
Day 6:dict 和 set 的 15 个经典使用例子
你好,我是悦创。
今天,学习关于运用字典和集合的 15 个例子。
1. update
实际使用字典时,需要批量插入键值对到已有字典中,使用 update 方法实现批量插入。
已有字典中批量插入键值对:
In [23]: d = {'a': 1, 'b': 2}
# 方法 1
In [24]: d.update({'c': 3, 'd': 4, 'e': 5})
In [25]: d
Out[25]: {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}# 方法 2
In [31]: d = {'a': 1, 'b': 2}
...: d.update([('c', 3), ('d', 4), ('e', 5)]) # 实现与方法 1 一样效果
In [32]: d
Out[32]: {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}# 方法 3
In [33]: d = {'a': 1, 'b': 2}
...: d.update([('c', 3), ('d', 4)], e=5) # 实现与方法 1 一样效果
In [34]: d
Out[34]: {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}2. setdefault
如果仅当字典中不存在某个键值对时,才插入到字典中;如果存在,不必插入(也就不会修改键值对)。
这种场景,使用字典自带方法 setdefault:
In [35]: d = {'a': 1, 'b': 2}
In [36]: r = d.setdefault('c', 3) # r: 3
In [37]: r
Out[37]: 3
In [38]: d
Out[38]: {'a': 1, 'b': 2, 'c': 3}
In [39]: r = d.setdefault('c', 33) # r:3,已经存在 'c':3 的键值对,所以 setdefault 时 d 无改变
In [40]: r
Out[40]: 3
In [41]: d
Out[41]: {'a': 1, 'b': 2, 'c': 3}3. 字典并集
先来看这个函数 f,为了好理解,显示的给出参数类型、返回值类型,这不是必须的。
In [45]: def f(d: dict) -> dict:
...: return {**d}
...:
In [46]: f({'a': 1, 'b': 2})
Out[46]: {'a': 1, 'b': 2}{**d1, **d2} 实现合并 d1 和 d2,返回一个新字典:
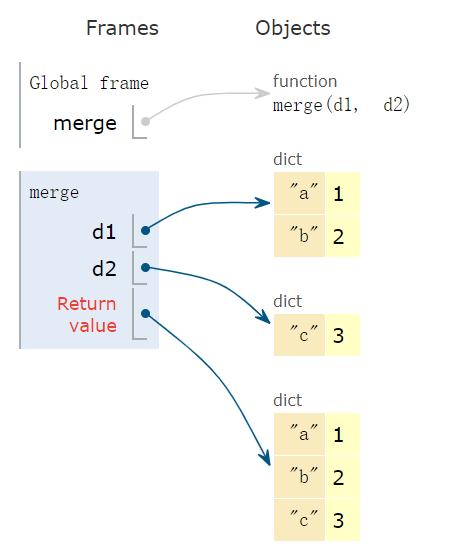
In [47]: def merge(d1, d2):
...: return {**d1, **d2}
In [48]: merge({'a': 1, 'b': 2}, {'c': 3})
Out[48]: {'a': 1, 'b': 2, 'c': 3}以下为示意图:
4. 字典差
In [51]: def difference(d1, d2):
...: return dict([(k, v) for k, v in d1.items() if k not in d2])
In [53]: difference({'a': 1, 'b': 2, 'c': 3}, {'b': 2})
Out[53]: {'a': 1, 'c': 3}5. 按键排序
In [54]: def sort_by_key(d):
...: return sorted(d.items(), key=lambda x: x[0])
...:
In [55]: sort_by_key({'a':3,'b':1,'c':2})
Out[55]: [('a', 3), ('b', 1), ('c', 2)]sorted 函数返回列表,元素为 tuple:
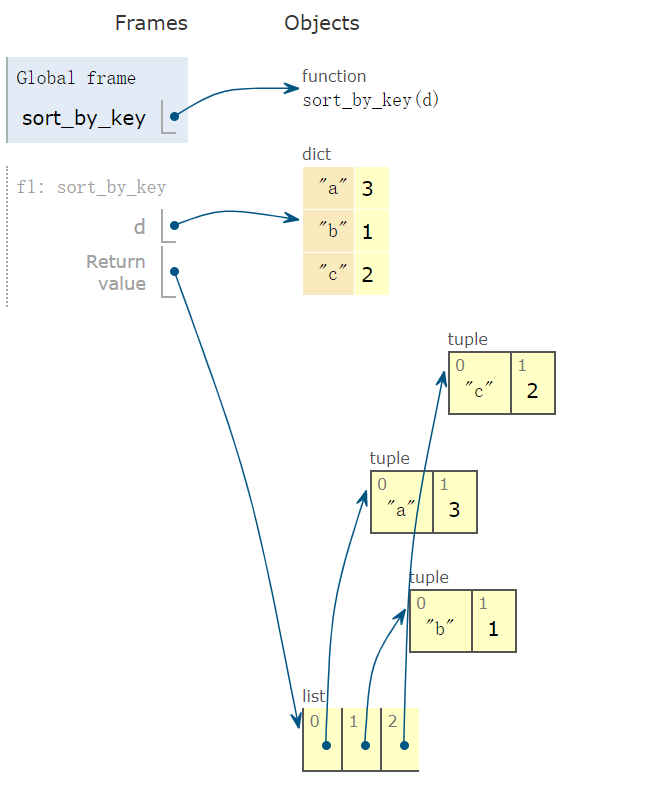
