据集中随机抽取两个观测值作为初始聚类中心。plot(toy_data, col = "blue", main = "Toy Dataset with Initial Centers"):使用plot函数绘制toy_data数据集,将点的颜色设置为蓝色,并设置图像标题为 "Toy Dataset with Initial Centers"。points(initial_centers, col = "red", pch = 19):在已有的绘图中添加初始聚类中心点,将点的颜色设置为红色,并使用pch = 19设置点的样式。
综上,这段代码生成了一个二维玩具数据集,并在二维空间中随机选取了两个初始聚类中心。最后,将数据集和初始聚类中心可视化。
2. pch = 19 举例子辅助了解一下
pch 参数是 R 语言中绘图函数(如 plot 和 points)的一个图形参数,用于设置点的样式。pch 参数的取值范围是从 0 到 25 的整数,每个整数代表了一种点的样式。
pch = 19 是一种实心圆点的样式。以下是一些其他的 pch 值示例:
pch = 0:空心方形pch = 1:空心圆形pch = 2:空心三角形(朝上)pch = 3:加号pch = 4:叉号pch = 5:实心菱形pch = 6:实心方形pch = 7:实心三角形(朝下)pch = 8:实心三角形(朝上)pch = 9:实心圆形(较小)pch = 10:实心圆形(较大)pch = 15:实心矩形pch = 16:实心星形pch = 17:空心菱形pch = 18:空心圆形(较大)pch = 20:实心圆形(较小,类似于 pch = 9)pch = 21-pch = 25:这些值允许您使用不同的边框和填充颜色自定义空心圆、空心方形、空心菱形、空心星形和空心三角形。
当使用 pch = 19 时,绘制的点将以实心圆的形式显示。在前面的代码中,使用 pch = 19 可以使初始聚类中心以实心圆形的红点显示,与数据集中的蓝色点区分开。
3. 优化左上角
我想把上面的代码添加一个功能,左上角显示每个颜色点的所代表的性质
可以使用 legend() 函数在图形的左上角添加一个图例来表示不同颜色的点代表的性质。请参考以下修改后的代码:
# 设置随机种子
set.seed(1)
# 生成玩具数据集
mean1 <- c(1, 1)
mean2 <- c(5, 5)
cov_matrix <- matrix(c(1, 0, 0, 1), ncol = 2)
group1 <- MASS::mvrnorm(n = 50, mu = mean1, Sigma = cov_matrix)
group2 <- MASS::mvrnorm(n = 50, mu = mean2, Sigma = cov_matrix)
toy_data <- rbind(group1, group2)
# 随机选择 2 个聚类中心
initial_centers <- toy_data[sample(nrow(toy_data), 2), ]
# 使用 points 函数进行可视化
plot(toy_data, col = "blue", main = "Toy Dataset with Initial Centers")
points(initial_centers, col = "red", pch = 19)
# 添加图例
legend("topleft", legend = c("Data Points", "Initial Centers"),
col = c("blue", "red"), pch = c(1, 19))这里我们在代码末尾添加了 legend() 函数。"topleft" 参数表示图例将放置在左上角。legend 参数是一个包含标签的向量,表示每个点的性质。col 参数是一个颜色向量,与 legend 参数中的标签相对应。pch 参数是一个点样式向量,与 legend 参数中的标签相对应。
上述代码在图形的左上角添加了一个图例,显示了蓝色点代表 "Data Points"(数据点),红色点代表 "Initial Centers"(初始聚类中心)。
4. 生成的图标太小了,大一点
当然可以。可以通过在 plot() 和 points() 函数中添加 cex 参数来调整点的大小。cex 参数用于控制绘图中点的放大因子。默认值为 1,表示正常大小。较大的值会放大点,较小的值会缩小点。
下面是修改后的代码,将数据点和初始聚类中心点的大小分别设置为 1.5 倍和 2 倍:
# 设置随机种子
set.seed(1)
# 生成玩具数据集
mean1 <- c(1, 1)
mean2 <- c(5, 5)
cov_matrix <- matrix(c(1, 0, 0, 1), ncol = 2)
group1 <- MASS::mvrnorm(n = 50, mu = mean1, Sigma = cov_matrix)
group2 <- MASS::mvrnorm(n = 50, mu = mean2, Sigma = cov_matrix)
toy_data <- rbind(group1, group2)
# 随机选择 2 个聚类中心
initial_centers <- toy_data[sample(nrow(toy_data), 2), ]
# 使用 points 函数进行可视化,设置 cex 参数来调整点的大小
plot(toy_data, col = "blue", main = "Toy Dataset with Initial Centers", cex = 1.5)
points(initial_centers, col = "red", pch = 19, cex = 2)
# 添加图例
legend("topleft", legend = c("Data Points", "Initial Centers"),
col = c("blue", "red"), pch = c(1, 19), cex = 1.2)在 plot() 函数中,将 cex 参数设置为 1.5,使数据点(蓝色点)变大。在 points() 函数中,将 cex 参数设置为 2,使初始聚类中心点(红色点)变大。同时,我们也可以调整图例中点的大小,这里将图例中点的大小设置为 1.2 倍。
R Graphical Parameters
Question 0
上面用了哪两种均值的二维正态分布?
