02-列表内容补充
1. 列表的深浅拷贝
点击展开阅读
1. y = x 所存在的问题,是真的备份吗?
阅读下面的代码,思考下面两个问题:
- 问题1:这段代码的意图是什么?开发者希望实现什么效果?
- 问题2:代码的输出结果是什么?是否符合预期?
注意: 下面的代码我是有意写这么长的字符串,有两个目的:
- 目的一:为了带你回顾一个字符串格式化、转义的用法!
- 目的二:方便我们后续观察找出问题;
x = ['毒药', '感冒药', '解药']
y = x
print(f'Original:\n\tx: {x}\n\ty: {y}\n\tid_x: {id(x)}\tid_y: {id(y)}') # id() 用来获取变量的物理地址
y[0] = '消炎药'
print(f'After:\n\tx: {x}\n\ty: {y}\n\tid_x: {id(x)}\tid_y: {id(y)}')阅读到此,想必你有了你自己的思考。我们现在来看看,我对于上面两个问题的回答。
1.1 问题1
从代码 y = x 可知,开发者想要复制一个 x 列表的副本给变量 y 并且想要修改列表 y 时不影响原列表 x。换句话说,y 应该是 x 的一个独立备份。
为什么我们会有这种需求?让我们结合现实场景来思考。
假设你有一个包含 100万条数据的 Excel 文件,为下载这个数据文件获取这个文件的代价极高:
- 你需要花费1000元;
- 下载耗费3个小时;
- 并且1000元只能下载一次,数据丢失想要重新下载需要重新付费;
注意:这里我是特意这么夸张,请不要想其它的。我只是为了让你尽可能感觉到这个数据是多么昂贵的,并且获取这个数据所要付出的代价是巨大的,因为只有昂贵才会重视,便于我塑造情景。
这里再次强调:如果再下载一次还是需要 1000元、下载耗费3个小时、并且还是只能下载一次。此时你要操作这个拥有 100万数据且下载成本极高的 Excel 会怎么操作?
阅读到此时,请停顿一下。思考一下,在这种情况下,你会怎么做?
毫无疑问,肯定是在操作前做一个备份,以便在操作时:如果不小心手贱按错按键,或者破电脑突然卡住导致你操作的数据没有及时保存或关闭等情况,导致数据缺失或损坏。此时就需要使用备份文件来恢复,这样就避免重新获取数据而产生的高额代价。所以在上面的代码中也是这样的意图,列表 x 作为备份数据,以确保对 y 的修改不会影响到原始数据 x,以此保证原数据不被影响。
1.2 问题2
对于问题2请先观察下面的代码实际输出,看看输出结果中存在什么问题和特点?
注意:观察下面的代码时你要具备一个原则:有时候,不要只看局部。站的高点,站的远点,使我们有全局视角,这样往往更便于我们发现事物中所存在的关联关系或规律。
意思就是:你在观察下面的输出结果时,不要单纯的一行一行看,或者看完下一行忘记上一行。要把自己从中抽离出来,看整个输出。去及时的观察和对比,这样才能发现其中的规律或者存在的问题。
Original:
x: ['毒药', '感冒药', '解药']
y: ['毒药', '感冒药', '解药']
id_x: 4470743680 id_y:4470743680
After:
x: ['消炎药', '感冒药', '解药']
y: ['消炎药', '感冒药', '解药']
id_x: 4470743680 id_y:4470743680我们会发现,当我们修改 y 列表中的第一个元素后,x 列表的内容也发生了变化,这显然不符合我们的预期。理论上,我们的目标是 仅修改 y,不影响 x,但结果表明 x 和 y 竟然是同一个列表!
