
比赛问卷不够?Python来凑!
1. 需求😲
你好,我是悦创。
对于问卷调查的文章其实,我之前就写过了。
但是鉴于,我学员又开始需要,所以我再写一篇。
1.1 缘起😳


问卷 Excel:https://github.com/AndersonHJB/BornforthisData/tree/main/blog/2023/7month/01
详情🔎
| 序号 | 提交答卷时间 | 所用时间 | 来源 | 来源详情 | 来自IP | 1、您的性别是 | 2、您的年龄 | 3、您是否看过梁弄镇明湖村的宣传视频? | 4、您会为采摘樱桃或杨梅,专程出远门到樱桃园和杨梅山上吗? | 5、在采摘杨梅和樱桃后,您是否愿意购买礼盒装的杨梅或樱桃作为伴手礼带回家中? | 6、您在考虑杨梅或樱桃采摘的同时,会注重当地其他文创产品吗? | 7、如果在四明山上建设帐篷民宿,您愿意花钱留在山中帐篷民宿中过夜吗? | 8、如果您要当乡镇旅游,以下哪个项目较吸引您呢? |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2023/7/13 16:06:36 | 20秒 | 微信 | N/A | 223.104.164.115(浙江-嘉兴) | 女 | 22岁以下 | 否 | 如果是周边地区才会考虑 | 愿意 | 会 | 愿意 | 水果采摘┋山腰处帐篷民宿┋网红打卡点┋山地越野车┋青团等当地特色小吃┋徒步远足┋情景剧本杀 |
| 2 | 2023/7/13 16:13:05 | 17秒 | 微信 | N/A | 39.187.103.53(浙江-宁波) | 女 | 22岁以下 | 是 | 如果是周边地区才会考虑 | 愿意 | 会 | 愿意 | 水果采摘┋山腰处帐篷民宿┋网红打卡点┋山地越野车┋青团等当地特色小吃┋徒步远足┋情景剧本杀 |
| 3 | 2023/7/13 16:15:30 | 26秒 | 微信 | N/A | 117.136.111.77(浙江-杭州) | 女 | 22岁以下 | 是 | 会 | 愿意 | 会 | 愿意 | 水果采摘┋山腰处帐篷民宿┋网红打卡点┋山地越野车┋青团等当地特色小吃┋徒步远足┋情景剧本杀 |
| 4 | 2023/7/13 16:19:23 | 29秒 | 微信 | N/A | 223.104.160.107(浙江-杭州) | 女 | 22岁以下 | 否 | 如果是周边地区才会考虑 | 愿意 | 不会 | 不愿意 | 水果采摘┋网红打卡点┋青团等当地特色小吃 |
| 5 | 2023/7/13 16:20:14 | 26秒 | 微信 | N/A | 39.144.103.237(上海-上海) | 女 | 22岁以下 | 否 | 不会 | 不愿意 | 不会 | 不愿意 | 山腰处帐篷民宿┋网红打卡点┋青团等当地特色小吃┋情景剧本杀 |
| 6 | 2023/7/13 16:21:23 | 78秒 | 微信 | N/A | 36.28.75.226(浙江-杭州) | 女 | 22岁以下 | 否 | 不会 | 愿意 | 不会 | 不愿意 | 水果采摘┋网红打卡点┋山地越野车┋青团等当地特色小吃 |
| 7 | 2023/7/13 16:22:58 | 21秒 | 微信 | N/A | 223.104.164.1(浙江-嘉兴) | 男 | 22岁以下 | 否 | 如果是周边地区才会考虑 | 愿意 | 不会 | 愿意 | 水果采摘┋山腰处帐篷民宿┋网红打卡点┋山地越野车┋青团等当地特色小吃┋徒步远足┋情景剧本杀 |
| 8 | 2023/7/13 16:23:00 | 18秒 | 微信 | N/A | 39.188.200.186(浙江-宁波) | 女 | 22岁以下 | 否 | 如果是周边地区才会考虑 | 愿意 | 会 | 愿意 | 山腰处帐篷民宿┋网红打卡点┋青团等当地特色小吃┋徒步远足┋情景剧本杀 |
| 9 | 2023/7/14 16:23:52 | 20秒 | 手机提交 | 直接访问 | 117.136.111.38(浙江-杭州) | 女 | 22岁以下 | 是 | 会 | 愿意 | 会 | 愿意 | 水果采摘┋山腰处帐篷民宿┋网红打卡点┋山地越野车┋青团等当地特色小吃┋徒步远足┋情景剧本杀 |
| 10 | 2023/7/14 16:26:15 | 136秒 | 手机提交 | 直接访问 | 117.30.123.77(福建-厦门) | 男 | 45-60岁 | 否 | 如果是周边地区才会考虑 | 不愿意 | 会 | 愿意 | 水果采摘┋山腰处帐篷民宿┋网红打卡点┋山地越野车┋青团等当地特色小吃┋徒步远足┋情景剧本杀 |
1.2 "变本加厉"😅

2. 解决步骤💁
2.1 构建你的问卷
也就是使用发布问卷的平台,发布你的问卷,并收集真实问卷。
Why?
因为,我们不能越过这一步,不然我们得自己脑补🧠抽象这些对应生成 Excel 格式等。
2.2 后台下载你收集的问卷
其实,我在前面也已经给了你导出的问卷下载链接🔗,你可以自学下载⏬跟着教程学习。
3.3 分析🧐你得到的问卷
从问卷每一列的数据中得到我们需要使用 Python 批量生成的数据。
3. 实现
3.0 实现逻辑
先实现问卷中的每一列,熟知每一列之后,我们使用 Python 来构造我们的数据,毕竟用 Python 做数据,我们是认真的。
3.1 序号的实现
# 序号
serial_number = list(range(1000))
print(serial_number)3.2 交答卷时间
# 提交答卷时间
from datetime import datetime, timedelta
def generate_random_dates(start_date, end_date, num_dates):
date_format = "%Y/%m/%d %H:%M:%S"
start_datetime = datetime.strptime(start_date, date_format)
end_datetime = datetime.strptime(end_date, date_format)
delta = end_datetime - start_datetime
if delta.total_seconds() <= 0:
raise ValueError("End date must be later than start date.")
random_dates = set()
while len(random_dates) < num_dates:
random_interval = random.randint(0, int(delta.total_seconds()))
random_datetime = start_datetime + timedelta(seconds=random_interval)
random_dates.add(random_datetime)
formatted_dates = [date.strftime(date_format) for date in random_dates]
return formatted_dates
start_date = "2023/07/13 00:00:00"
end_date = "2023/07/19 23:59:59"
num_dates = 100
random_dates = generate_random_dates(start_date, end_date, num_dates)
lst = []
for date in random_dates:
lst.append(date)
print(len(set(lst)) == len(lst)) # 证明是否有重复的日期,True 则全为真# 优化日期生成的时间范围
import random
from datetime import datetime, timedelta
from pprint import pprint
def generate_random_dates(start_date, end_date, num_dates):
date_format = "%Y/%m/%d %H:%M:%S"
start_datetime = datetime.strptime(start_date, date_format)
end_datetime = datetime.strptime(end_date, date_format)
delta = end_datetime - start_datetime
if delta.total_seconds() <= 0:
raise ValueError("End date must be later than start date.")