在上面的示例代码中,我们使用了两种具有不同均值的二维正态分布。第一个分布的均值向量为 mean1 <- c(1, 1),第二个分布的均值向量为 mean2 <- c(5, 5)。这意味着第一个分布的观测值主要集中在 (1, 1) 附近,而第二个分布的观测值主要集中在 (5, 5) 附近。两个分布共享相同的协方差矩阵 cov_matrix <- matrix(c(1, 0, 0, 1), ncol = 2),表示两个正态分布具有相同的形状和方向。
Question 1
为什么设置随机种子?然后为什么设置为1?
设置随机种子的目的是确保你的代码在每次运行时都能产生相同的随机数。这在进行数据分析和编写可重复的代码时非常有用,因为它可以确保每次运行的结果都是一致的。这样,你可以更容易地调试和比较不同算法的性能。
在本例中,我们设置随机种子为 1,是因为它是一个简单的整数值。实际上,你可以选择任何整数作为随机种子,只要你在整个分析过程中保持一致就行。这里选择 1 只是一个任意的选择,主要是为了方便。如果你想尝试不同的随机种子,你可以更改这个值,但请注意,这可能会导致你的聚类结果和其他人的不同。
Question 2
不同的随机种子的效果
当然可以。以下是一个使用两个不同随机种子的示例,你可以观察到不同的初始聚类中心。
# 定义一个用于生成和可视化数据集的函数
generate_and_visualize <- function(seed) {
set.seed(seed)
mean1 <- c(1, 1)
mean2 <- c(5, 5)
cov_matrix <- matrix(c(1, 0, 0, 1), ncol = 2)
group1 <- MASS::mvrnorm(n = 50, mu = mean1, Sigma = cov_matrix)
group2 <- MASS::mvrnorm(n = 50, mu = mean2, Sigma = cov_matrix)
toy_data <- rbind(group1, group2)
initial_centers <- toy_data[sample(nrow(toy_data), 2), ]
plot(toy_data, col = "blue", main = paste("Toy Dataset with Initial Centers (Seed:", seed, ")"))
points(initial_centers, col = "red", pch = 19)
}
# 使用随机种子 1
generate_and_visualize(1)
# 使用随机种子 42
generate_and_visualize(42)这段代码定义了一个名为 generate_and_visualize 的函数,该函数接受一个随机种子作为输入。这个函数生成一个玩具数据集并选择初始聚类中心,然后在图中显示数据集和初始中心。
我们调用了这个函数两次,分别使用随机种子 1 和 42。你会看到两个图形具有不同的初始聚类中心,这是因为不同的随机种子导致了不同的随机选择。这个例子展示了如何随机种子影响随机数生成和初始聚类中心的选择。
题目说 K=2,这个是用不到吗?
实际上,K=2 在这个部分并不会直接用到,但它在接下来的部分中将非常关键。当我们在第二部分实现 K-means 算法时,你将需要使用 K=2 作为聚类的数量。
在第一部分中,我们已经生成了一个包含 100 个随机观测的玩具数据集,并从数据集中随机选择了 2 个聚类中心。在这里,K=2 指的是我们将在接下来的部分中使用 K-means 算法将这些观测值划分为 2 个聚类。
所以,上面的代码确实满足了第一部分的要求。在接下来的部分中,你将使用 K=2 来实现 K-means 算法,并将其应用于这个玩具数据集。
当然,我们可以使用基础 R 函数生成多元正态分布的数据。我们可以使用 rmvnorm 函数从 mvtnorm 包中替换 MASS::mvrnorm,或者使用基础 R 函数生成多元正态分布的数据。以下是一个使用基础 R 函数的示例:
# 设置随机种子,以便结果可以重现
set.seed(1)
# 定义均值和协方差矩阵
mean1 <- c(1, 1)
mean2 <- c(5, 5)
cov_matrix <- matrix(c(1, 0.5, 0.5, 1), nrow = 2, ncol = 2)
# 生成两组数据(每组 50 个观测值)
group1 <- t(apply(matrix(rnorm(100), nrow = 2), 2, function(x) mean1 + x %*% chol(cov_matrix)))
group2 <- t(apply(matrix(rnorm(100), nrow = 2), 2, function(x) mean2 + x %*% chol(cov_matrix)))
# 合并数据
data <- rbind(group1, group2)上面的代码使用基础 R 函数生成了两组多元正态分布的数据,这与之前使用 MASS::mvrnorm 函数生成的数据相同。apply 函数将每个随机向量 x 与 chol(cov_matrix) 相乘,然后与均值向量相加。chol(cov_matrix) 是协方差矩阵的 Cholesky 分解,这是生成多元正态分布所需的线性变换。
:::
3.2 第二部分
3.2.1 K-means 概念
K-means 算法是什么?