为什么会产生这个问题情况呢?我们可以从 id() 函数的输出中找到答案。
从上面的输出结果可知:列表 x 和列表 y 的物理地址是相同的,意味着虽然做了备份(y = x),但没想到列表 x 和 y 是指向同一个列表,故而导致修改列表 y 时,列表 x 的数据也被修改。与我们原本的意图(备份)事与愿违,并且产生了“巨大”代价!明显我们的代码不符合预期。
从上面的分析后,我们可知 y = x 只是进行了列表地址的赋值(类似引用),x、y 实际上指向的是同一个列表。可以理解成两个列表元素一样,Python 就偷懒不再创建一个新的相同列表,直接创建一个地址引用。
为了更直观地理解这个问题,我们可以借助一个现实生活中的类比:
- 假设你在百度网盘中 已经上传了一个文件,然后你又想要“上传”相同的文件。
- 但百度网盘发现,这个文件已经存在,它 不会真正再上传一次,而是 直接在你的账户中创建一个链接,指向已经存在的文件。
- 这样,你看到自己网盘中有两个相同的文件,但实际上它们 指向的是同一个数据,修改其中一个,另一个也会随之变化。
Python 在 y = x 赋值时的行为类似于百度网盘的“创建链接”机制:并没有真正复制列表,而只是让 y 指向了 x,所以 x 和 y 变成了 同一个对象的两个引用。
1.3 归整一下
上面分析了一下,接下来我来给你归整归整。我们说列表 x 和列表 y 指向的是同一个变量,我们口说无凭,来看看下面的凭证:
证明一:Python
id()用来检查变量物理地址(也就是在计算机中,所在的位置)并结合上面的代码结果可知:x、y 指向的是同一个列表,因为 id 相同。(id_x: 4470743680、id_y:4470743680)证明二:可以直接使用可视化:https://pythontutor.bornforthis.cn/visualize.html#mode=edit查看,毕竟一图胜千言。在可视化界面中(下图),你会发现
x和y其实是 同一个列表对象的两个名称,本质上它们没有区别。因此,修改y也会影响x,这就是问题的根本原因。
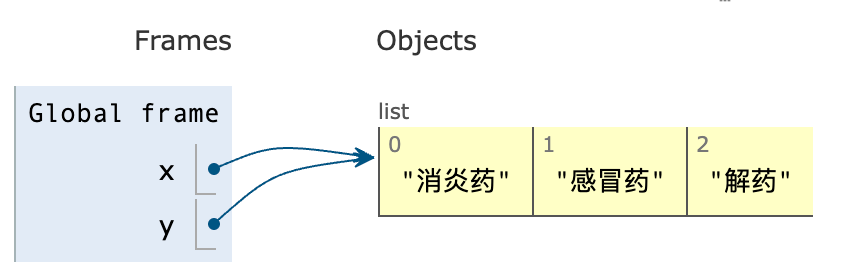
有时候,不要只看局部。站的高点,站的远点,使我们有全局视角,这样往往更便于我们发现事物中所存在的关联关系或规律。——AI悦创 2024-01-01 23:17:10
1.4 关键问题:如何正确创建副本?
既然 y = x 不能满足我们“创建副本”的需求,那么 如何正确地复制一个列表,而不影响原列表呢?
别担心,我们接下来就会深入探讨 Python 中的深拷贝与浅拷贝,以及 如何避免此类问题。
2. 使用 copy() 进行浅拷贝
2.1 代码实现
在前面的内容中,我们发现 直接赋值 y = x 并不会创建一个新的列表,而只是让 y 指向 x,导致修改 y 的同时 x 也会被修改。这显然不符合我们的备份需求。
那么,如何正确创建一个新的副本,确保 y 和 x 互不影响呢?为了解决这个问题,我们可以使用列表自带的 copy() 方法,这会创建一个“浅拷贝”(shallow copy),从而获得一个独立的对象副本。
让我们看看使用 copy() 进行列表复制的效果:
x = ['毒药', '感冒药', '解药']
y = x.copy()
print(f'Original:\n\tx: {x}\n\ty: {y}\n\tid_x: {id(x)}\tid_y:{id(y)}') # id 用来获取变量的物理地址
y[0] = '消炎药'
print(f'After:\n\tx: {x}\n\ty: {y}\n\tid_x: {id(x)}\tid_y:{id(y)}')代码输出如下:
Original:
x: ['毒药', '感冒药', '解药']
y: ['毒药', '感冒药', '解药']
id_x: 4428223616 id_y:4428537536
After:
x: ['毒药', '感冒药', '解药']
y: ['消炎药', '感冒药', '解药']
id_x: 4428223616 id_y:44285375362.2 结果分析
从输出结果来看,我们可以发现两个重要的现象:
id_x和id_y变了:初始状态下,x和y的内容完全相同,但物理地址(id_x和id_y)已经 不再相同,这表示copy()方法为y创建了一个全新的列表对象。y和x现在是两个独立的对象,互不影响。- 修改
y后,x没有被影响:之前y = x时,修改y[0]为'消炎药'时会影响x[0],但现在y已经是x的一个独立副本,因此修改y不会影响x,这正是我们想要的备份效果。
2.3 为什么说是“浅拷贝”?