6. 按值排序
与按照键排序原理相同,按照值排序时,key 函数定义为按值(x[1])比较。
为照顾小白,解释为什么是 x[1]。
d.items() 返回元素为 (key, value) 的可迭代类型(Iterable),key 函数的参数 x 便是元素 (key, value),所以 x[1] 取到字典的值。
In [59]: def sort_by_value(d):
...: return sorted(d.items(), key=lambda x: x[1])
...:
In [60]: sort_by_value({'a': 3, 'b': 1, 'c': 2})
Out[60]: [('b', 1), ('c', 2), ('a', 3)]7. 最大键
通过 keys 拿到所有键,获取最大键,返回 (最大键, 值) 的元组
In [68]: def max_key(d):
...: if len(d) == 0:
...: return []
...: max_key = max(d.keys())
...: return (max_key, d[max_key])
In [69]: max_key({'a': 3, 'c': 3, 'b': 2})
Out[69]: ('c', 3)8. 最大字典值
最大值的字典,可能有多对:
In [70]: def max_key(d):
...: if len(d) == 0:
...: return []
...: max_val = max(d.values())
...: return [(key, max_val) for key in d if d[key] == max_val]
...:
In [71]: max_key({'a': 3, 'c': 3, 'b': 2})
Out[71]: [('a', 3), ('c', 3)]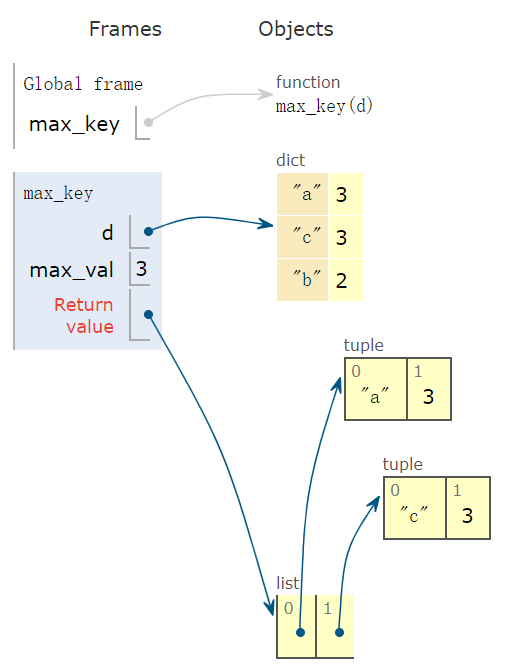
9. 集合最值
找出集合中的最大、最小值,并装到元组中返回:
In [76]: def max_min(s):
...: return (max(s), min(s))
In [77]: max_min({1, 3, 5, 7})
Out[77]: (7, 1)10. 单字符串
若组成字符串的所有字符仅出现一次,则被称为单字符串。
In [73]: def single(string):
...: return len(set(string)) == len(string)
In [74]: single('love_python') # False
Out[74]: False
In [75]: single('python') # True
Out[75]: True11. 更长集合
key 函数定义为按照元素长度比较大小,找到更长的集合:
In [78]: def longer(s1, s2):
...: return max(s1, s2, key=lambda x: len(x))
...:
In [79]: longer({1, 3, 5, 7}, {1, 5, 7}) # {1,3,5,7}
Out[79]: {1, 3, 5, 7}12. 重复最多
在两个列表中,找出重叠次数最多的元素。默认只返回一个。
解决思路:
- 求两个列表的交集
- 遍历交集列表中的每一个元素,
min(元素在列表 1 次数, 元素在列表 2 次数),就是此元素的重叠次数 - 求出最大的重叠次数
In [80]: def max_overlap(lst1, lst2):
...: overlap = set(lst1).intersection(lst2)
...: ox = [(x, min(lst1.count(x), lst2.count(x))) for x in overlap]
...: return max(ox, key=lambda x: x[1])
In [81]: max_overlap([1, 2, 2, 2, 3, 3], [2, 2, 3, 2, 2, 3])