random_dates = set()
while len(random_dates) < num_dates:
random_interval = random.randint(0, int(delta.total_seconds()))
random_datetime = start_datetime + timedelta(seconds=random_interval)
# Adjust the hour to fit the 5:00 to 24:00 range
if 0 <= random_datetime.hour < 5:
random_datetime += timedelta(hours=5 - random_datetime.hour)
random_dates.add(random_datetime)
formatted_dates = [date.strftime(date_format) for date in random_dates]
return formatted_dates
start_date = "2023/07/13 05:00:00" # Change the start time to 5:00
end_date = "2023/07/19 23:59:59"
num_dates = 100
random_dates = generate_random_dates(start_date, end_date, num_dates)
lst = []
for date in random_dates:
lst.append(date)
lst.sort()
pprint(lst)3.3 填写问卷所用时间
# 所用时间
import random
filling_time = random.randint(40, 80)
print(f"{filling_time}秒")3.4 来源
# 来源
source_origins = ["微信", "手机提交"]
random.shuffle(source_origins)
print(source_origins)3.5 来源详情
一开始我是下面的操作方法:
# 来源详情
source_detail = ["N/A", "直接访问"]
print(source_detail)但是,一细品,哎,不对。这个部分的数据需要和来源对应。
你会怎么办?——我直接选择使用字典实现,代码如下:
source_origins = ["微信", "手机提交"]
random.shuffle(source_origins)
r = source_origins[0]
# 来源详情
source_detail = {"微信": "N/A", "手机提交": "直接访问"}
print(source_detail[r])3.6 IP 来自 IP
3.6.1 寻找数据源
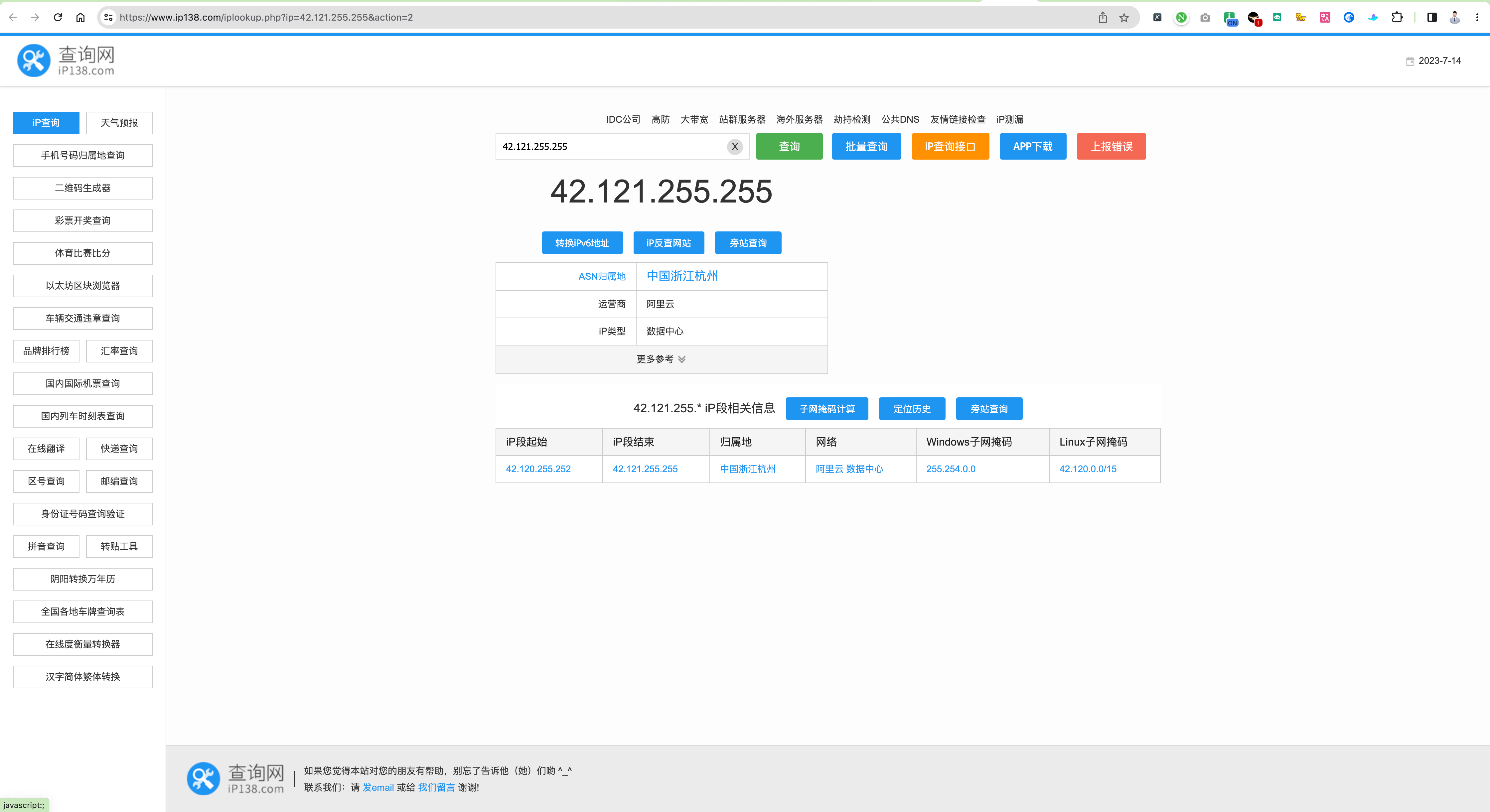
因为需要真实 IP,我是查了又差,第一次找到如下:
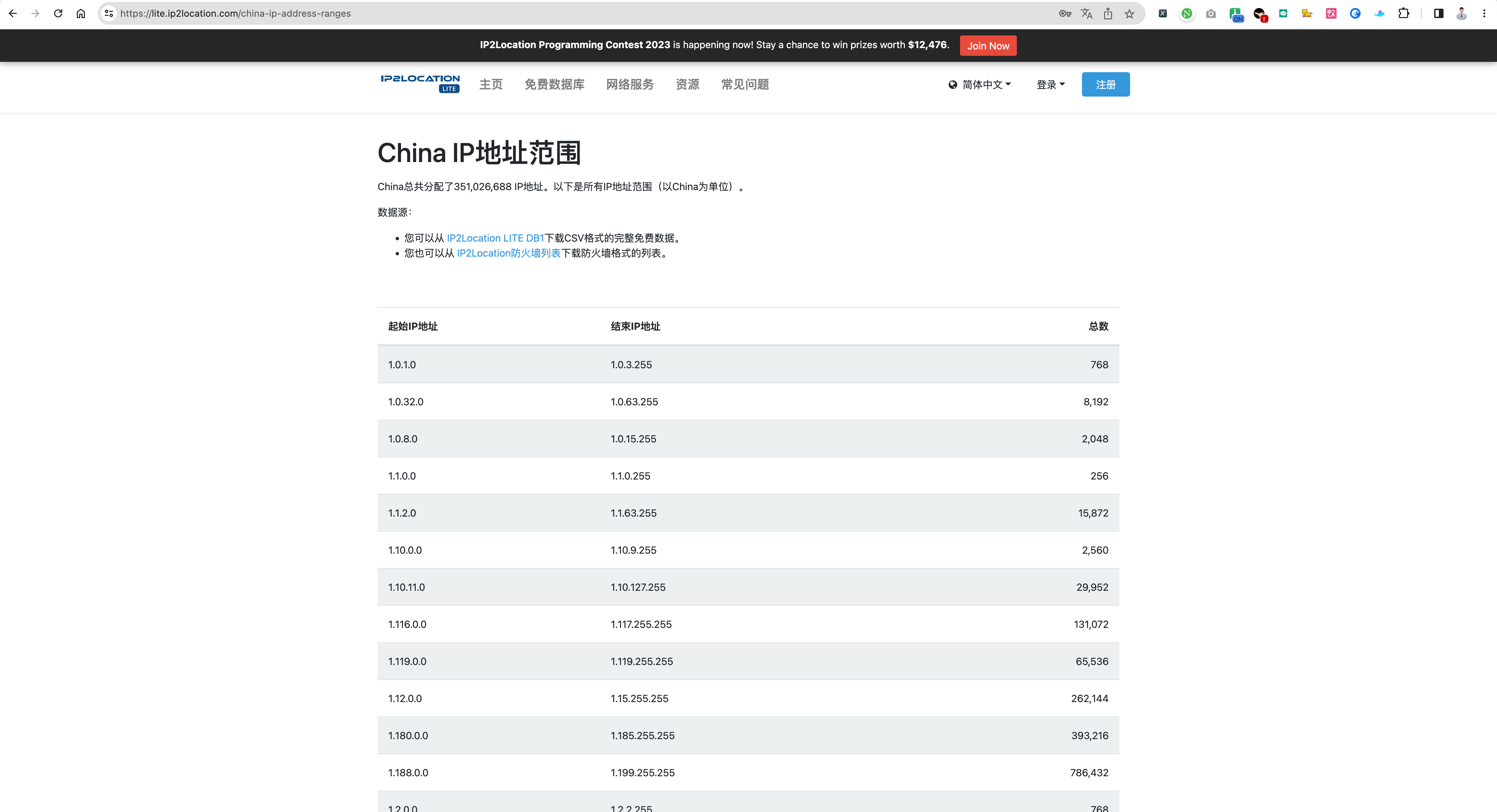
上面的数据范围不错,但是有问题:
- 查询虽然是中国大陆真实 ip,但是没有对应的地理位置的区分,要是一个个 copy 查询的话简直就太酸爽了;
- 我们知道范围就能生成,但是需要 IP 和地区都要,所以弃之~
接着,我又继续找呀~找呀~找~
找到下面的页面:
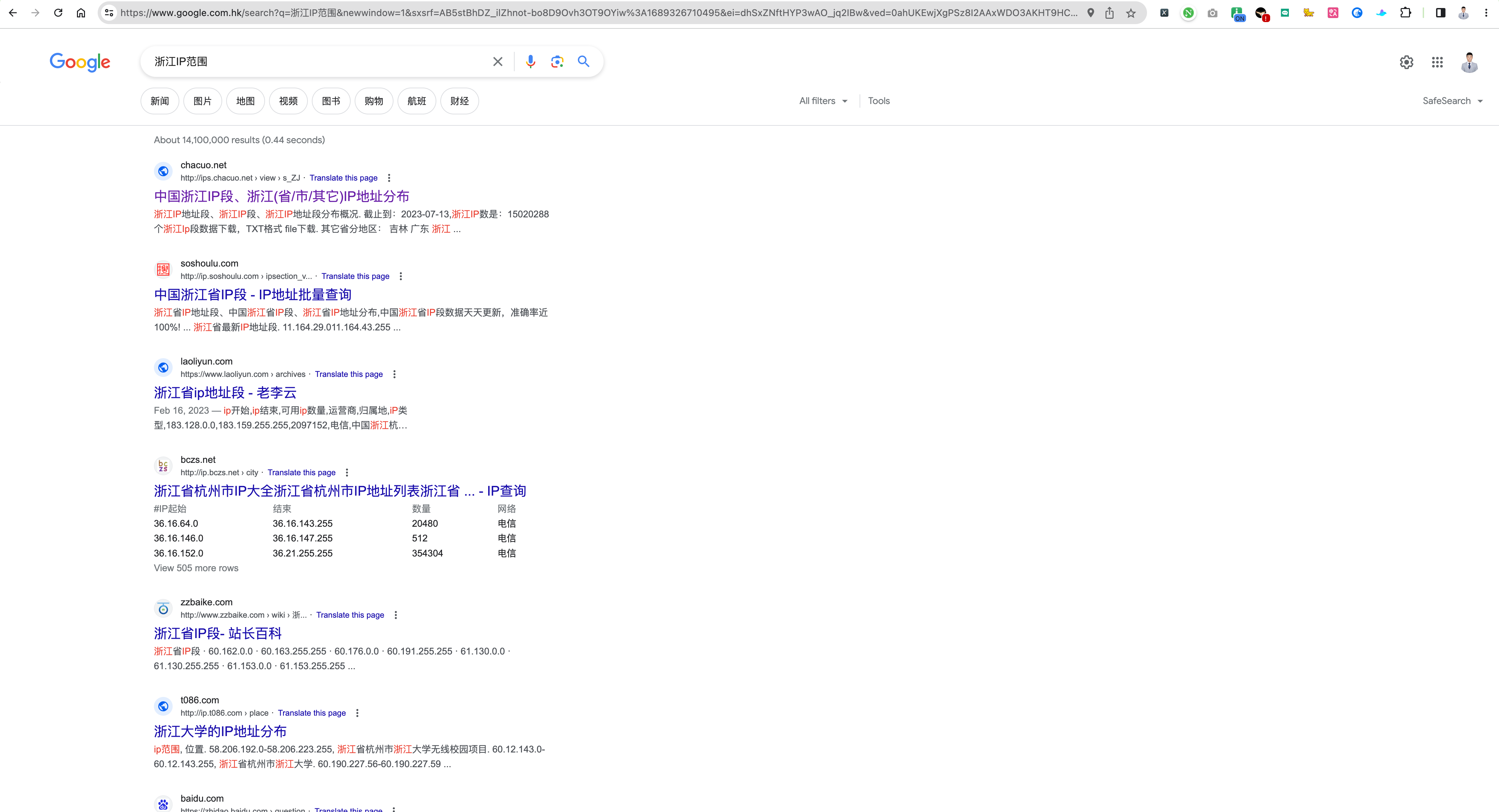
果不其然,被我挖到了,不对是找到了!
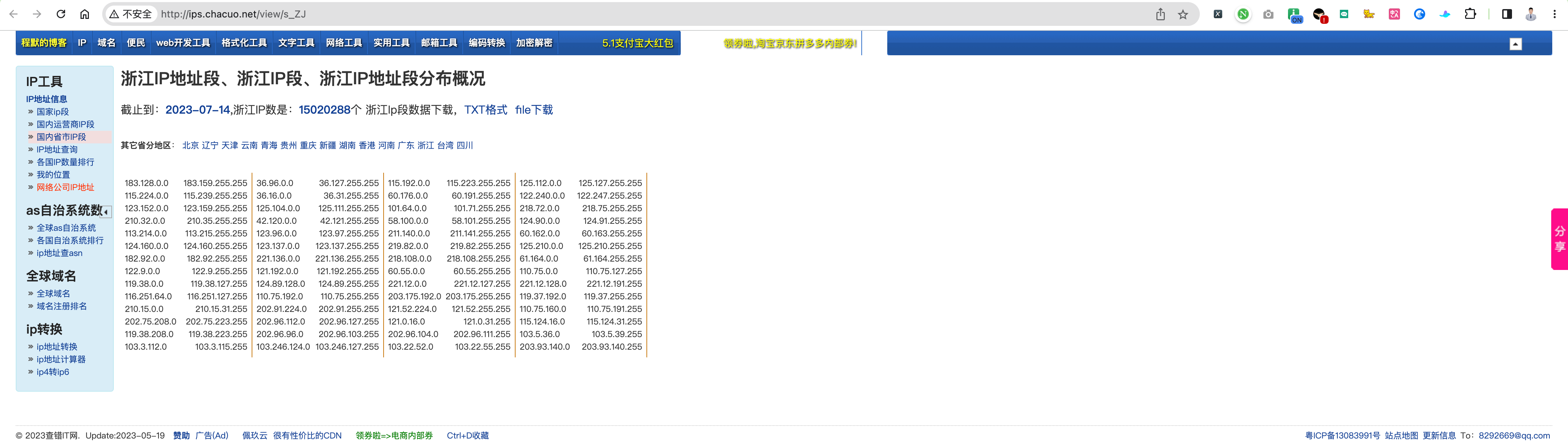
3.6.2 验证 IP
但是,对不对呢?
于是,我又开始挖呀~挖呀~挖~
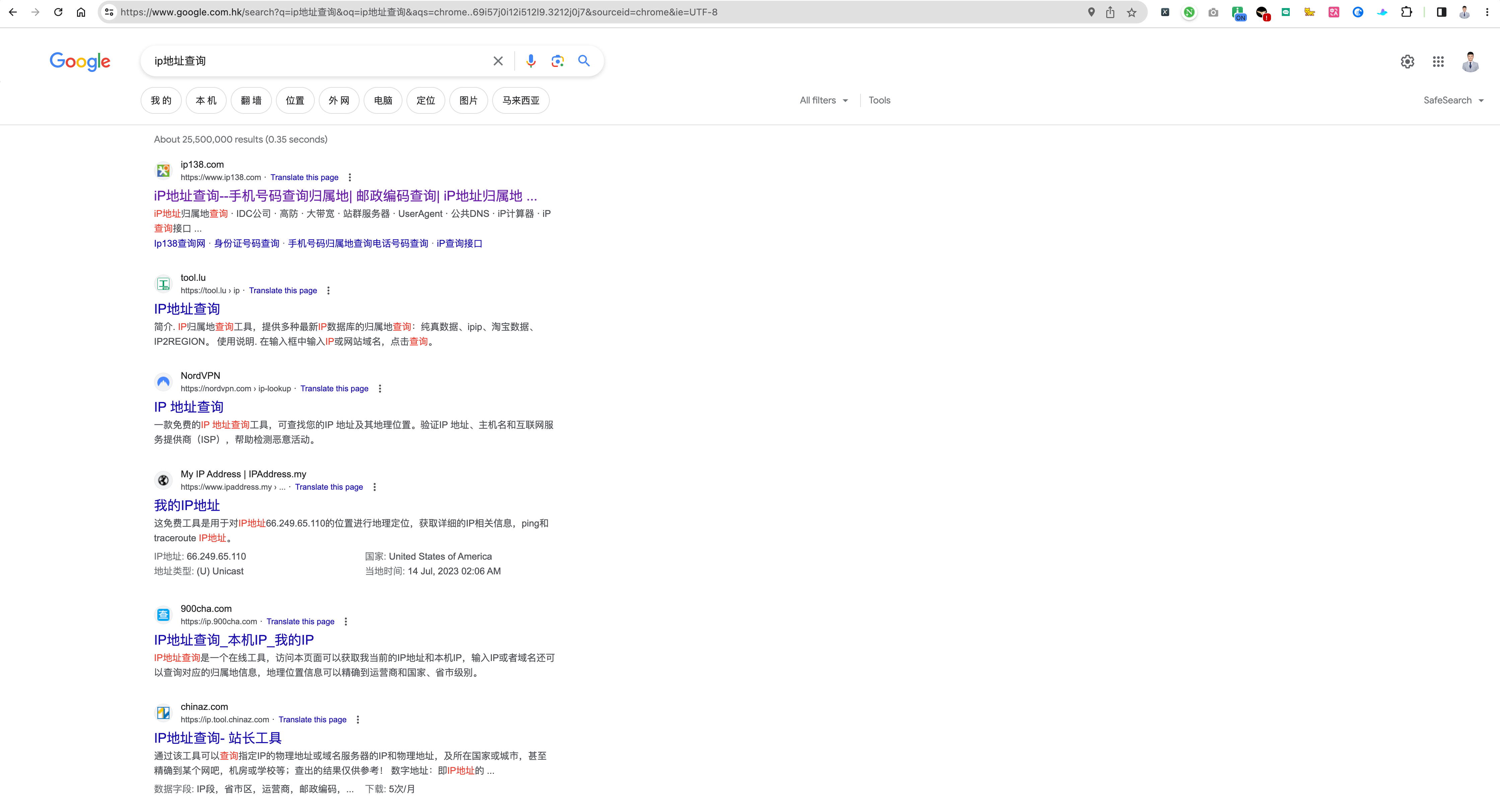
又被我挖到了,我现在点进去了。
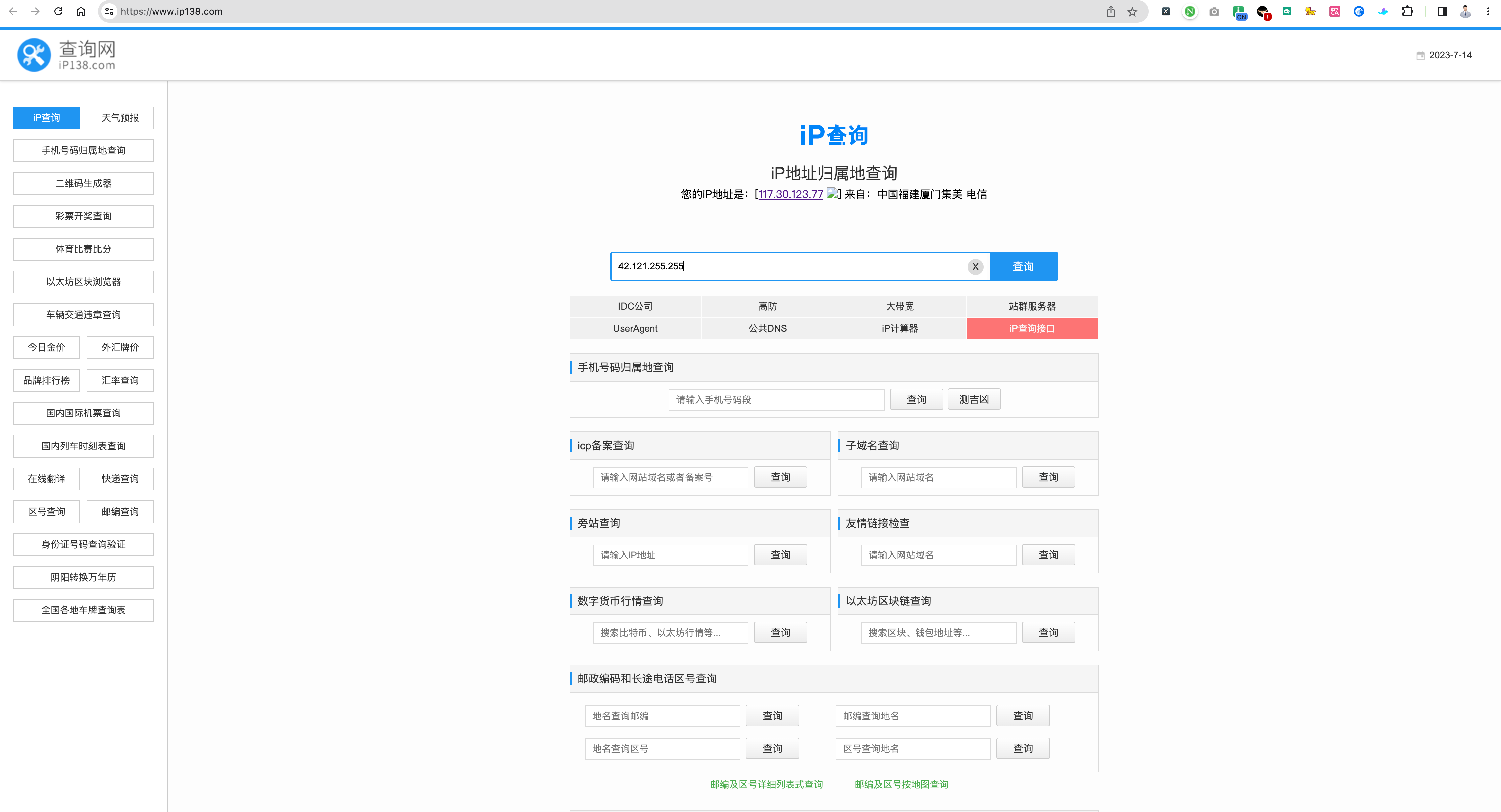
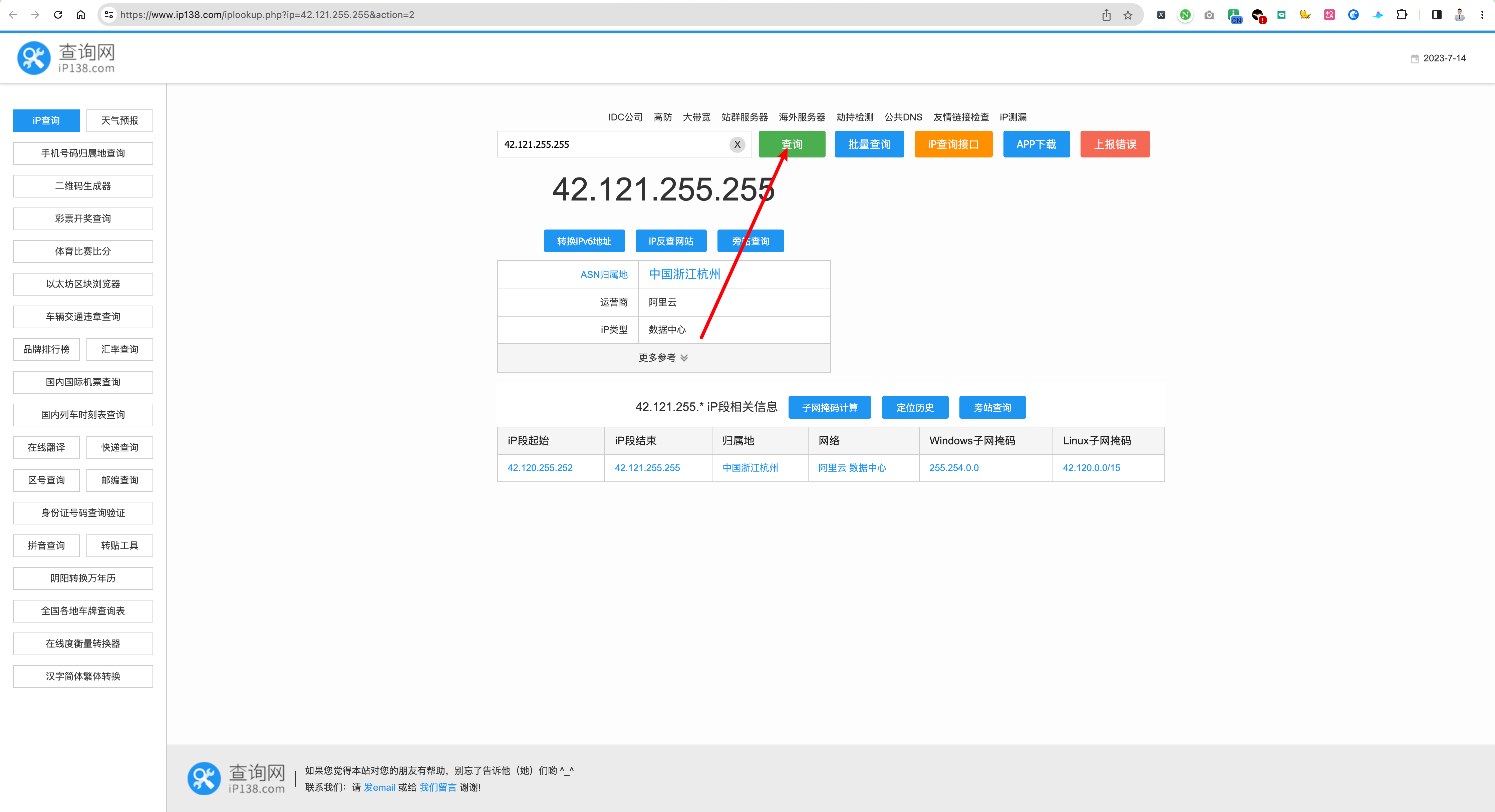
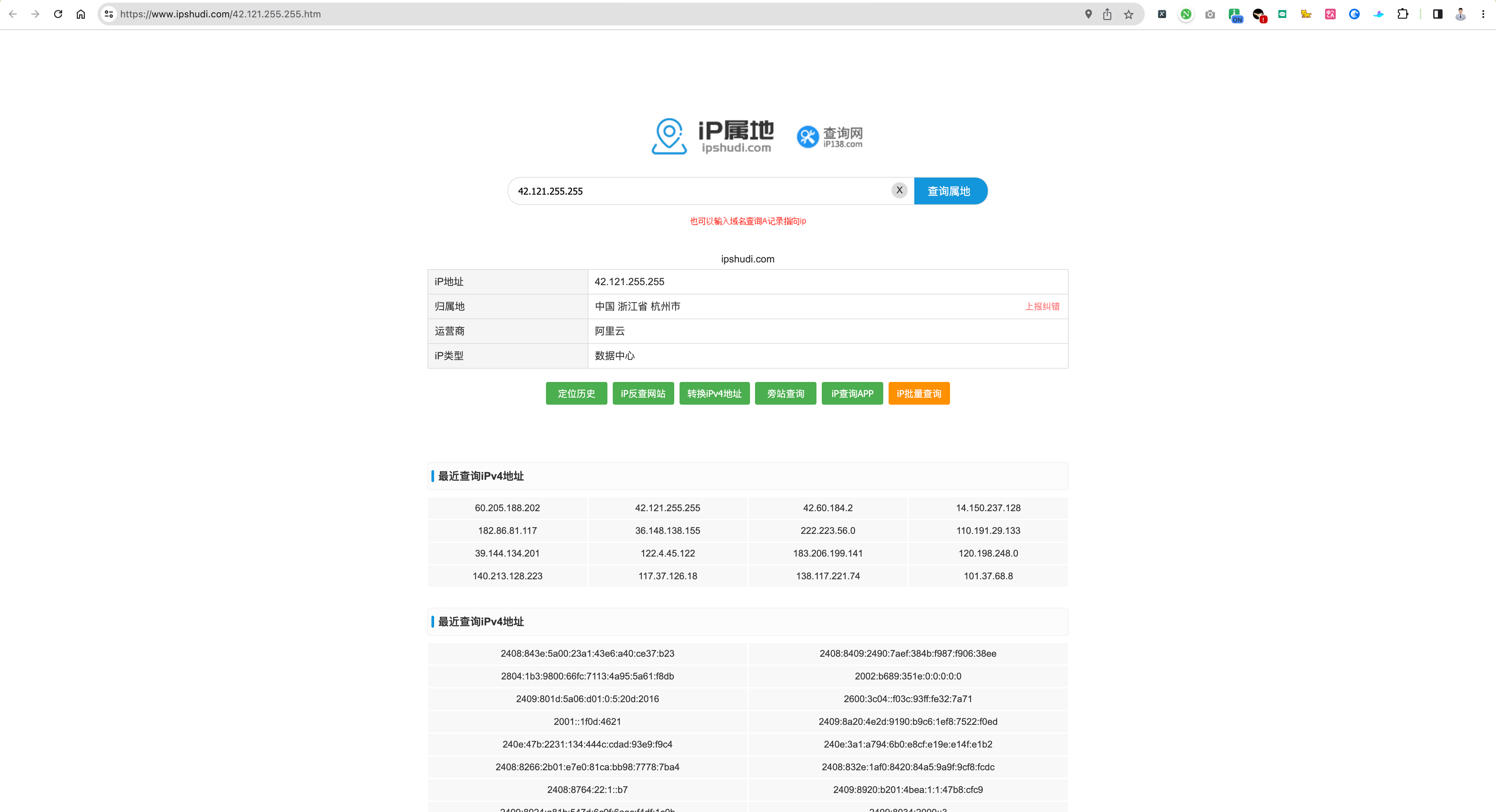
可以看见,最终的网页就是上面“4. 继续跳转” 的部分图片。
并且,我们也确定没有找错网站。「虽然有几个漏网之鱼的的 IP,但是也能接受」
3.6.3 Python 如何验证 IP?
对于上面,我们使用网站来验证 IP,但是 Python 应该如何实现,是一个问题。