copy() 方法在 Python 中执行的是 浅拷贝(Shallow Copy)。它的本质是 创建一个新的列表对象,并将原列表中的元素引用复制到新列表中。简单来说:
copy()复制了列表本身,即创建了一个新的y。- 但 它并不会复制列表中的元素,而是让
y里的元素仍然指向x里的同样的元素。如果列表中包含可变的嵌套对象(如列表里还有列表、元组、字典等),这些 子对象依旧是原来对象的引用。也就是说,对同一层级的数据做了拷贝,但 更深层次 的数据结构还会被引用到原对象。 - 对于目前这种 单层列表,我们可以把
.copy()当作和“深拷贝”一样使用,但是前提是:列表的元素都是字符串、数字型、布尔型等不可变数据类型,并没有深层的嵌套结构,自然也就不会出现意料之外的相互影响。
这可能有点绕,我们可以用下面的图示帮助理解:
原列表 x:
x ---> ['毒药', '感冒药', '解药']
↑ ↑ ↑
新列表 y: | | |
y ---> ['毒药', '感冒药', '解药']可以看到,x 和 y 是两个不同的列表对象(id() 值不同),但它们里面的元素其实是 指向同一个数据的引用。
2.4 copy() 的适用场景
✅ 适用于:
复制一个一维列表,确保y是x的副本,修改y不会影响x。- 对于普通的、一维的或者元素不可变的列表,使用
x.copy()(或x[:])就足够解决“大部分”复制需求。
❌ 不适用于:
- 复制嵌套列表(二维或多维列表)。因为
copy()仅复制了外层列表,如果列表内部还包含可变对象(如子列表),这些子列表仍然是共享的,即修改y内部的子列表仍然会影响x。
3. copy() 的局限性:浅拷贝的陷阱
在前面的讲解中,我们为列表 x 创建了一个副本,从而避免了修改 y 时影响 x 的情况。然而,这里又引出了一个新的问题:为什么在有些情况下,修改 y 仍旧会影响到 x?请先阅读下面的代码,并思考它在做什么,最终产生了怎样的结果,这个结果是否出乎你的意料。
x = ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y = x.copy()
print(f'Original:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}') # id 用来获取变量的物理地址
y[0] = '消炎药'
print(f'After 1:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}')
y[3][0] = '苹果'
print(f'After 2:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}')运行结果如下所示:
Original:
x: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
id:
id_x: 5306734464 id_y: 5310717568
id_children x[3]: 4347684800
id_children y[3]: 4347684800
After 1:
x: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y: ['消炎药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
id:
id_x: 5306734464 id_y: 5310717568
id_children x[3]: 4347684800
id_children y[3]: 4347684800
After 2:
x: ['毒药', '感冒药', '解药', ['苹果', '瓜子', '八宝粥']]
y: ['消炎药', '感冒药', '解药', ['苹果', '瓜子', '八宝粥']]
id:
id_x: 5306734464 id_y: 5310717568
id_children x[3]: 4347684800
id_children y[3]: 43476848003.1 解析:为什么 x 也被修改了?
在 After 2 这一步,我们仅修改了 y 中子列表的内容后(y[3][0]),理论上 x 不应该受到影响。但实际结果显示,x 的对应部分也跟着改变了,也就是 x[3][0] 也被修改成了 '苹果',这是因为 .copy() 方法只执行了浅拷贝(shallow copy),它并不会深入到子列表或更深层级的数据结构去创建新的副本,而是让 x 和 y 共享同一个子列表。