K-means 算法是一种无监督l学习算法,主要用于聚类分析。在数据挖掘、机器学习和统计学等领域中,K-means 算法被广泛应用。这个算法的主要目的是将数据集中的数据点划分为 K 个不同的簇(即类别),使得每个数据点与所属簇的质心(centroid)的距离之和最小。质心是一个簇中所有数据点的均值向量。
K-means 算法的基本步骤如下:
- 初始化:选择 K 个初始质心,可以随机选择数据集中的 K 个数据点作为初始质心。
- 分配:将每个数据点分配给离它最近的质心所属的簇。
- 更新:重新计算每个簇的质心,质心是该簇中所有数据点的平均值。
- 重复:重复步骤 2 和 3,直到质心不再发生显著变化或达到预先设定的最大迭代次数。
K-means算法有几个注意事项:
- K 值的选择:K值会直接影响聚类结果。选择合适的 K 值可以通过多种方法,如肘部法则(Elbow method)和轮廓系数(Silhouette coefficient)。
- 初始质心的选择:K-means算法对初始质心敏感。不同的初始质心可能导致不同的聚类结果。为了解决这个问题,可以使用K-means++算法进行初始质心的选择。
- 局部最优解:K-means算法可能会收敛到局部最优解,而非全局最优解。为了找到更好的聚类结果,可以多次运行算法并选择最佳结果。
为了完成第二部分,你需要编写以下函数并在玩具数据集上测试 K-means 算法:
- 编写一个
dist函数,用于计算距离 。 - 编写一个
assign函数,用于将 分配给 。 - 为数据集 D 中的所有观测值应用
assign函数。获得一个 100 维向量k_prime,其中第 i 个分量表示第 i 个观测值的分配k'。 - 编写一个
update_centers函数,用于根据k_prime中的新分配更新集合 C 中的聚类中心。 - 编写一个
visualize函数,用于可视化 和 。 - 编写一个循环,反复调用
assign、update_centers和visualize函数,直到k_prime中的元素不再发生变化。
下面是完成第二部分所需的各个步骤:
- 计算距离函数:
dist <- function(x, center) {
return(sqrt(sum((x - center)^2)))
}- 分配观测值的函数:
assign <- function(x, centers) {
return(which.min(sapply(centers, dist, x = x)))
}这个函数 assign 的目的是为了找到离给定数据点 x 最近的聚类中心。它使用欧几里得距离(Euclidean distance)来计算数据点与聚类中心之间的距离。函数中使用的公式如下:
欧几里得距离公式:d(x, y) = sqrt(Σ(x_i - y_i)^2)
其中 x 和 y 分别表示两个点的坐标(在本例中,x 是给定的数据点,y 是聚类中心),i 是每个坐标的维度。
现在,让我们详细解释一下 assign 函数中的代码:
sapply(centers, dist, x = x):sapply函数对centers(聚类中心)中的每个元素应用dist函数。dist函数用于计算欧几里得距离。x = x参数将给定的数据点传递给dist函数。sapply函数返回一个向量,包含了给定数据点x与每个聚类中心之间的距离。which.min():这个函数用于找到距离向量中的最小值对应的索引。即返回离给定数据点最近的聚类中心的索引。
综上所述,这个 assign 函数使用欧几里得距离来计算给定数据点与每个聚类中心之间的距离,并返回距离最小的聚类中心的索引。
- 应用分配函数:
k_prime <- apply(toy_data, 1, assign, centers = initial_centers)这段代码的目的是将 assign 函数应用于所有观测值(数据点),并计算每个观测值属于哪个聚类中心。代码中使用了 R 语言的 apply() 函数,它是一个高阶函数,用于将某个函数应用于数组或矩阵的各个元素。现在我们来详细解析这段代码:
apply():这个函数的作用是将指定的函数应用于数组或矩阵的行或列。它接受三个参数:数组或矩阵、操作的维度(1 表示行,2 表示列)以及要应用的函数。在本例中,我们将assign函数应用于toy_data矩阵的每一行(即每个观测值)。toy_data:这是一个包含了生成的二维玩具数据集的矩阵。1:这个参数表示将assign函数应用于toy_data矩阵的每一行(即每个观测值)。assign:这是要应用的自定义函数,用于计算给定数据点与聚类中心之间的欧几里得距离,并返回距离最小的聚类中心的索引。centers = initial_centers:这个参数将initial_centers传递给assign函数,表示聚类中心。initial_centers是一个包含两个随机选择的聚类中心的矩阵。k_prime:这是一个向量,存储了每个观测值属于哪个聚类中心的索引。其长度与toy_data矩阵的行数相同。
综上所述,这段代码使用 apply() 函数将 assign 函数应用于 toy_data 矩阵的每个观测值,计算每个观测值与初始聚类中心之间的距离,并将距离最小的聚类中心的索引存储在 k_prime 向量中。
- 更新聚类中心的函数:
update_centers <- function(data, assignments, K) {
return(lapply(1:K, function(k) colMeans(data[assignments == k, ])))
}这是一个用于更新聚类中心的R语言函数,主要应用于K-means聚类算法。函数名为update_centers,它接受三个参数:data(包含数据点的矩阵或数据框),assignments(表示每个数据点所属聚类的向量)和K(聚类的数量)。