此时,询问 ChatGPT 给我的答案如下:

但是,我没有时间验证 ChatGPT 回复答案的真实性或者准确说是否对我适用。我原本是搞过爬虫的,此时也不例外,我依然首选爬虫来解决。
使用爬虫就得知道,这个网站是否有加密🔐,如果加密要解决也是很费时间的,如果出现这样的问题,我会去测试 AI 给我的解决方法。
其实,也没必要。IP 地址查询的网站很多,不差这一个。加密咱们就换。
接着我就开始研究 IP 爬虫,首先检查目标结果是否直接存在于网页原代码中,这个验证很简单:
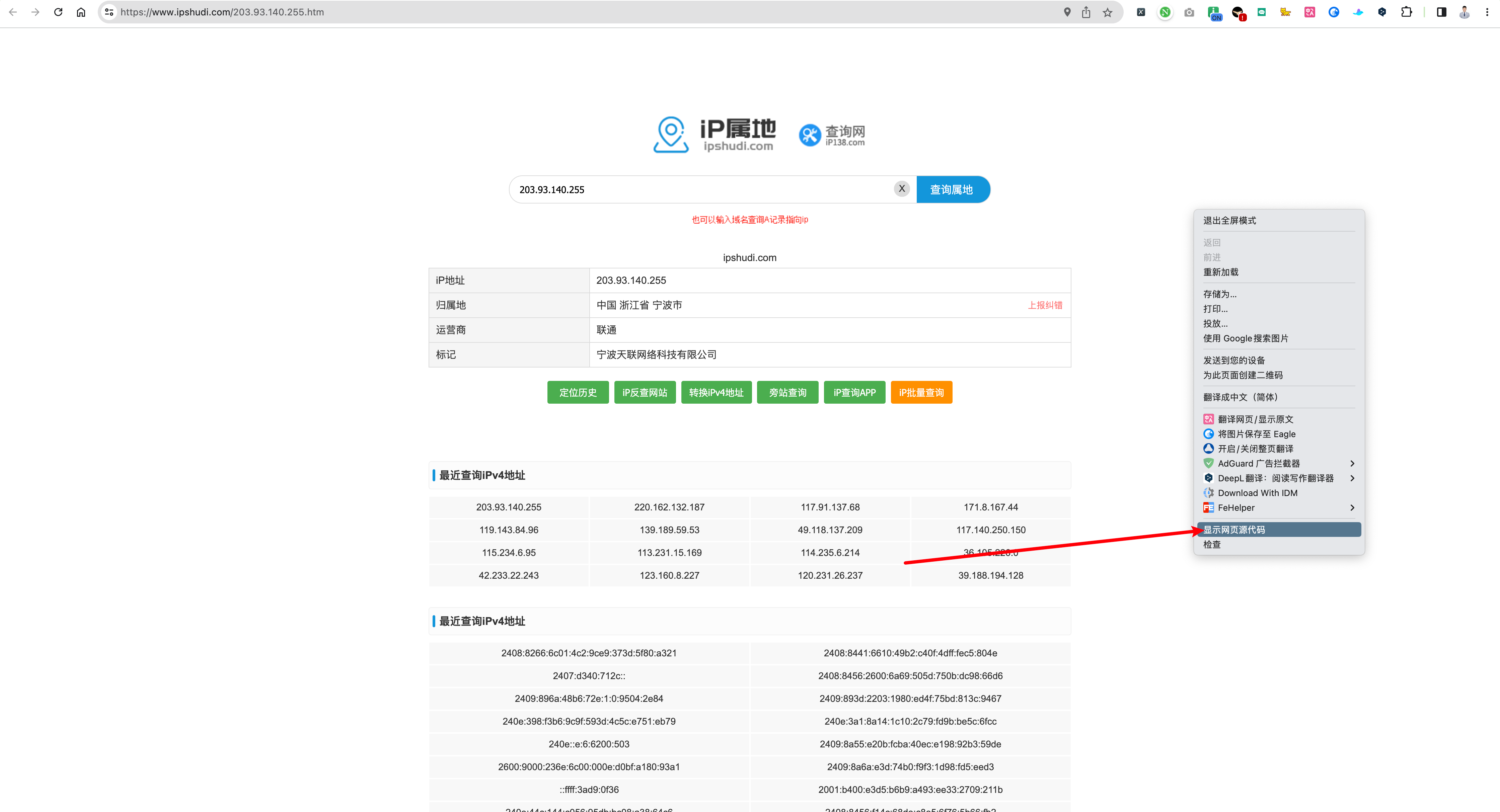
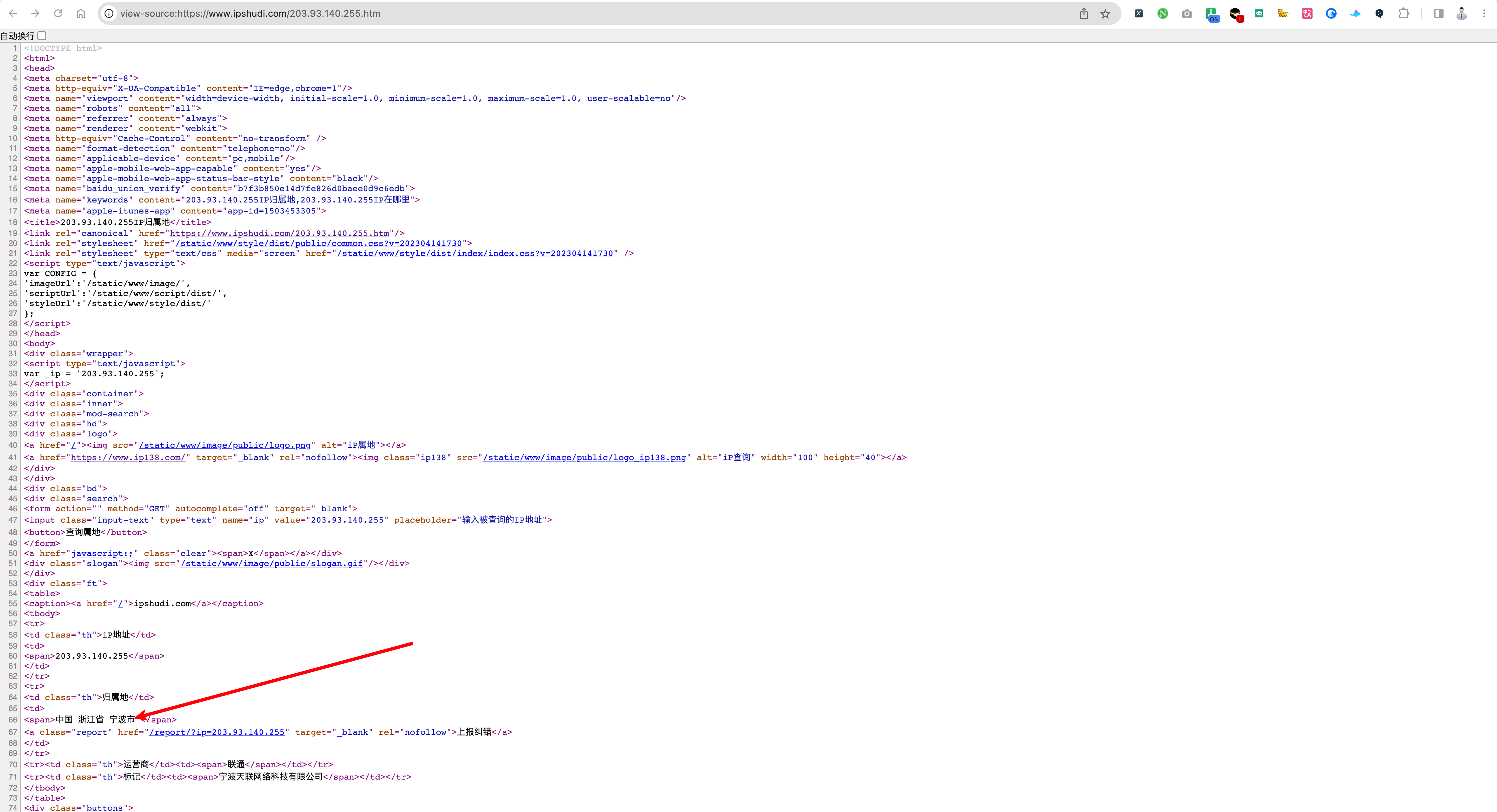
nice,存在网页源代码。
def ip_search(ip: str):
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
url = "https://www.ipshudi.com/{ip}.htm".format(ip=ip)
response = requests.get(url, headers=headers)
# print(response.text)
soup = BeautifulSoup(response.text, "lxml")
ip_address = soup.select(".mod-search table tbody tr td span")[1].text
# print(r)
return ip_address3.6.4 批量 IP 生成
def generate_ip_range(start_ip, end_ip):
start = list(map(int, start_ip.split('.')))
end = list(map(int, end_ip.split('.')))
ip_range = []
while start <= end:
ip = '.'.join(map(str, start))
ip_range.append(ip)
start[3] += 1
for i in range(3, 0, -1):
if start[i] == 256:
start[i] = 0
start[i - 1] += 1
return ip_range
ip_ranges = [
("183.128.0.0", "183.159.255.255", 3),
# ("36.96.0.0", "36.127.255.255", 3),
("115.192.0.0", "115.223.255.255", 3),
# # ... (将所有IP范围添加到此列表中)
("203.93.140.0", "203.93.140.255", 3)
]
ip_list = []
for start_ip, end_ip, count in ip_ranges:
ips = generate_ip_range(start_ip, end_ip)
ip_list.extend(ips[:count])
# 打印IP列表
for idnex, ip in enumerate(ip_list):
# print(ip)
# ip_search(ip)
print(f"{ip}({ip_search(ip)})")
# 223.104.164.115(浙江-嘉兴)
# 将IP列表保存到文件
# with open('ip_list.txt', 'w') as file:
# for ip in ip_list:
# file.write(ip + '\n')3.7 性别
# 您的性别是
genders = ["男", "女"]
random.shuffle(genders)
print(genders)3.7 年龄
# 您的年龄
# ages = ["22岁以下", "22-45岁", "45-60岁", "60岁以上"]
ages1 = ["22岁以下"] * 6
ages2 = ["22-45岁"] * 3
ages3 = ["45-60岁"] * 1
ages4 = ["60岁以上"] * 1
ages = ages1 + ages2 + ages3 + ages4
random.shuffle(ages)
print(ages)import random
def generate_age_data(n):