浅拷贝的工作机制:
.copy()仅复制了x的 第一层结构,但不会递归地复制内部的嵌套列表。也就是说,
y[3]仍然指向x[3]的 同一个对象,它们共享相同的内存地址。这可以通过id(x[3]) == id(y[3])来验证,两者的内存地址完全一致。
可以从以下两个方面来验证这一点:
- 子列表 ID 相同:输出中可见
x[3]和y[3]的id完全一致,这说明它们实际上引用的是同一个对象(子列表)。你还可以为上面的代码添加一行代码来更直观的验证:print(id(x[3]) == id(y[3]))。 - 可视化关系相同:若从可视化角度来观察,可以看到
x和y在最外层各自拥有不同的地址,但它们第三个索引位置(子列表)都指向同一个存储空间。还是使用:https://pythontutor.bornforthis.cn/visualize.html#mode=edit,图示如下:
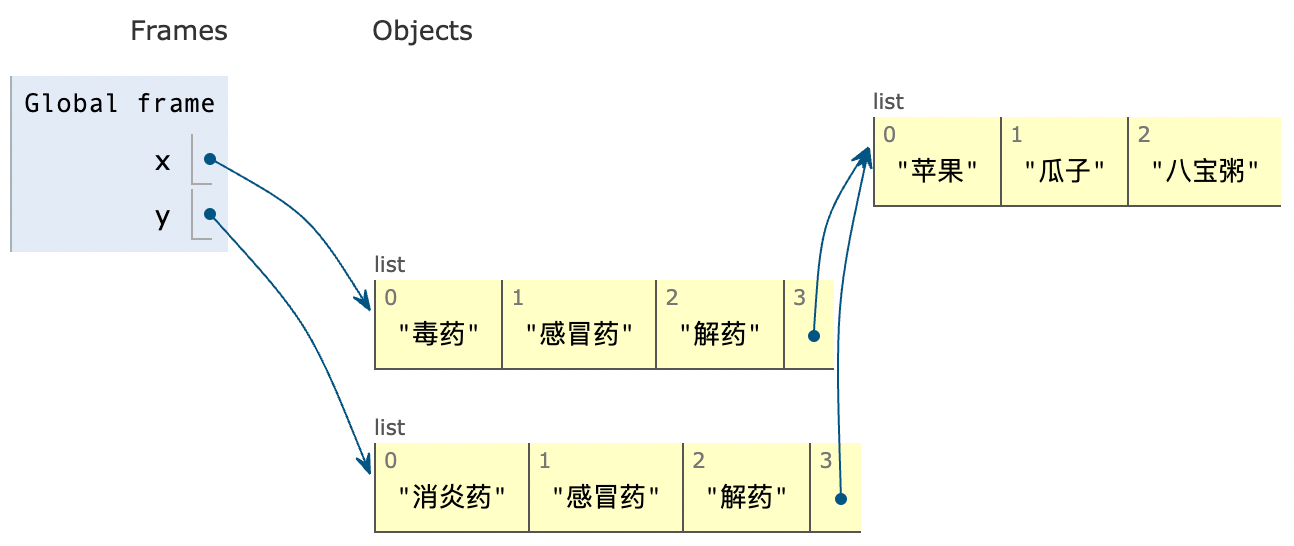
如果想要彻底独立的副本(包括子列表也要复制),就需要使用 深拷贝(deep copy)
所以,copy 实现的是浅拷贝,只拷贝列表的第一层,嵌套的列表则不会拷贝。
因此,如果你希望获得完全独立的副本(包括子列表和其他更深层的嵌套对象都相互独立),则需要使用深拷贝(deep copy)。
4. deepcopy():如何彻底复制列表?
使用深拷贝需要导入库:
为了使用深拷贝功能,首先需要导入 copy 模块中的 deepcopy 函数:
from copy import deepcopy下面用一个示例演示深拷贝的效果:
from copy import deepcopy
x = ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y = deepcopy(x)
print(f'Original:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\n\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}') # id 用来获取变量的物理地址
y[0] = '消炎药'
print(f'After 1:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\n\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}')
y[3][0] = '苹果'
print(f'After 2:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\n\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}')示例输出如下:
Original:
x: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
id:
id_x: 4408501568
id_y: 4408501056
id_children x[3]: 4408175296
id_children y[3]: 4408501312
After 1:
x: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y: ['消炎药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
id:
id_x: 4408501568
id_y: 4408501056
id_children x[3]: 4408175296
id_children y[3]: 4408501312
After 2:
x: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y: ['消炎药', '感冒药', '解药', ['苹果', '瓜子', '八宝粥']]
id:
id_x: 4408501568
id_y: 4408501056
id_children x[3]: 4408175296
id_children y[3]: 44085013124.1 解析:为什么 deepcopy() 解决了问题?