Out[81]: (2, 3)以下三个案例,有些难度,对于新手,可先跳过。
13. topn 键
找出字典前 n 个最大值,对应的键。
导入 Python 内置模块 heapq 中的 nlargest 函数,获取字典中的前 n 个最大值。
key 函数定义按值比较大小:
In [82]: from heapq import nlargest
In [83]: def topn_dict(d, n):
...: return nlargest(n, d, key=lambda k: d[k])
In [84]: topn_dict({'a': 10, 'b': 8, 'c': 9, 'd': 10}, 3)
Out[84]: ['a', 'd', 'c']14. 一键对多值字典
一键对多个值的实现方法 1,按照常规思路,循序渐进:
In [85]: d = {}
...: lst = [(1, 'apple'), (2, 'orange'), (1, 'compute')]
...: for k,v in lst:
...: if k not in d:
...: d[k]=[]
...: d[k].append(v)
In [86]: d
Out[86]: {1: ['apple', 'compute'], 2: ['orange']}以上方法,有一处 if 判断,确认 k 是不是已经在返回结果字典 d 中。
不是很优雅!
可以使用 collections 模块中的 defaultdict,它能创建属于某个类型的自带初始值的字典。使用起来更加方便:
In [87]: from collections import defaultdict
...:
...: d = defaultdict(list)
...: for k, v in lst:
...: d[k].append(v)
In [88]: d
Out[88]: defaultdict(list, {1: ['apple', 'compute'], 2: ['orange']})15. 逻辑上合并字典
案例 3 中合并字典的方法:
In [94]: dic1 = {'x': 1, 'y': 2 }
In [95]: dic2 = {'y': 3, 'z': 4 }
In [96]: merged = {**dic1, **dic2}
In [97]: merged
Out[97]: {'x': 1, 'y': 3, 'z': 4}修改 merged['x']=10,dic1 中的 x 值不变,merged 是重新生成的一个“新字典”。
但是,collections 模块中的 ChainMap 函数却不同,它在内部创建了一个容纳这些字典的列表。使用 ChainMap 合并字典,修改 merged['x']=10 后,dic1 中的 x 值改变。
如下所示:
In [98]: from collections import ChainMap
In [94]: dic1 = {'x': 1, 'y': 2 }
In [95]: dic2 = {'y': 3, 'z': 4 }
In [99]: merged = ChainMap(dic1,dic2)
In [100]: merged
Out[100]: ChainMap({'x': 1, 'y': 2}, {'y': 3, 'z': 4})
In [101]: merged['x'] = 10
In [102]: dic1 # 改变,共用内存的结果
Out[102]: {'x': 10, 'y': 2}16. 小结
今天与大家一起学习了字典和集合相关的 15 个案例,难度有高有低。
比如要区分逻辑上合并字典,与普通的合并字典,有什么不一样;key 函数一般会与 lambda 匿名函数结合使用。经过学习这些案例,相信会掌握。
仍然建议码一码,理解会更加深刻。
欢迎关注我公众号:AI悦创,有更多更好玩的等你发现!
公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh

更新日志
1c35a-于aed17-于d6c88-于c919f-于