age_below_22 = ["22岁以下"] * int(n*0.4) # 40%的数据为"22岁以下"
age_22_45 = ["22-45岁"] * int(n*0.4) # 40%的数据为"22-45岁"
age_45_60 = ["45-60岁"] * int(n*0.1) # 10%的数据为"45-60岁"
age_above_60 = ["60岁以上"] * int(n*0.1) # 10%的数据为"60岁以上"
# 如果n不是10的倍数,会有余数需要额外处理
remainder = n - len(age_below_22) - len(age_22_45) - len(age_45_60) - len(age_above_60)
for _ in range(remainder):
age_above_60.append("60岁以上")
age_data = age_below_22 + age_22_45 + age_45_60 + age_above_60
random.shuffle(age_data)
return age_data
ages = generate_age_data(100)
print(ages)3.8 您是否看过梁弄镇明湖村的宣传视频?
# 您是否看过梁弄镇明湖村的宣传视频?
judgment_vide = ["是", "否"]
random.shuffle(judgment_vide)
print(judgment_vide)import random
def generate_judgment_data(n):
watched = ["是"] * int(n * 0.6) # 60%的数据为"是"
not_watched = ["否"] * (n - len(watched)) # 剩下的数据为"否"
judgment_data = watched + not_watched
random.shuffle(judgment_data) # 将数据随机排序
return judgment_data
judgment_vide = generate_judgment_data(100)
print(judgment_vide)3.9 您会为采摘樱桃或杨梅,专程出远门到樱桃园和杨梅山上吗?