deepcopy()会递归地复制整个数据结构,而不仅仅是第一层。x[3]和y[3]现在是两个不同的列表,修改y[3]不会影响x[3]。
如何证明上面的结论呢?依然使用的是两种方法:
- 方法一:子列表的
id值已经不同,说明x和y中的子列表各自拥有独立的内存空间。你还可以基于上面的代码,通过添加print(id(x[3]) != id(y[3]))得到 False 可以验证,它们的 ID 已经不同。id 即代表物理地址,物理地址不同则不是同一个数据。 - 可视化层面也可以看出,被拷贝的多层嵌套结构完全分离,互不影响,一图胜千言:
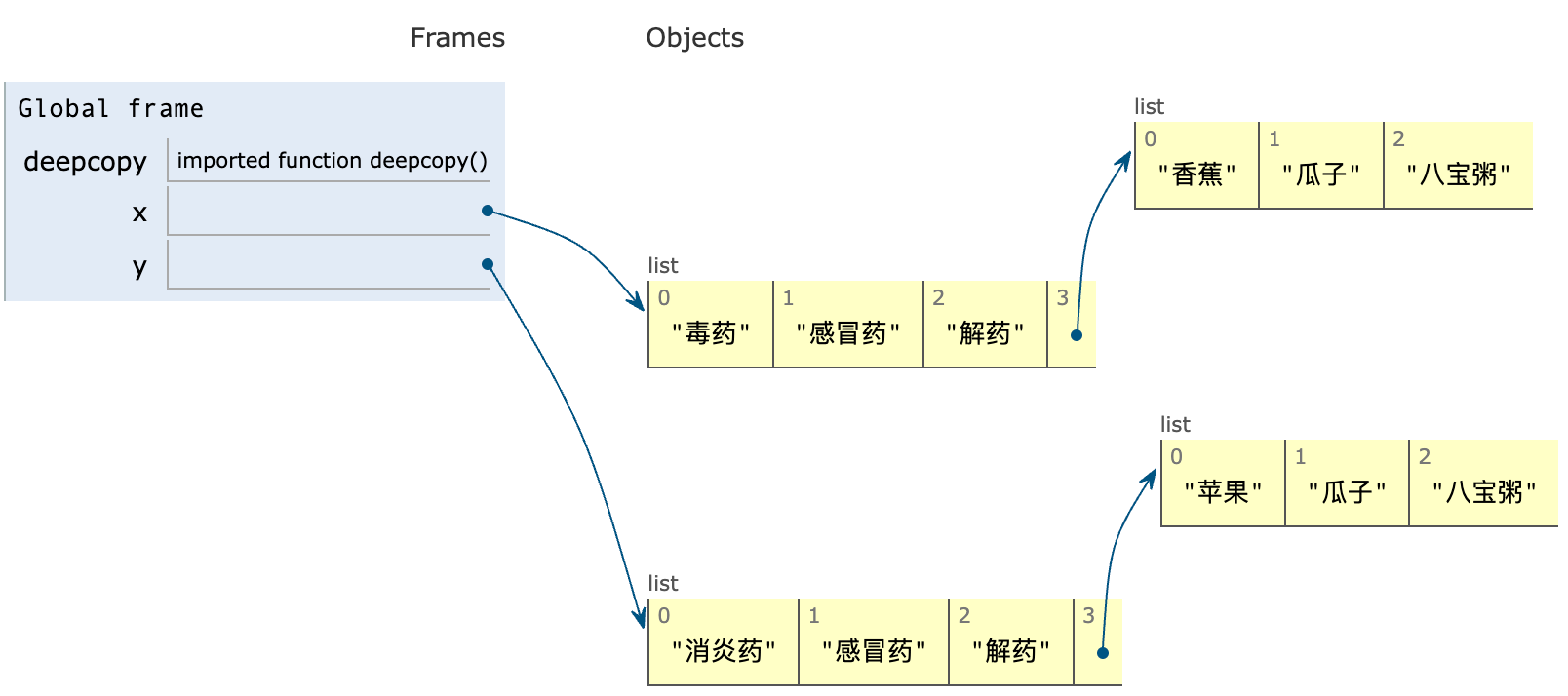
使用的网站依然是:https://pythontutor.bornforthis.cn/visualize.html#mode=edit
5. 一个特殊情况:浅拷贝时不会影响原数据的情况
虽然前面提到浅拷贝不会递归复制子列表(子列表没有完全 copy 出来),导致修改 y 时也会影响到 x,但在某些特定情况下,浅拷贝的改动并不会影响原列表,也就是修改列表 y 是不会影响列表 x。
请先思考一下:
我们上面说了列表的深浅拷贝,但是浅拷贝的时候,虽然子列表没有完全 copy 出来,但是有一种情况下修改列表 y 是不会影响列表 x。是不会互相影响。
所以,接下来依然是思考一下🤔:也就是说,在浅拷贝的代码中,什么情况下修改子列表不会互相影响。在浅拷贝的代码示例中,在哪种情形下我们修改了 “子列表” 却不影响另外一个列表?