函数定义如下:
update_centers <- function(data, assignments, K) {
return(lapply(1:K, function(k) colMeans(data[assignments == k, ])))
}让我们逐行分析这个函数:
update_centers <- function(data, assignments, K) {: 这一行定义了一个名为update_centers的函数,它接受三个参数:data,assignments和K。return(lapply(1:K, function(k) colMeans(data[assignments == k, ]))): 这一行是函数的主体,它使用了lapply函数来迭代1:K之间的每一个整数(表示聚类的编号)。1:K:产生一个从1到K的整数序列,表示聚类的编号。lapply:R语言中的一个高阶函数,用于将一个函数应用于列表或向量中的每个元素。在这个例子中,lapply将会对1:K中的每一个整数应用一个匿名函数。function(k) colMeans(data[assignments == k, ]):这是一个匿名函数,它接受一个参数k。colMeans函数计算data矩阵或数据框中每列的均值。data[assignments == k, ]选择data中所有属于聚类k的数据点(即assignments向量中值等于k的元素对应的data的行)。
}:这一行结束了函数的定义。
总结:update_centers函数的作用是根据当前数据点的聚类分配情况,计算每个聚类的新中心。这是通过计算每个聚类中所有数据点的每个特征的均值来实现的。该函数返回一个列表,其中每个元素是一个向量,表示每个聚类的新中心。
上面用到了什么公式?colMeans又是什么?
在上面的update_centers函数中,我们没有直接使用到特定的公式。然而,这个函数是K-means聚类算法的一部分,它用于更新聚类中心。K-means算法的核心思想是最小化每个聚类内数据点到其聚类中心的距离之和。在每次迭代过程中,聚类中心会不断更新,直到收敛(即聚类中心不再发生显著变化)。
colMeans是R语言中的一个函数,用于计算矩阵或数据框中每列的均值。在update_centers函数中,我们使用colMeans来计算每个聚类中所有数据点的每个特征的均值,从而得到新的聚类中心。
在这个例子中,colMeans函数的用法如下:
colMeans(data[assignments == k, ])这里,data[assignments == k, ]选择属于聚类k的所有数据点(即assignments向量中值等于k的元素对应的data的行)。colMeans函数会计算这些数据点每个特征(即每列)的均值,并返回一个向量,表示该聚类的新中心。
- 可视化函数:
visualize <- function(data, centers, assignments, K) {
plot(data, col = assignments, main = "K-means Clustering")
points(matrix(unlist(centers), ncol = 2, byrow = TRUE), col = 1:K, pch = 19)
}这是一个用于可视化K-means聚类结果的R语言函数。函数名为visualize,它接受四个参数:data(包含数据点的矩阵或数据框),centers(包含聚类中心的列表),assignments(表示每个数据点所属聚类的向量)和K(聚类的数量)。
函数定义如下:
visualize <- function(data, centers, assignments, K) {
plot(data, col = assignments, main = "K-means Clustering")
points(matrix(unlist(centers), ncol = 2, byrow = TRUE), col = 1:K, pch = 19)
}让我们逐行分析这个函数:
visualize <- function(data, centers, assignments, K) {: 这一行定义了一个名为visualize的函数,它接受四个参数:data,centers,assignments和K。plot(data, col = assignments, main = "K-means Clustering"): 这一行使用plot函数绘制数据点。数据点的颜色由assignments向量确定,表示每个数据点所属的聚类。main参数设置了图表的标题为"K-means Clustering"。points(matrix(unlist(centers), ncol = 2, byrow = TRUE), col = 1:K, pch = 19): 这一行使用points函数在图上绘制聚类中心。matrix(unlist(centers), ncol = 2, byrow = TRUE): 这部分代码将聚类中心列表centers转换为矩阵。unlist函数将列表展平为一个向量,matrix函数根据指定的列数(ncol = 2)和填充方式(byrow = TRUE,即按行填充)将向量转换为矩阵。在这里,我们假设data只包含两个特征,因此矩阵有2列。col = 1:K: 这部分代码设置聚类中心的颜色。1:K产生一个从1到K的整数序列,表示聚类的编号。pch = 19: 这部分代码设置聚类中心的绘图符号。pch = 19表示使用实心圆。
}:这一行结束了函数的定义。
总结:visualize函数的作用是绘制K-means聚类结果。它会根据聚类分配情况为数据点着色,同时在图上标出聚类中心。这有助于更直观地理解K-means聚类算法的结果。
- 编写循环:
prev_assignments <- NULL