# 您会为采摘樱桃或杨梅,专程出远门到樱桃园和杨梅山上吗?
judgment_yanmei = ["会", "如果是周边地区才会考虑", "不会"]
random.shuffle(judgment_yanmei)
print(judgment_yanmei)import random
def generate_trip_decision_data(n):
will_go = ["会"] * int(n * 0.3) # 30%的数据为"会"
consider_if_nearby = ["如果是周边地区才会考虑"] * int(n * 0.5) # 50%的数据为"如果是周边地区才会考虑"
# 剩下的数据为"不会"
will_not_go = ["不会"] * (n - len(will_go) - len(consider_if_nearby))
trip_decision_data = will_go + consider_if_nearby + will_not_go
random.shuffle(trip_decision_data) # 将数据随机排序
return trip_decision_data
judgment_yanmei = generate_trip_decision_data(100)
print(judgment_yanmei)3.10 在采摘杨梅和樱桃后,您是否愿意购买礼盒装的杨梅或樱桃作为伴手礼带回家中?
# 5、在采摘杨梅和樱桃后,您是否愿意购买礼盒装的杨梅或樱桃作为伴手礼带回家中?
gift_box = ["愿意", "不愿意"]
random.shuffle(gift_box)
print(gift_box)import random
def generate_gift_box_data(n):
willing = ["愿意"] * int(n * 0.7) # 70%的数据为"愿意"
not_willing = ["不愿意"] * (n - len(willing)) # 剩下的数据为"不愿意"
gift_box_data = willing + not_willing
random.shuffle(gift_box_data) # 将数据随机排序
return gift_box_data
gift_box = generate_gift_box_data(100)
print(gift_box)3.11 您在考虑杨梅或樱桃采摘的同时,会注重当地其他文创产品吗?
import random
def generate_wenchuang_data(n):
willing = ["会"] * int(n * 0.8) # 70%的数据为"会"
not_willing = ["不会"] * (n - len(willing)) # 剩下的数据为"不会"
wenchuang_data = willing + not_willing
random.shuffle(wenchuang_data) # 将数据随机排序
return wenchuang_data
wenchuang_data = generate_wenchuang_data(100)
print(wenchuang_data)3.12 如果在四明山上建设帐篷民宿,您愿意花钱留在山中帐篷民宿中过夜吗?
import random
def generate_minsu_data(n):
willing = ["愿意"] * int(n * 0.8)
not_willing = ["不愿意"] * (n - len(willing)) # 剩下的数据为"不愿意"
minsu_data = willing + not_willing
random.shuffle(minsu_data) # 将数据随机排序
return minsu_data
minsu_data = generate_minsu_data(100)
print(minsu_data)3.13 如果您要当乡镇旅游,以下哪个项目较吸引您呢?
import random
def generate_tourist_activities():
activities = ["水果采摘", "山腰处帐篷民宿", "网红打卡点", "山地越野车", "青团等当地特色小吃", "徒步远足",
"情景剧本杀"]
# 随机选择的活动数量
num_activities = random.randint(1, len(activities))
# 随机选择活动
selected_activities = random.sample(activities, num_activities)
# 将活动组合成一个字符串
itinerary = '┋'.join(selected_activities)
return itinerary
# 生成随机旅游活动组合
print(generate_tourist_activities())4. 汇总代码
import random
import time
import os
import openai
from dotenv import load_dotenv
from submit_time import generate_random_dates
from age import generate_age_data
from data import generate_judgment_data_video, generate_trip_decision_data_yanmei, generate_gift_box_data, \
generate_wenchuang_data, generate_minsu_data, generate_tourist_activities
import xlwt
from ip_engin import ip_search, ip_info
load_dotenv()
openai.api_key = os.getenv("KEY")
total_num = 100
# 序号
# serial_number = list(range(1, total_num + 1))
# print(serial_number)
# 提交时间
submit_dates = generate_random_dates(start_date="2023/07/13 05:00:00", end_date="2023/07/19 23:59:59",
num_dates=total_num)
def openai_ip(ip):
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你会把收到的信息,翻译成中文"},
{"role": "user", "content": f"{ip}"}
]
)
return completion.choices[0].message["content"]
# 填写问卷所用的时间
def filling_time():
return f"{random.randint(40, 80)}秒"
# 来源
def source_origins():
source_origins = ["微信", "手机提交"]
random.shuffle(source_origins)
return random.choice(source_origins)
# 来源详情
source_detail = {"微信": "N/A", "手机提交": "直接访问"}
# r = source_origins()
# print(source_detail[r])
# ip 地址
ip_list = open("ip_test/ip_list.txt", "r")
ip_lst = ip_list.readlines()
# print(ip_lst)
# 你的性别
def gender():
genders = ["男", "女"]
random.shuffle(genders)
return random.choice(genders)
ages = generate_age_data(total_num)
# print(ages)
# video
videos = generate_judgment_data_video(total_num)
# print(videos)
# 樱桃、杨梅
judgment_yanmei = generate_trip_decision_data_yanmei(total_num)
# print(judgment_yanmei)
gift_boxs = generate_gift_box_data(total_num)
# print(gift_boxs)
wenchuang_data = generate_wenchuang_data(total_num)
# print(wenchuang_data)
minsu_data = generate_minsu_data(total_num)
# print(minsu_data)
# 生成随机旅游活动组合
# print(generate_tourist_activities())
# save excel
head_data = [
"序号",
"提交答卷时间",
"所用时间",
"来源",
"来源详情",
"来自IP",
"1、您的性别是",
"2、您的年龄",
"3、您是否看过梁弄镇明湖村的宣传视频?",
"4、您会为采摘樱桃或杨梅,专程出远门到樱桃园和杨梅山上吗?",
"5、在采摘杨梅和樱桃后,您是否愿意购买礼盒装的杨梅或樱桃作为伴手礼带回家中?",
"6、您在考虑杨梅或樱桃采摘的同时,会注重当地其他文创产品吗?",
"7、如果在四明山上建设帐篷民宿,您愿意花钱留在山中帐篷民宿中过夜吗?",
"8、如果您要当乡镇旅游,以下哪个项目较吸引您呢?",
]
wb = xlwt.Workbook()
sheet = wb.add_sheet("sheet")
for index, head in enumerate(head_data):
sheet.write(0, index, head)
for row in range(1, total_num):
sheet.write(row, 0, row)
sheet.write(row, 1, submit_dates[row])
sheet.write(row, 2, filling_time())
# 来源
source_origin = source_origins()
sheet.write(row, 3, source_origin)
sheet.write(row, 4, source_detail[source_origin])
# ip = random.choice(ip_lst)
time.sleep(6)
ip_d = ip_info(random.choice(ip_lst).strip())
ip = openai_ip(ip_d)
print(ip)
sheet.write(row, 5, ip)
sheet.write(row, 6, gender())
sheet.write(row, 7, ages[row])
sheet.write(row, 8, videos[row])
sheet.write(row, 9, judgment_yanmei[row])
sheet.write(row, 10, gift_boxs[row])
sheet.write(row, 11, wenchuang_data[row])
sheet.write(row, 12, minsu_data[row])
sheet.write(row, 13, generate_tourist_activities())
wb.save("潜在旅客视角谈宁波余姚梁弄镇明湖村旅游规划调查问卷.xls")# 优化日期生成的时间范围
import random
from datetime import datetime, timedelta
from pprint import pprint
def generate_random_dates(start_date, end_date, num_dates):
date_format = "%Y/%m/%d %H:%M:%S"
start_datetime = datetime.strptime(start_date, date_format)
end_datetime = datetime.strptime(end_date, date_format)
delta = end_datetime - start_datetime
if delta.total_seconds() <= 0:
raise ValueError("End date must be later than start date.")
random_dates = set()
while len(random_dates) < num_dates:
random_interval = random.randint(0, int(delta.total_seconds()))
random_datetime = start_datetime + timedelta(seconds=random_interval)
# Adjust the hour to fit the 5:00 to 24:00 range
if 0 <= random_datetime.hour < 5:
random_datetime += timedelta(hours=5 - random_datetime.hour)
random_dates.add(random_datetime)
formatted_dates = [date.strftime(date_format) for date in random_dates]
formatted_dates.sort()
return formatted_dates
if __name__ == '__main__':
random_dates = generate_random_dates(start_date="2023/07/13 05:00:00", end_date="2023/07/19 23:59:59", num_dates=100)
# print(len(random_dates))
# lst = []
# for date in random_dates:
# lst.append(date)
# lst.sort()
# pprint(lst)import requests
from bs4 import BeautifulSoup
import ipinfo
def ip_info(ip: str):
access_token = '17ecdae86ed6d3'
handler = ipinfo.getHandler(access_token)
ip_address = ip
details = handler.getDetails(ip_address)
# print(details.city)
d = details.details
return f"{d['ip']}({d['region']}·{d['city']})"
def ip_search(ip: str):
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
url = "https://www.ipshudi.com/{ip}.htm".format(ip=ip)
response = requests.get(url, headers=headers)
# print(response)
# print(response.text)
# print(response.text)
soup = BeautifulSoup(response.text, "lxml")
ip_address = soup.select(".mod-search table tbody tr td span")[1].text
# print(r)
# print(ip_address)
return ip_address
if __name__ == '__main__':
r = ip_info("36.104.38.86")
print(r)