下面我也提供了浅拷贝代码,请认真激发你的有效思考:
x = ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y = x.copy()
print(f'Original:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}') # id 用来获取变量的物理地址
y[0] = '消炎药'
print(f'After 1:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}')
y[3][0] = '苹果'
print(f'After 2:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}')既然,我们修改引用的子列表会互相影响。那我们大胆一点想一想,直接把整个列表修改了,是不是就不会互相影响了呢?下面这段代码提供了线索。请对比与前面代码的差异之处,并观察最终输出:
x = ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y = x.copy()
print(f'Original:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}') # id 用来获取变量的物理地址
y[0] = '消炎药'
print(f'After 1:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}')
# y[3][0] = '苹果'
y[3] = 'www.bornforthis.cn'
print(f'After 2:\n\tx: {x}\n\ty: {y}\n\tid:\n\t\tid_x: {id(x)}\t\tid_y: {id(y)}\n\t\tid_children x[3]: {id(x[3])}\n\t\tid_children y[3]: {id(y[3])}')运行结果如下:
Original:
x: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
id:
id_x: 4412075712 id_y: 5778383360
id_children x[3]: 4349618112
id_children y[3]: 4349618112
After 1:
x: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y: ['消炎药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
id:
id_x: 4412075712 id_y: 5778383360
id_children x[3]: 4349618112
id_children y[3]: 4349618112
After 2:
x: ['毒药', '感冒药', '解药', ['香蕉', '瓜子', '八宝粥']]
y: ['消炎药', '感冒药', '解药', 'www.bornforthis.cn']
id:
id_x: 4412075712 id_y: 5778383360
id_children x[3]: 4349618112
id_children y[3]: 4698471152从上面的输出可以得知,当直接把 y[3] 替换成一个新的字符串('www.bornforthis.cn')时,x 中并不会受到影响,因为此时我们并没有去修改原本共享的子列表,而是让 y 指向了一个全新的对象,也意味着 y[3] 指向了一个新的内存地址。
对于 “浅拷贝” 而言,列表 x 的 x[3] 仍然指向原来的列表 ['香蕉', '瓜子', '八宝粥'],并不会受到影响。只要针对某个索引重新赋值为新的对象,原列表对应位置的引用不会跟着变动,自然也就不会再相互影响。
简而言之,浅拷贝只会在“修改同一个嵌套对象本身”时产生联动影响;如果是直接给某个嵌套对象赋予一个新引用,则不会影响到原列表。
通过上面两个示例的对比,我们可以清晰地看到浅拷贝与深拷贝的区别,也了解到在一些特殊操作方式下,浅拷贝的修改并不会波及到原列表。一般而言,如果你只关心最外层结构的复制,且内部嵌套对象可以共享,那么浅拷贝就够用了;而当你需要创建完全独立的副本时,深拷贝才是更合适的选择。
5.1 结论
结论一:
copy()只能进行浅拷贝,嵌套对象不会被复制。结论二:
deepcopy()进行递归复制,完全独立于原对象。结论三:浅拷贝仅在修改嵌套对象时才会导致意外影响,直接替换元素不会影响原列表。
2. 列表的内置函数
点击展开阅读
1. append()
在列表末尾添加元素。
语法:
list.append(item)示例:
my_list = [1, 2, 3]
my_list.append(4)
print(my_list) # [1, 2, 3, 4]2. extend()
在列表末尾添加多个元素(可迭代对象)。
语法:
list.extend(iterable)示例:
my_list = [1, 2, 3]
my_list.extend([4, 5])
print(my_list) # [1, 2, 3, 4, 5]3. insert()
在列表指定索引位置插入元素。
语法:
list.insert(index, item)示例:
my_list = [1, 2, 4]
my_list.insert(2, 3) # 在索引2位置插入元素3
print(my_list) # [1, 2, 3, 4]4. remove()
删除列表中第一个匹配的元素。
语法:
list.remove(item)示例:
my_list = [1, 2, 3, 2]
my_list.remove(2)
print(my_list) # [1, 3, 2]5. pop()
移除并返回列表指定索引位置的元素(默认最后一个元素)。
语法:
list.pop([index])示例:
my_list = [1, 2, 3, 4]
item = my_list.pop() # 默认删除最后一个
print(item) # 4
print(my_list) # [1, 2, 3]
item = my_list.pop(1) # 删除索引为1的元素
print(item) # 2
print(my_list) # [1, 3]6. clear()