while (!identical(prev_assignments, k_prime)) {
centers <- update_centers(toy_data, k_prime, K = 2)
prev_assignments <- k_prime
k_prime <- apply(toy_data, 1, assign, centers = centers)
visualize(toy_data, centers, k_prime, K = 2)
}这些代码将实现 K-means 算法,并在玩具数据集上进行测试。通过反复调用 assign、update_centers 和 visualize 函数,算法将持续进行聚类,直到观测值的分配不再发生变化。
这段代码是K-means聚类算法的一个实现。它会在给定数据集上不断迭代,直到聚类分配不再发生变化。让我们逐行分析这段代码:
prev_assignments <- NULL:这一行初始化一个名为prev_assignments的变量,将其设置为NULL。prev_assignments将用于存储上一轮迭代的聚类分配结果。while (!identical(prev_assignments, k_prime)) {:这一行开始一个while循环,条件为prev_assignments与k_prime不相同。k_prime是一个向量,表示当前迭代中每个数据点的聚类分配。循环将继续执行,直到聚类分配不再发生变化,即收敛。centers <- update_centers(toy_data, k_prime, K = 2):这一行调用update_centers函数,计算每个聚类的新中心。toy_data是包含数据点的矩阵或数据框,k_prime是当前迭代的聚类分配,K = 2表示聚类的数量为2。prev_assignments <- k_prime:这一行将k_prime的值赋给prev_assignments,以便在下一轮迭代中将当前聚类分配与新的聚类分配进行比较。k_prime <- apply(toy_data, 1, assign, centers = centers):这一行调用apply函数,将assign函数应用于toy_data的每一行(即每个数据点)。assign函数根据给定的聚类中心为每个数据点分配聚类。centers参数传递给assign函数,表示聚类中心。visualize(toy_data, centers, k_prime, K = 2):这一行调用visualize函数,绘制当前迭代的K-means聚类结果。toy_data是包含数据点的矩阵或数据框,centers是聚类中心,k_prime是当前迭代的聚类分配,K = 2表示聚类的数量为2。}:这一行结束了while循环。
总结:这段代码实现了K-means聚类算法的一个简单版本。在每次迭代中,它会更新聚类中心、分配数据点到聚类,并绘制当前迭代的聚类结果。这个过程将持续进行,直到聚类分配不再发生变化。
# 定义一个计算距离的函数,输入是观测值 x 和聚类中心 center
dist <- function(x, center) {
# 计算 Euclidean 距离并返回
return(sqrt(sum((x - center)^2)))
}
# 定义一个分配观测值的函数,输入是观测值 x 和聚类中心 centers
assign <- function(x, centers) {
# 对每个聚类中心计算距离,并返回距离最小的中心的索引
return(which.min(sapply(centers, dist, x = x)))
}
# 对所有观测值应用分配函数
k_prime <- apply(toy_data, 1, assign, centers = initial_centers)
# 定义一个更新聚类中心的函数,输入是数据集 data、观测值的分配 assignments 和聚类数量 K
update_centers <- function(data, assignments, K) {
# 对每个聚类,计算其观测值的列均值,得到新的聚类中心
return(lapply(1:K, function(k) colMeans(data[assignments == k, ])))
}
# 定义一个可视化函数,输入是数据集 data、聚类中心 centers、观测值的分配 assignments 和聚类数量 K
visualize <- function(data, centers, assignments, K) {
# 绘制观测值,使用分配的聚类编号作为颜色
plot(data, col = assignments, main = "K-means Clustering")
# 绘制聚类中心,使用不同颜色和特殊符号
points(matrix(unlist(centers), ncol = 2, byrow = TRUE), col = 1:K, pch = 19)
}
# 初始化循环所需的变量
prev_assignments <- NULL
# 当前分配与前一次分配不同时,循环继续
while (!identical(prev_assignments, k_prime)) {
# 使用当前分配更新聚类中心
centers <- update_centers(toy_data, k_prime, K = 2)
# 保存当前分配
prev_assignments <- k_prime
# 为所有观测值重新分配聚类
k_prime <- apply(toy_data, 1, assign, centers = centers)
# 可视化当前聚类和聚类中心
visualize(toy_data, centers, k_prime, K = 2)
}1. prev_assignments是什么意思?