print(f"{r['ip']}({r['region']}·{r['city']})")import random
# 您是否看过梁弄镇明湖村的宣传视频?
def generate_judgment_data_video(n):
watched = ["是"] * int(n * 0.6) # 60%的数据为"是"
not_watched = ["否"] * (n - len(watched)) # 剩下的数据为"否"
judgment_data = watched + not_watched
random.shuffle(judgment_data) # 将数据随机排序
return judgment_data
def generate_trip_decision_data_yanmei(n):
will_go = ["会"] * int(n * 0.3) # 30%的数据为"会"
consider_if_nearby = ["如果是周边地区才会考虑"] * int(n * 0.5) # 50%的数据为"如果是周边地区才会考虑"
# 剩下的数据为"不会"
will_not_go = ["不会"] * (n - len(will_go) - len(consider_if_nearby))
trip_decision_data = will_go + consider_if_nearby + will_not_go
random.shuffle(trip_decision_data) # 将数据随机排序
return trip_decision_data
def generate_gift_box_data(n):
willing = ["愿意"] * int(n * 0.7) # 70%的数据为"愿意"
not_willing = ["不愿意"] * (n - len(willing)) # 剩下的数据为"不愿意"
gift_box_data = willing + not_willing
random.shuffle(gift_box_data) # 将数据随机排序
return gift_box_data
def generate_wenchuang_data(n):
willing = ["会"] * int(n * 0.8) # 70%的数据为"会"
not_willing = ["不会"] * (n - len(willing)) # 剩下的数据为"不会"
wenchuang_data = willing + not_willing
random.shuffle(wenchuang_data) # 将数据随机排序
return wenchuang_data
def generate_minsu_data(n):
willing = ["愿意"] * int(n * 0.8)
not_willing = ["不愿意"] * (n - len(willing)) # 剩下的数据为"不愿意"
minsu_data = willing + not_willing
random.shuffle(minsu_data) # 将数据随机排序
return minsu_data
def generate_tourist_activities():
activities = ["水果采摘", "山腰处帐篷民宿", "网红打卡点", "山地越野车", "青团等当地特色小吃", "徒步远足",
"情景剧本杀"]
# 随机选择的活动数量
num_activities = random.randint(1, len(activities))
# 随机选择活动
selected_activities = random.sample(activities, num_activities)
# 将活动组合成一个字符串
itinerary = '┋'.join(selected_activities)
return itinerary
if __name__ == '__main__':
judgment_vide = generate_judgment_data_video(100)
print(judgment_vide)
judgment_yanmei = generate_trip_decision_data_yanmei(100)
print(judgment_yanmei)
gift_box = generate_gift_box_data(100)
print(gift_box)
wenchuang_data = generate_wenchuang_data(100)
print(wenchuang_data)
minsu_data = generate_minsu_data(100)
print(minsu_data)183.128.0.0 183.159.255.255 2097152
36.96.0.0 36.127.255.255 2097152
115.192.0.0 115.223.255.255 2097152
125.112.0.0 125.127.255.255 1048576
115.224.0.0 115.239.255.255 1048576
36.16.0.0 36.31.255.255 1048576
60.176.0.0 60.191.255.255 1048576
122.240.0.0 122.247.255.255 524288
123.152.0.0 123.159.255.255 524288
125.104.0.0 125.111.255.255 524288
101.64.0.0 101.71.255.255 524288
218.72.0.0 218.75.255.255 262144
210.32.0.0 210.35.255.255 262144
42.120.0.0 42.121.255.255 131072
58.100.0.0 58.101.255.255 131072
124.90.0.0 124.91.255.255 131072
113.214.0.0 113.215.255.255 131072
123.96.0.0 123.97.255.255 131072
211.140.0.0 211.141.255.255 131072
60.162.0.0 60.163.255.255 131072
124.160.0.0 124.160.255.255 65536
123.137.0.0 123.137.255.255 65536
219.82.0.0 219.82.255.255 65536
125.210.0.0 125.210.255.255 65536
182.92.0.0 182.92.255.255 65536
221.136.0.0 221.136.255.255 65536
218.108.0.0 218.108.255.255 65536
61.164.0.0 61.164.255.255 65536
122.9.0.0 122.9.255.255 65536
121.192.0.0 121.192.255.255 65536
60.55.0.0 60.55.255.255 65536
110.75.0.0 110.75.127.255 32768
119.38.0.0 119.38.127.255 32768
124.89.128.0 124.89.255.255 32768
221.12.0.0 221.12.127.255 32768
221.12.128.0 221.12.191.255 16384
116.251.64.0 116.251.127.255 16384
110.75.192.0 110.75.255.255 16384
203.175.192.0 203.175.255.255 16384
119.37.192.0 119.37.255.255 16384
210.15.0.0 210.15.31.255 8192
202.91.224.0 202.91.255.255 8192
121.52.224.0 121.52.255.255 8192
110.75.160.0 110.75.191.255 8192
202.75.208.0 202.75.223.255 4096
202.96.112.0 202.96.127.255 4096
121.0.16.0 121.0.31.255 4096
115.124.16.0 115.124.31.255 4096
119.38.208.0 119.38.223.255 4096
202.96.96.0 202.96.103.255 2048
202.96.104.0 202.96.111.255 2048
103.5.36.0 103.5.39.255 1024
103.3.112.0 103.3.115.255 1024
103.246.124.0 103.246.127.255 1024
103.22.52.0 103.22.55.255 1024
203.93.140.0 203.93.140.255 256def generate_ip_range(start_ip, end_ip):
start = list(map(int, start_ip.split('.')))
end = list(map(int, end_ip.split('.')))
ip_range = []
while start <= end:
ip = '.'.join(map(str, start))
ip_range.append(ip)
start[3] += 1
for i in range(3, 0, -1):
if start[i] == 256:
start[i] = 0
start[i - 1] += 1
return ip_range
def generate_list(ip_ranges):
ip_list = []
for start_ip, end_ip, count in ip_ranges:
ips = generate_ip_range(start_ip, end_ip)
ip_list.extend(ips[:int(count)])
return ip_list
# ip_ranges = [
# ("183.128.0.0", "183.159.255.255", 3),
# # ("36.96.0.0", "36.127.255.255", 3),
# ("115.192.0.0", "115.223.255.255", 3),
# # # ... (将所有IP范围添加到此列表中)
# ("203.93.140.0", "203.93.140.255", 3)
# ]
# r = generate_list(ip_ranges)
# print(r)
# 打印IP列表
# for idnex, ip in enumerate(ip_list):
# print(ip)
# ip_search(ip)
# print(f"{ip}({ip_search(ip)})")import random
from ip_engin import ip_search
from ip_generate_list import generate_list
with open("ip.txt", "r") as f:
lines = f.readlines()
results = []
for line in lines:
results.append(tuple(line.strip().split()))
# print(results)
ips = generate_list(results)
# print(r)
random.shuffle(ips)
random.shuffle(ips)
random.shuffle(ips)
random.shuffle(ips)
f = open("ip_list.txt", "a+")
for i in ips:
# print(f"{i}({ip_search(i)})")
# f.write(f"{i}({ip_search(i)})\n")
f.write(str(i) + "\n")
f.close()
# with open("ip_list.txt", "w") as f:
# lines = line欢迎关注我公众号:AI悦创,有更多更好玩的等你发现!
公众号:AI悦创【二维码】

AI悦创·编程一对一
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++ 辅导班、java 辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发、Linux、Web 全栈」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。当然,还有线下线上摄影课程、Photoshop、Premiere 一对一教学、QQ、微信在线,随时响应!微信:Jiabcdefh
C++ 信息奥赛题解,长期更新!长期招收一对一中小学信息奥赛集训,莆田、厦门地区有机会线下上门,其他地区线上。微信:Jiabcdefh
方法一:QQ
方法二:微信:Jiabcdefh

更新日志
7754e-于1c35a-于aed17-于6c139-于da959-于86f2b-于843a7-于fc6a8-于943c4-于e50a1-于dab27-于82111-于574dd-于03a9c-于56015-于a85d7-于c74fe-于14c00-于4f0ff-于9ffac-于7f698-于1ac90-于4a069-于b1407-于22811-于269da-于56ca0-于458c6-于c9d9d-于4a93e-于62917-于d2f64-于cbb3a-于610fe-于f08aa-于76989-于86c50-于027da-于