清空列表中所有元素。
语法:
list.clear()示例:
my_list = [1, 2, 3]
my_list.clear()
print(my_list) # []7. index()
返回列表中第一个匹配元素的索引。
语法:
list.index(item, start=0, end=len(list))示例:
my_list = [1, 2, 3, 2, 4]
index = my_list.index(2)
print(index) # 1(第一个2的位置)
index = my_list.index(2, 2) # 从索引2开始查找
print(index) # 38. count()
返回列表中某个元素出现的次数。
语法:
list.count(item)示例:
my_list = [1, 2, 2, 3, 2]
count = my_list.count(2)
print(count) # 39. sort()
对列表元素进行原地排序(默认升序)。
语法:
list.sort(key=None, reverse=False)示例:
my_list = [3, 1, 4, 2]
my_list.sort()
print(my_list) # [1, 2, 3, 4]
my_list.sort(reverse=True)
print(my_list) # [4, 3, 2, 1]10. reverse()
原地反转列表元素顺序。
语法:
list.reverse()示例:
my_list = [1, 2, 3, 4]
my_list.reverse()
print(my_list) # [4, 3, 2, 1]11. copy()
返回列表的浅拷贝。
语法:
new_list = list.copy()示例:
my_list = [1, 2, 3]
new_list = my_list.copy()
print(new_list) # [1, 2, 3]
new_list.append(4)
print(my_list) # [1, 2, 3] 原列表不变12. 内置函数:len()
返回列表的元素数量。
语法:
len(list)示例:
my_list = [1, 2, 3, 4]
print(len(my_list)) # 413. 内置函数:max() 与 min()
分别返回列表中最大的和最小的元素。
语法:
max(list)
min(list)示例:
my_list = [1, 4, 2, 3]
print(max(my_list)) # 4
print(min(my_list)) # 114. 内置函数:sum()
返回列表中元素的和。
语法:
sum(list, start=0)示例:
my_list = [1, 2, 3, 4]
total = sum(my_list)
print(total) # 1015. 内置函数:sorted()
返回列表排序后的新列表,不改变原列表。
语法:
sorted(list, key=None, reverse=False)示例:
my_list = [3, 1, 4, 2]
new_list = sorted(my_list)
print(new_list) # [1, 2, 3, 4]
print(my_list) # [3, 1, 4, 2] 原列表不变16. del 关键字(删除元素)
删除列表中的元素(可删除单个或多个元素)。
示例:
my_list = [1, 2, 3, 4, 5]
# 删除单个元素
del my_list[2]
print(my_list) # [1, 2, 4, 5]
# 删除多个元素
del my_list[1:3]
print(my_list) # [1, 5]17. 列表切片(slice)
从列表获取一段连续的元素。
语法:
list[start:end:step]示例:
my_list = [0, 1, 2, 3, 4, 5, 6]
# 获取索引1到4的元素
print(my_list[1:5]) # [1, 2, 3, 4]
# 每隔两个元素取一个
print(my_list[::2]) # [0, 2, 4, 6]
# 逆序切片
print(my_list[::-1]) # [6, 5, 4, 3, 2, 1, 0]18. 成员检测(in / not in)
检查元素是否存在列表中。
示例:
my_list = ['apple', 'banana', 'cherry']
print('banana' in my_list) # True
print('orange' not in my_list) # True19. 列表连接 (+)
合并两个列表为新列表。
示例:
list1 = [1, 2, 3]
list2 = [4, 5, 6]
combined = list1 + list2
print(combined) # [1, 2, 3, 4, 5, 6]20. 列表重复 (*)
重复列表元素若干次。
示例:
my_list = [1, 2]
print(my_list * 3) # [1, 2, 1, 2, 1, 2]21. enumerate() 枚举函数(常用)
枚举列表中元素及其索引。
示例:
my_list = ['a', 'b', 'c']
for index, item in enumerate(my_list):
print(index, item)
# 输出:
# 0 a
# 1 b
# 2 c22. zip() 函数(常用)
同时遍历多个列表。
示例:
names = ['Alice', 'Bob', 'Cindy']
scores = [90, 85, 95]
for name, score in zip(names, scores):
print(name, score)
# 输出:
# Alice 90
# Bob 85
# Cindy 9523. map() 函数
将函数应用于列表每个元素,返回可迭代对象。
示例:
numbers = [1, 2, 3, 4]
squared = list(map(lambda x: x**2, numbers))
print(squared) # [1, 4, 9, 16]24. filter() 函数
过滤列表中的元素。
示例:
numbers = [1, 2, 3, 4, 5]
even = list(filter(lambda x: x % 2 == 0, numbers))