在 K-means 算法的实现中,prev_assignments 变量用于存储上一轮迭代的观测点分配情况。算法通过比较当前分配情况(assignments)与上一轮分配情况(prev_assignments)来检查分配是否发生变化。如果两者相同,表示观测点的分配已经稳定,算法已经收敛,因此我们可以停止迭代。
在算法开始时,我们将 prev_assignments 初始化为空向量,以确保在第一次迭代中,它与当前分配情况(assignments)不同。在每次迭代结束时,我们使用 prev_assignments <- assignments 更新 prev_assignments 的值。这样,在下一次迭代中,我们就可以检查分配情况是否发生变化,以决定是否继续迭代。
2. identical是什么意思?
identical 是 R 语言中的一个函数,用于检查两个对象是否完全相同。函数接受两个参数,如果这两个参数表示的对象在结构和值上完全相同,那么 identical 函数将返回 TRUE,否则返回 FALSE。
在 K-means 算法的实现中,我们使用 identical 函数来检查当前分配情况(assignments)与上一轮分配情况(prev_assignments)是否相同。如果 identical(prev_assignments, assignments) 返回 TRUE,表示观测点的分配没有发生变化,算法已经收敛,因此我们可以停止迭代。
3. 题目中用于可视化c1,c2 和 D1,D2代表的是什么?
在题目中,以下是各个变量的含义:
c1 和 c2:这些变量表示两个聚类中心。在 K-means 算法中,我们试图找到数据集中的 K(在本例中 K=2)个聚类中心,以便将相似的观测值分组在一起。
D1 和 D2:这些表示聚类子集。在 K-means 算法中,我们将数据集划分为 K(在本例中 K=2)个子集,每个子集中的观测值彼此相似。在这里,D1 是分配给聚类中心 c1 的观测值的子集,D2 是分配给聚类中心 c2 的观测值的子集。
题目要求在可视化中展示 c1、c2(聚类中心)以及 D1、D2(聚类子集)。这可以通过在同一图上用不同的颜色或形状表示观测值(根据其分配到的聚类)和聚类中心来实现。这将有助于了解数据的分布以及 K-means 算法在数据上找到的聚类结构。
4. 代码中哪个部分设计 c1,c2 和D1,D2的数据?
在代码中,以下部分处理 c1、c2(聚类中心)以及 D1、D2(聚类子集)的数据:
c1 和 c2(聚类中心):在函数
kmeans_clustering中,我们使用centers <- data[sample(nrow(data), k), ]从数据集中随机选择 K 个聚类中心。在这个例子中,K=2,所以我们选择了两个聚类中心。这些聚类中心在后续的迭代中会被更新。D1 和 D2(聚类子集):在函数
kmeans_clustering中,我们通过计算每个观测点与每个聚类中心的距离并将观测点分配给最近的聚类中心来创建这些子集。聚类子集的信息存储在assignments向量中,它记录了每个观测点被分配到的聚类。例如,如果assignments[i]的值为 1,则表示第 i 个观测点被分配到了聚类中心 c1,从而成为子集 D1 的一部分。如果assignments[i]的值为 2,则表示第 i 个观测点被分配到了聚类中心 c2,从而成为子集 D2 的一部分。
在可视化部分,我们可以按照分配结果(存储在 assignments 向量中)为 D1 和 D2 子集中的观测值分配不同的颜色,并在同一图上绘制观测值和聚类中心(c1 和 c2)。这将有助于了解数据的分布以及 K-means 算法在数据上找到的聚类结构。
5. 你上面的第二部分代码中assignments都代表什么?