print(even) # [2, 4]25. 列表推导式 (List Comprehension)
简洁地创建新列表。
示例:
# 基本形式
squares = [x**2 for x in range(5)]
print(squares) # [0, 1, 4, 9, 16]
# 条件过滤
even_squares = [x**2 for x in range(10) if x % 2 == 0]
print(even_squares) # [0, 4, 16, 36, 64]26. 嵌套列表(列表套列表)
列表可以嵌套列表来创建多维数据。
示例:
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
print(matrix[0][1]) # 227. any() 和 all() 函数
判断列表元素中是否有真值(any),或者所有元素都是真值(all)。
示例:
lst1 = [0, '', False]
lst2 = [0, 'Python', False]
print(any(lst1)) # False
print(any(lst2)) # True
print(all([1, 2, 3])) # True
print(all([1, 0, 3])) # False28. join() 方法(针对字符型列表)
将列表的元素连接成字符串。
示例:
words = ['hello', 'world', 'Python']
sentence = ' '.join(words)
print(sentence) # hello world Python29. reduce() 函数(在 functools 库中)
累积计算列表元素。
示例:
from functools import reduce
numbers = [1, 2, 3, 4]
product = reduce(lambda x, y: x * y, numbers)
print(product) # 2430. 深拷贝与浅拷贝
- 浅拷贝:
list.copy()或list[:] - 深拷贝:使用
copy.deepcopy()
示例:
import copy
original = [[1, 2], [3, 4]]
shallow_copy = original[:]
deep_copy = copy.deepcopy(original)
original[0][0] = 'Changed'
print(original) # [['Changed', 2], [3, 4]]
print(shallow_copy) # [['Changed', 2], [3, 4]] 浅拷贝会受影响
print(deep_copy) # [[1, 2], [3, 4]] 深拷贝不受影响31. 常用方法和函数速览表
| 序号 | 内置函数名称或操作 | 功能说明 | 使用代码示例 |
|---|---|---|---|
| 1 | append() | 列表末尾追加单个元素 | lst.append(10) |
| 2 | extend() | 列表末尾追加多个元素 | lst.extend([1,2,3]) |
| 3 | insert() | 在指定位置插入元素 | lst.insert(1, 'x') |
| 4 | remove() | 删除首次出现的指定元素 | lst.remove('x') |
| 5 | pop() | 删除并返回指定位置元素(默认末尾) | item = lst.pop(0) |
| 6 | clear() | 清空列表所有元素 | lst.clear() |
| 7 | index() | 返回首次出现的元素位置 | lst.index(5) |
| 8 | count() | 元素出现的次数 | lst.count(5) |
| 9 | sort() | 原地排序(默认升序) | lst.sort() |
| 10 | reverse() | 原地反转列表 | lst.reverse() |
| 11 | copy() | 浅拷贝列表 | new_lst = lst.copy() |
| 12 | len() | 列表长度 | len(lst) |
| 13 | max() | 列表最大元素 | max(lst) |
| 14 | min() | 列表最小元素 | min(lst) |
| 15 | sum() | 列表元素求和 | sum(lst) |
| 16 | sorted() | 排序并返回新列表 | new_lst = sorted(lst) |
| 17 | enumerate() | 枚举索引和元素 | for i,v in enumerate(lst): |
| 18 | zip() | 同时迭代多个列表 | for x,y in zip(lst1,lst2): |
| 19 | map() | 将函数应用于列表元素 | list(map(str, lst)) |
| 20 | filter() | 过滤元素 | list(filter(lambda x:x>0, lst)) |
| 21 | 列表推导式 | 简洁创建新列表 | [x*2 for x in lst] |
| 22 | 切片(slice) | 提取子序列 | lst[2:5] |
| 23 | 成员检测 (in/not in) | 检测元素是否存在 | 1 in lst |
| 24 | 列表拼接 (+) | 拼接列表 | lst1 + lst2 |
| 25 | 列表重复 (*) | 重复列表元素 | lst * 3 |
| 26 | any() | 是否存在真值元素 | any(lst) |
| 27 | all() | 是否所有元素都是真值 | all(lst) |
| 28 | del | 删除元素或切片 | del lst[1:3] |
| 29 | 深拷贝 (copy.deepcopy) | 深拷贝嵌套列表 | copy.deepcopy(lst) |
| 30 | reduce()(functools库) | 元素累积运算 | reduce(lambda x,y:x+y, lst) |
| 31 | join()(元素为字符串时) | 列表元素拼接成字符串 | ' '.join(['a','b']) |
掌握上述方法和函数后,Python 列表的常用操作将非常熟练,编程效率也能大大提高。