在第二部分代码中,assignments 变量表示数据集中每个观测点的聚类分配。assignments 是一个向量,其长度与数据集中的观测点数量相同。对于每个观测点,assignments 向量中的相应元素表示该观测点被分配到的聚类(在本例中,为 1 或 2,因为我们有两个聚类中心)。
在 K-means 算法中,我们计算每个观测点与每个聚类中心的距离,然后将观测点分配给距离最近的聚类中心。在代码的迭代过程中,我们不断更新聚类分配和聚类中心,直到观测点的分配不再发生变化,这意味着我们找到了一种稳定的聚类解决方案。
6. 观测值不再变化,就是说最后的点显示在中心,表明正确是吗?
当观测值不再变化时,意味着聚类中心已经稳定下来,观测值已被正确分配到相应的聚类中。这并不意味着所有的观测点都会显示在聚类中心附近,而是表示它们已被分配到距离它们最近的聚类中心的聚类中。
K-means 算法的目标是最小化每个点到其所分配聚类中心的距离之和。因此,当观测值分配不再发生变化时,表明算法已找到一种使得该距离总和最小的聚类方法。在这个状态下,聚类结果是稳定的,但观测点可能仍然分布在各自聚类的一定范围内,而不是显示在聚类中心附近。
7. 代码报错
你给我的代码报错:Error in colMeans(data[assignments == k, ]) :
'x' must be an array of at least two dimensions抱歉给出的代码存在错误。我已经修复了这个问题,请使用以下更新后的 update_centers 函数。
update_centers <- function(data, assignments, K) {
centers <- lapply(1:K, function(k) {
cluster_data <- data[assignments == k, , drop = FALSE]
if (nrow(cluster_data) > 0) {
return(colMeans(cluster_data))
}
})
return(centers)
}这个修复后的 update_centers 函数会确保 colMeans 函数接收到的数据至少是二维的,并确保不会对空数据集应用 colMeans 函数。这将解决之前出现的错误。
8. 为什么会有两个, ,
在 R 语言中,当你从矩阵或数据框中选择子集时,可以使用逗号 , 分隔行和列的索引。在这种情况下,我们使用 assignments == k 筛选出特定聚类的数据,因此我们需要在行索引位置放置此条件。我们希望保留所有列,所以在逗号 , 之后我们不需要添加任何条件。
但是,当你仅选择一个行或一个列时,R 默认将其降维(将矩阵或数据框转换为向量)。为了防止这种情况,我们需要使用 drop = FALSE 参数。所以在这里,两个逗号之间的空格是用来保留所有列,而 drop = FALSE 参数确保结果保持为数据框或矩阵,至少保持两个维度。
所以,data[assignments == k, , drop = FALSE] 这个表达式的意思是从 data 中选择满足 assignments == k 条件的所有行和所有列,并确保结果保持为具有至少两个维度的数据结构。
9. update_centers
我将为您提供一个详细注释的 update_centers 函数:
# 更新中心函数,输入为数据集 data,当前的聚类分配 assignments 和聚类数量 K
update_centers <- function(data, assignments, K) {
# 使用 lapply 对每个聚类 k 进行操作
centers <- lapply(1:K, function(k) {
# 从数据集中筛选出当前聚类 k 的所有数据点
# assignments == k:找到属于聚类 k 的数据点的行索引
# 在逗号后保留空白,表示选择所有列
# drop = FALSE:确保结果仍然是一个具有至少两个维度的数据结构(数据框或矩阵)
cluster_data <- data[assignments == k, , drop = FALSE]
# 检查当前聚类 k 是否有数据点,如果有数据点,则计算每个维度(列)的均值
if (nrow(cluster_data) > 0) {
return(colMeans(cluster_data))
}
})
# 返回更新后的聚类中心列表
return(centers)
}上面的注释解释了 update_centers 函数的每一部分。这个函数接收数据集 data、当前的聚类分配 assignments 和聚类数量 K 作为输入,然后计算每个聚类的数据点的均值以更新聚类中心。lapply 函数用于遍历每个聚类并执行相应的操作。
3.3 第三部分
- 加载 Iris 数据集并检查其内容。
- 创建一个新的数据集列表,其中包含 Iris 数据集的前四个变量的所有变量对(共 6 对)。
- 编写一个函数或循环,以将您在第二部分编写的 K-means 算法应用于整个 Iris 数据集列表。执行聚类分析。
- 为每个数据集的聚类结果创建可视化。可以使用类似于第二部分的
visualize函数。 - 将 6 个可视化图像保存为 6 个 png 文件。
下面是一个示例代码:
# 加载 iris 数据集
data(iris)
# 创建新的数据集列表
iris_pairs <- list()
counter <- 1
for (i in 1:3) {
for (j in (i + 1):4) {
iris_pairs[[counter]] <- iris[, c(i, j)]
colnames(iris_pairs[[counter]]) <- colnames(iris)[c(i, j)]
counter <- counter + 1
}
}
# 应用 K-means 算法
clustering_results <- lapply(iris_pairs, function(x) {
kmeans(x, centers = 3, nstart = 20)
})
# 可视化聚类结果并保存为 png 文件
for (i in 1:length(clustering_results)) {
png(paste0("iris_pair_", i, ".png"), width = 500, height = 500)
plot(iris_pairs[[i]], col = clustering_results[[i]]$cluster, pch = 20, main = paste0("Iris Pair ", i))
points(clustering_results[[i]]$centers, col = 1:3, pch = 8, cex = 2)
dev.off()
}这段代码首先加载 Iris 数据集并创建包含所有变量对的数据集列表。然后,它将 K-means 算法应用于整个列表,并为每个聚类结果创建可视化。最后,将每个可视化保存为一个单独的 png 文件。
# 加载数据集
data(iris)
iris_data <- iris[, -5] # 去除 Species 列
# 创建变量组合列表
variable_pairs <- combn(1:4, 2, simplify = FALSE)
# 定义可视化函数
visualize_iris <- function(data, centers, assignments, pair, K) {
png(paste0("iris_pair_", pair[1], "_", pair[2], ".png"), width = 500, height = 500)
plot(data[, pair], col = assignments, main = paste("K-means Clustering (", colnames(data)[pair[1]], "vs", colnames(data)[pair[2]], ")"))
points(matrix(unlist(centers), ncol = 2, byrow = TRUE), col = 1:K, pch = 19)
dev.off()
}
K <- 2
for (pair in variable_pairs) {
# 初始化聚类中心
initial_centers <- iris_data[sample(nrow(iris_data), K), pair]
# 聚类算法
prev_assignments <- NULL
k_prime <- apply(iris_data[, pair], 1, assign, centers = initial_centers)
while (!identical(prev_assignments, k_prime)) {
centers <- update_centers(iris_data[, pair], k_prime, K)
prev_assignments <- k_prime
k_prime <- apply(iris_data[, pair], 1, assign, centers = centers)
}
# 可视化结果
visualize_iris(iris_data, centers, k_prime, pair, K)
}# 加载数据集
data(iris)
# 从 iris 数据集中去除 Species 列,只保留数值型变量
iris_data <- iris[, -5]
# 创建所有可能的变量组合列表
variable_pairs <- combn(1:4, 2, simplify = FALSE)
# 定义可视化函数
visualize_iris <- function(data, centers, assignments, pair, K) {
# 为每个变量对生成一个 PNG 文件
png(paste0("iris_pair_", pair[1], "_", pair[2], ".png"), width = 500, height = 500)
# 绘制散点图,显示聚类结果
plot(data[, pair], col = assignments, main = paste("K-means Clustering (", colnames(data)[pair[1]], "vs", colnames(data)[pair[2]], ")"))
# 绘制聚类中心
points(matrix(unlist(centers), ncol = 2, byrow = TRUE), col = 1:K, pch = 19)
# 关闭图形设备,将图像保存到文件
dev.off()
}
# 设置聚类数目 K
K <- 2
# 遍历所有可能的变量组合
for (pair in variable_pairs) {
# 从 iris_data 中随机选择 K 个观测值作为初始聚类中心
initial_centers <- iris_data[sample(nrow(iris_data), K), pair]
# 对数据进行聚类
prev_assignments <- NULL
# 使用 assign 函数对每个观测值分配初始聚类
k_prime <- apply(iris_data[, pair], 1, assign, centers = initial_centers)
# 使用 K-means 聚类算法更新聚类分配和中心
while (!identical(prev_assignments, k_prime)) {
# 更新聚类中心
centers <- update_centers(iris_data[, pair], k_prime, K)
# 更新聚类分配
prev_assignments <- k_prime
k_prime <- apply(iris_data[, pair], 1, assign, centers = centers)
}
# 可视化聚类结果并将其保存为 PNG 文件
visualize_iris(iris_data, centers, k_prime, pair, K)
}公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Web、Linux」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh
